
- PagerDuty /
- Blog /
- Non classé /
- Améliorer la qualité et la fiabilité grâce à l'intégration continue
Blog
Améliorer la qualité et la fiabilité grâce à l'intégration continue
par Ranjib Dey
14 avril 2014 | 8 minutes de lecture
L'intégration continue (CI) est une pratique de développement logiciel où les membres fusionnent fréquemment leurs travaux afin de réduire les problèmes et les conflits. Chaque poussée est soutenue par une compilation (et des tests) automatisés pour détecter les erreurs. Grâce à des échanges réguliers, les équipes peuvent développer des logiciels plus rapidement et plus efficacement. En substance, l'intégration continue consiste à vérifier la qualité du code afin de garantir qu'aucun bug n'est introduit dans l'environnement de production. Si des bugs sont détectés lors des tests, leur source est facilement identifiée et corrigée. En testant fréquemment le code après chaque validation, vous pouvez réduire la durée d'investigation autour de la source du bug. Cependant, tester le code manuellement est fastidieux et redondant. De nombreux tests peuvent être réutilisés, c'est pourquoi nous avons créé plusieurs tests automatisés pour faciliter la fréquence des tests. De plus, comme ces tests sont itératifs, dès qu'un bug est détecté, nous créons un test qui le recherche lors des prochaines revues de code afin que les anciens bugs ne soient plus jamais introduits.
Avant une construction automatisée
 Chez PagerDuty , après avoir défini les éléments à développer, un ticket JIRA est créé pour faciliter la collaboration et tenir les membres informés de l'état d'avancement. Ce ticket contient des informations sur les effets de la fonctionnalité ou du correctif et leurs impacts connus. Nous créons ensuite des branches locales depuis notre dépôt Git pour la fonctionnalité à développer ou le problème/bug à corriger, et leur attribuons le même nom que le ticket JIRA. Git Il s'agit d'un système de contrôle de version distribué (DVCS). Il n'existe donc pas de référentiel source unique d'où provient le code, mais plusieurs copies de travail. Cela évite les points de défaillance uniques dans les référentiels traditionnels à source unique, qui reposent sur une seule machine physique. Chez PagerDuty , la redondance est notre priorité (plusieurs bases de données, plusieurs hébergeurs, plusieurs fournisseurs de contacts pour plusieurs méthodes de contact, etc.). Un DVCS facilite donc le développement local, même en cas de problème. Bazaar et Mercury sont d'autres DVCS que vous pourriez consulter.
Chez PagerDuty , après avoir défini les éléments à développer, un ticket JIRA est créé pour faciliter la collaboration et tenir les membres informés de l'état d'avancement. Ce ticket contient des informations sur les effets de la fonctionnalité ou du correctif et leurs impacts connus. Nous créons ensuite des branches locales depuis notre dépôt Git pour la fonctionnalité à développer ou le problème/bug à corriger, et leur attribuons le même nom que le ticket JIRA. Git Il s'agit d'un système de contrôle de version distribué (DVCS). Il n'existe donc pas de référentiel source unique d'où provient le code, mais plusieurs copies de travail. Cela évite les points de défaillance uniques dans les référentiels traditionnels à source unique, qui reposent sur une seule machine physique. Chez PagerDuty , la redondance est notre priorité (plusieurs bases de données, plusieurs hébergeurs, plusieurs fournisseurs de contacts pour plusieurs méthodes de contact, etc.). Un DVCS facilite donc le développement local, même en cas de problème. Bazaar et Mercury sont d'autres DVCS que vous pourriez consulter.
Écrire d'abord les tests
Bien qu'il serait souhaitable d'avoir des tests automatisés pour tout ce que nous développons, leur développement prend du temps. Nos tests sont créés avant l'écriture du code afin que nous puissions les utiliser pour gérer nos conceptions et éviter d'écrire du code difficile à tester. Ce développement piloté par les tests (TDD) améliore la conception logicielle et facilite la maintenance du code. Nous priorisons les critères de test dans l'ordre ci-dessous, car ils ont le plus grand impact sur la fiabilité et les ressources.
1. Sécurité – Les bugs critiques qui bloquent nos flux de travail entrent dans cette catégorie. Si le correctif modifie un chemin de code critique pour l'entreprise, nous devons nous assurer que tout est testé.
2. Stratégique – Réorganisation du code à grande échelle, avec ajout de nouvelles fonctionnalités. Ces tests tendent à ajouter des spécifications correspondantes à notre suite de tests. Cela permet de gérer à la fois les scénarios de chemins favorables et les régressions connues. Par exemple, l'ajout de différents types de services/microservices (un nouveau magasin persistant) ou un nouvel outil (automatisant une tâche manuelle longue et répétitive).
3. Cohérence En tant qu'équipe en pleine croissance, nous devons nous assurer que le code généré est facile à comprendre pour un nouveau développeur. Cet exercice est une bonne pratique établie pour la qualité du code, la gestion des erreurs et l'identification des problèmes de performance. Toute personne connaissant Chef devrait être capable de comprendre notre base de code. Par exemple, nous isolons nos personnalisations et les capturons sous forme de correctifs/bibliothèques distincts, puis les envoyons aux projets en amont. Dans ces scénarios, nous rédigeons des spécifications pour la couche d'intégration (c'est-à-dire la partie qui relie les extensions aux bibliothèques externes, comme les livres de recettes communautaires, les gemmes, les outils, etc.).
4. Connaissances partagées Chaque fonctionnalité repose sur des hypothèses valides ou spécifiques à un domaine. Nous utilisons des tests pour déterminer ces domaines et en connaître les limites. Ces hypothèses sont très spécifiques à notre infrastructure, à ses dépendances et à sa topologie globale. Par exemple, nous générons des fichiers de configuration dynamiques pilotés par la recherche pour différents services (par exemple, nous trions systématiquement les résultats de recherche avant de les utiliser). Nous écrivons des tests pour valider et appliquer ces hypothèses, qui sont également exploitées par les chaînes d'outils en aval (comme les conventions de nommage entre serveurs, environnements, etc.).
Notre suite de tests
Les tests que nous écrivons se répartissent en cinq catégories. Tout code généré doit réussir les tests dans l'ordre ci-dessous, à l'exception des tests de charge, avant d'être déployé afin de garantir sa qualité et sa fiabilité.
Tests sémantiques : Nous utilisons des contrôles Lint pour la sémantique globale du code et les meilleures pratiques courantes et Rubocop pour le peluchage du rubis et Critique culinaire Pour le linting spécifique à Chef. Ces outils sont sensibles au code ; selon le langage utilisé, ils peuvent être plus ou moins efficaces. Les outils de linting sont appliqués globalement après chaque commit, et nous n'avons pas besoin d'écrire de code supplémentaire pour cela.
Les tests Lint ont détecté à plusieurs reprises des bugs réels, en plus de signaler des erreurs de style. Par exemple, FoodCritic peut détecter les ressources Chef qui n'envoient pas de notification lors de leur mise à jour.
Tests unitaires : Nous écrivons des tests unitaires pour presque chaque morceau de code. Si nous développons des recettes Chef, les tests Chefspec sont écrits en premier. Si nous écrivons des bibliothèques Ruby brutes, les tests Rspec sont écrits en premier. Les tests Lint et unitaires ne recherchent pas de fonctionnalités. Ils vérifient si le code est bien conçu ou non.
Une bonne conception permet aux autres membres de s'approprier et de comprendre rapidement le code. De plus, ces tests montrent la facilité avec laquelle le code peut être découplé. La technologie évolue constamment et le code doit être flexible. Si Ubuntu ou Nginx publie un correctif pour des raisons de sécurité, est-il facile d'accepter ce changement ?
Tests fonctionnels : Ces tests visent à vérifier la fonctionnalité dans son ensemble, sans aucune connaissance en implémentation, sans simuler ni stubber aucun sous-composant. Nous nous efforçons également de rendre les spécifications fonctionnelles aussi lisibles que possible, en langage clair et sans constructions spécifiques au langage de programmation.
Ces tests aident à :
provisionnement d'un nouveau serveur
démontage du serveur existant
un provisionnement de cluster entier
si une séquence d'opérations fonctionne ou non
Nous utilisons Concombre et Aruba pour écrire des tests fonctionnels. Ces tests ne s'intéressent pas à la manière dont le code est écrit, mais seulement à son bon fonctionnement. Cucumber est un outil BDD qui permet d'écrire des spécifications de manière lisible (avec Gherkin), tandis qu'Aruba est une extension de Cucumber qui permet de tester des applications en ligne de commande. La grande majorité de nos outils proposant une interface en ligne de commande (CLI), nous les trouvons très pratiques et faciles à utiliser.
Tests d'intégration : Ces tests garantissent le bon fonctionnement de l'ensemble lorsqu'il est combiné avec tous les autres services au sein d'une topologie de production, conformément à un modèle de trafic similaire. Cela nous permet également de déterminer si notre suite d'automatisation système fonctionnera parfaitement avec différents services, et avec chaque modification apportée à ces derniers ou à d'autres services tiers que nous utilisons.
Tests de charge : Cela nous aidera à déterminer l'ampleur du trafic que nous pouvons gérer et à identifier rapidement les principaux goulots d'étranglement en termes de performances. Nous effectuons une série de tâches de configuration pour garantir un volume de données comparable à celui d'un environnement de production. Ces tests sont généralement chronophages et gourmands en ressources ; ils sont donc effectués périodiquement sur un ensemble de modifications de code (traitement par lots). Les modifications de code pour lesquelles nous estimons que les performances ne sont pas un problème (modifications de configuration, ajustements de l'interface utilisateur) échappent parfois à ces tests.
Automatisation du déploiement et de la vérification de l'intégrité
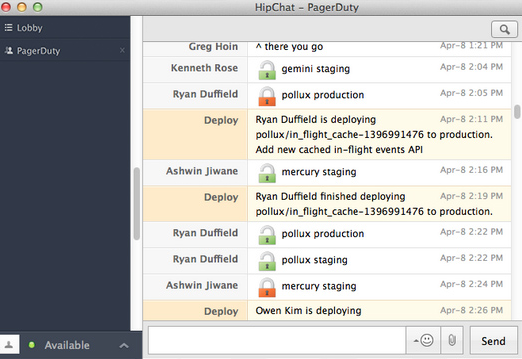 Une fois le code passé avec succès tous les tests, nous le transmettons à un autre membre de l'équipe pour une vérification de cohérence avant sa publication. Nous effectuons une analyse manuelle du code afin d'obtenir un second avis et de garantir qu'aucun bug n'est introduit en production. La revue du code par les pairs permet de garantir qu'aucune exigence n'a été manquée et que le code est conforme aux normes de conception.
Une fois le code passé avec succès tous les tests, nous le transmettons à un autre membre de l'équipe pour une vérification de cohérence avant sa publication. Nous effectuons une analyse manuelle du code afin d'obtenir un second avis et de garantir qu'aucun bug n'est introduit en production. La revue du code par les pairs permet de garantir qu'aucune exigence n'a été manquée et que le code est conforme aux normes de conception.
Nous utilisons un déploiement semi-automatique, où l'intégration continue (CI) participe aux tests et aux outils spécifiques au projet (comme Capistrano et Chef) ainsi qu'au déploiement. Le processus de déploiement est quant à lui déclenché manuellement. L'outil de déploiement envoie un message dans la salle HipChat de PagerDuty pour informer tout le monde du déploiement. Il envoie ensuite des notifications avant et après le déploiement (sous forme de messages de verrouillage et de déverrouillage). Cela nous permet de comprendre ce qui est déployé et d'éviter les déploiements simultanés.
Avec l'intégration continue, nous créons une qualité de base de logiciel qui doit être respectée et maintenue, ce qui réduit le risque autour de nos versions.
Vous aimerez peut-être aussi ceux-ci...

