
- PagerDuty /
- Blog /
- Non classé /
- Tests de chef chez PagerDuty
Blog
Tests de chef chez PagerDuty
par Ranjib Dey
14 novembre 2013 | 5 min de lecture
 Chez PagerDuty, toute notre infrastructure informatique est automatisée grâce à Chef. Nous déployons très fréquemment de nouvelles fonctionnalités et des modifications dans notre code Chef – souvent plusieurs fois par jour – ce qui rend crucial le test de ce code avant son déploiement en production. Comme nous l'avons constaté, des défaillances peuvent survenir en raison de dépendances non gelées, de valeurs incorrectes dans le fichier de configuration, d'erreurs de logique, de bogues dans les bibliothèques sous-jacentes, etc.
Chez PagerDuty, toute notre infrastructure informatique est automatisée grâce à Chef. Nous déployons très fréquemment de nouvelles fonctionnalités et des modifications dans notre code Chef – souvent plusieurs fois par jour – ce qui rend crucial le test de ce code avant son déploiement en production. Comme nous l'avons constaté, des défaillances peuvent survenir en raison de dépendances non gelées, de valeurs incorrectes dans le fichier de configuration, d'erreurs de logique, de bogues dans les bibliothèques sous-jacentes, etc.
Dans cet article, nous allons passer en revue les 5 outils/stratégies de tests séquentiels que nous utilisons pour créer une infrastructure prévisible et stable.
- Tests sémantiques Dans notre pipeline d'intégration continue (CI), la première étape consiste à exécuter Foodcritic, un outil d'analyse statique de code qui vérifie la présence d'erreurs sémantiques dans notre code Chef. Ce test est rapide et permet un contrôle qualité uniforme. En cas d'échec, l'exécution est immédiatement interrompue. Actuellement, Foodcritic est exécuté uniquement sur nos cookbooks (le répertoire vendor de Berkshelf est exclu).
- Tests unitaires La deuxième étape consiste à exécuter des tests unitaires via ChefSpec. Nous avons une couverture minimale (c'est-à-dire que nous vérifions au moins si le nœud converge) pour toutes les recettes, et une couverture exhaustive pour celles spécifiques à PagerDuty. Nous avons récemment migré vers ChefSpec 3 (un petit coucou à Seth Vargo Pour la réécriture, nous utilisons ChefSpec, qui offre des assertions chaînables, des matchers personnalisés et de nombreuses autres améliorations. Pour certains cookbooks essentiels (comme iptables), nous avons des matchers personnalisés pour les LWRP de ces mêmes cookbooks. En général, nous veillons à ce que nos recettes spécifiques à PagerDuty et nos LWRP soient concises, et nous utilisons une bibliothèque qui intègre la majeure partie de la logique. Les bibliothèques sont testées avec RSpec. Nous vérifions généralement les dépendances supposées (par exemple, la spécification de pd-apache vérifiera la présence de « service['apache'] ») à partir des cookbooks de la communauté. Grâce à la gestion détaillée de la priorité des attributs proposée par Chef, il peut être très difficile de prédire quel attribut sera finalement utilisé ; ChefSpec offre une sécurité à ce sujet. Les tests unitaires nous permettent également d'implémenter en toute sécurité les modes d'exécution de nos LWRP personnalisés. Cela s'est avéré extrêmement utile lors de la refactorisation de composants critiques. Nous comprenons désormais mieux les dépendances réseau que nous introduisons avec chaque appel de recherche.
- Tests fonctionnels – Nous disposons d'une suite de tests fonctionnels très réduite, mais encore à ses débuts, qui couvre actuellement environ 80 % de notre infrastructure. Pour chacun de ces tests, nous appliquons les éléments de la liste d'exécution de niveau supérieur (c'est-à-dire les rôles directement attribués aux nœuds) à un conteneur Linux de la même plateforme et de la même version (nous utilisons Ubuntu). suite de tests fonctionnels crée un serveur Chef en mémoire (un petit coucou à John Keiser ), télécharge toutes les données via notre script de restauration Le conteneur est créé, puis un bootstrap basé sur Knife est effectué à l'aide de notre modèle. Cette opération exécute tous nos cookbooks, rôles et environnements. Nous utilisons un gestionnaire personnalisé qui stocke le nombre de ressources et d'autres statistiques en tant qu'attributs de nœud. Nous invoquons Chef deux fois et utilisons ces attributs de métriques pour vérifier le nombre de ressources non idempotentes. Nous en avons actuellement quelques-unes, et notre objectif est de les éliminer. Certains tests fonctionnels consistent également à restaurer les données de l'environnement de préproduction et à y faire converger les conteneurs. Cela nous permet de simuler une convergence réelle, similaire à celle de la production ou de la préproduction, et de vérifier la robustesse des configurations impliquant de nombreuses recherches. Toutes nos intégrations tierces (par exemple, DataDog et Sumologic Les tests sont effectués dans le cadre de cette étape. Cela nous permet également d'obtenir un retour d'information plus fréquent sur les performances des API externes, car nos serveurs de production les utilisent également. Après les assertions, le conteneur est nettoyé, ce qui nous permet de tester toutes nos étapes de nettoyage externes (via knife) et internes (via chef-recipe) (par exemple, la désinscription des services externes ou la suppression DNS). Nous utilisons une configuration standard. rubis-lxc Nous utilisons des liaisons et RSpec pour tester l'ensemble. Bien que les tests fonctionnels soient encore exécutés localement, notre objectif final est de les intégrer à Jenkins.
- Tests d'intégration Nous disposons de deux environnements principaux où tout notre code Chef est testé en parallèle avec le code de l'application. Nous avons un environnement de préproduction générique où les fonctionnalités sont déployées et testées en continu. Le second environnement est dédié aux tests de charge de ces fonctionnalités. Ces deux environnements sont logiquement indépendants, mais partagent certains services (par exemple, un compte AWS ou un serveur Chef).
- Vendredi de l'échec En plus de tous ces tests logiciels, nous simulons des pannes dans notre stack Chef lors de nos « Vendredis de la panne ». Récemment, nous avons notamment testé : les délais d'attente du serveur Chef, la perte d'un serveur Chef et sa restauration à partir d'une sauvegarde, ainsi que l'impact sur les clients de latences élevées et de pertes de paquets sur le serveur Chef (spoiler : tout ralentit). Pour en savoir plus sur les « Vendredis de la panne », ne manquez pas la publication/présentation de Doug lors des DevOpsDays de Londres.
Nous avons extrait quelques éléments clés de nos spécifications et les avons mis à disposition ici :
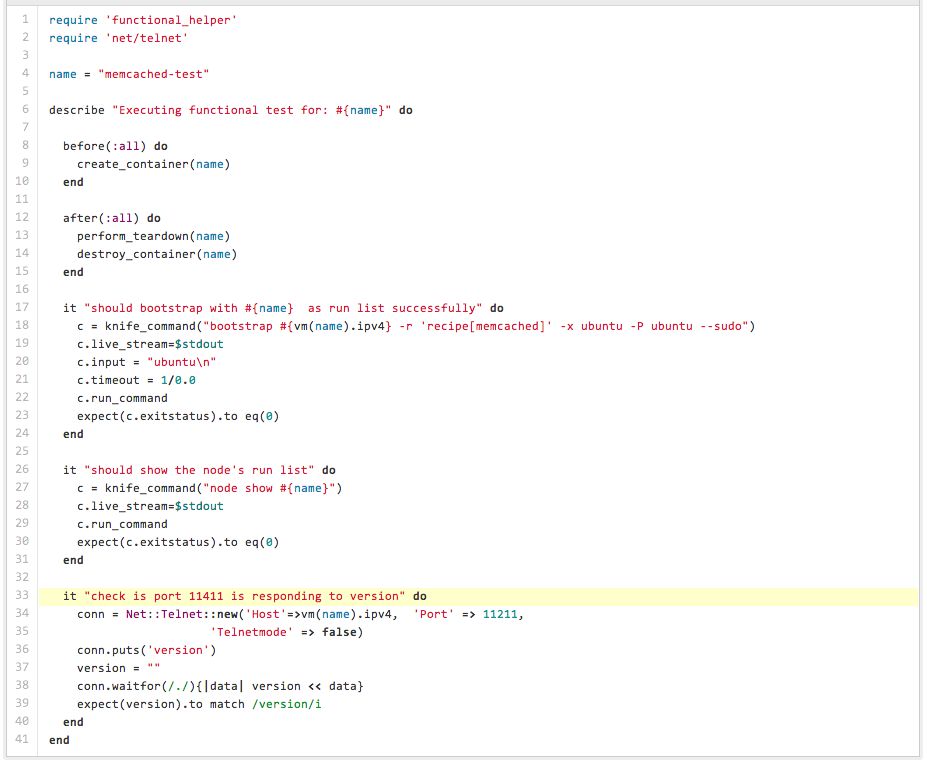
Ces solutions sont fondées sur les limitations actuelles des outils et technologies disponibles que nous pouvons adopter et intégrer. Nombre de ces outils mériteraient d'être développés dans leurs propres bases de code ou de disposer de leurs propres bibliothèques dédiées, ou encore d'être intégrés à leurs alternatives principales correspondantes une fois la pile sous-jacente stabilisée. Ces exemples devraient néanmoins fournir des pistes concrètes de discussion, d'idées et d'amélioration. Vos commentaires sont les bienvenus.
C hef a joué un rôle essentiel dans notre infrastructure informatique. Grâce aux tests automatisés, nous pouvons déployer du code en continu. En réduisant nos délais de mise sur le marché et en améliorant la qualité de nos versions, les clients de PagerDuty peuvent compter sur notre infrastructure résiliente et à haute disponibilité.
Vous pourriez aussi aimer ces articles...

