- PagerDuty /
- Blog /
- Gestion et réponse aux incidents /
- Titres de construction pour le regroupement intelligent des alertes
Blog
Titres de construction pour le regroupement intelligent des alertes
par Quintessence Anx
27 janvier 2022 | 7 min de lecture
Co-écrit par Chris Bonnell, Data Scientist VI PagerDuty
Voici notre troisième article sur l'utilisation et l'optimisation du regroupement intelligent des alertes (IAG) ! Si vous l'avez manqué, notre premier article vous a présenté cette fonctionnalité. ( ici Dans le deuxième article, nous avons expliqué comment IAG utilise la fusion pour regrouper les alertes. (ici) Nous avons fait allusion au sujet du jour à la fin du dernier article : aujourd’hui, nous allons aborder la manière d’utiliser les titres d’alerte pour améliorer les matchs IAG.
Vous verrez alors le titre de l'alerte – un rappel
Lorsqu'une alerte est déclenchée sur notre plateforme, la notification peut être diffusée par différents moyens : e-mail, SMS ou notification push directement depuis l'application. Quel que soit le mode de diffusion, les informations minimales affichées sont : le numéro de l'alerte, le service concerné et son titre. Ces informations apparaissent à plusieurs endroits stratégiques. recevoir vos alertes Certains ou tous ces éléments peuvent vous sembler familiers. Veuillez noter que, bien que le niveau d'urgence (par exemple, élevé) serve à déterminer comment vous joindre, il n'est pas affiché de manière visible (mais figure dans les détails de l'incident).
Notifications push et SMS sur téléphone
Prenons par exemple l’écran de verrouillage d’un iPhone (en plus de la notification de SMS et de l’appel téléphonique pour le même événement) :
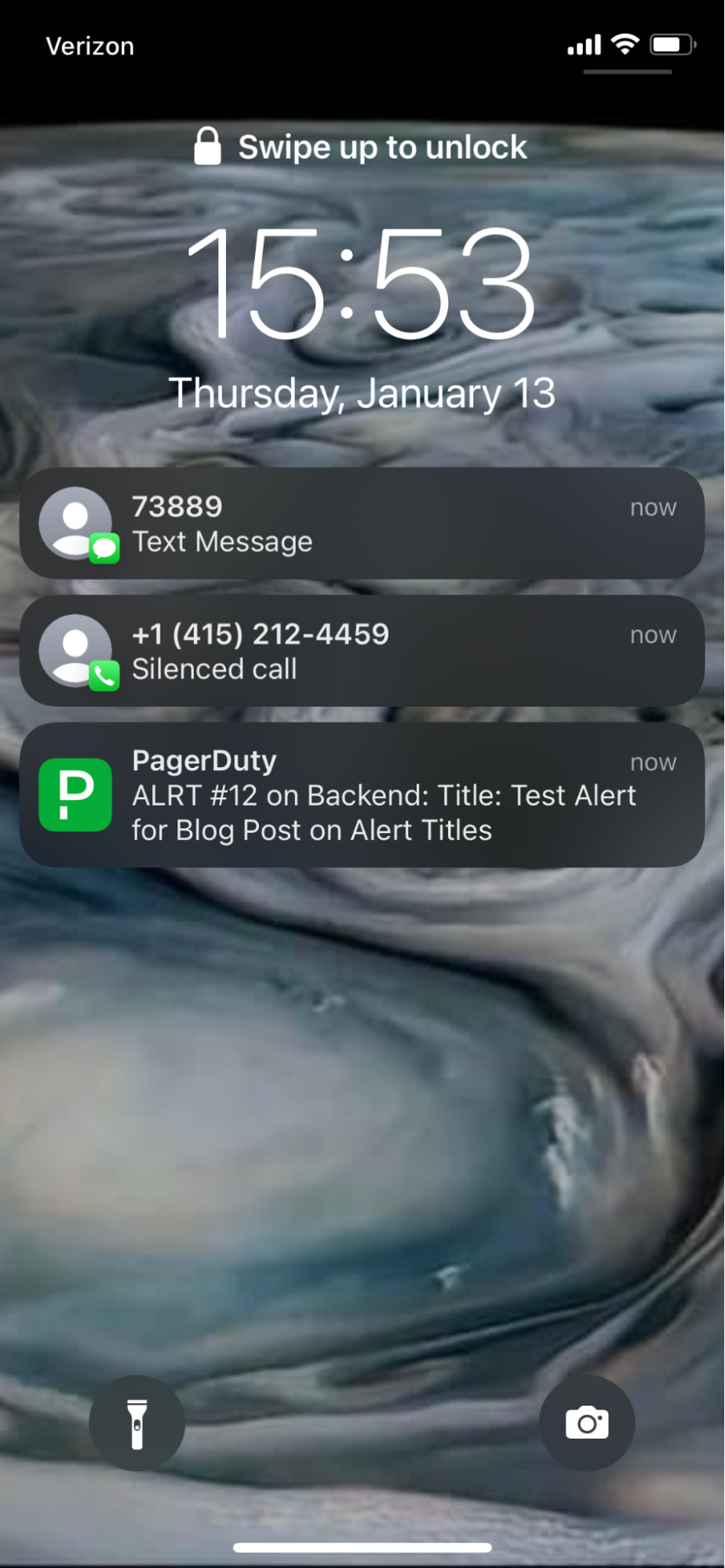
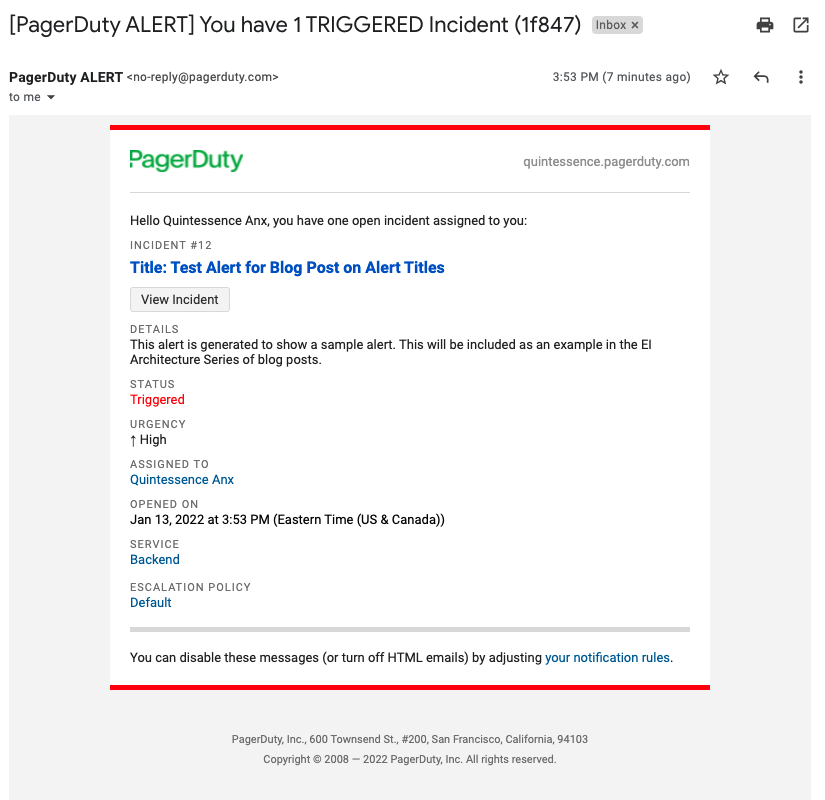
Dans ce cas précis, l'alerte est diffusée sur tous les canaux pour les besoins de cet article de blog. Vous pouvez constater ici que le titre, le numéro et le service de l'alerte s'affichent. Un SMS ressemble à ceci :

notifications par e-mail
Ces messages sont légèrement différents. L'objet de l'e-mail ne donne pas beaucoup de détails, mais le corps du message contient toutes les informations relatives à l'alerte :
Pourquoi examinons-nous l'emplacement d'affichage des titres des alertes ?
Si vous êtes comme moi, lorsque vous rédigez des titres et des descriptions d'alertes pour des situations et des services réels, vous pensez probablement à optimiser pour le cerveau humain. On peut en voir des traces ici et là. Le titre de l'alerte ressemble davantage à un titre d'article de blog et inclut de façon ostentatoire le mot « Titre » pour bien le mettre en évidence. C'est destiné aux humains : lorsque vous parcourez ces images, je veux attirer votre attention sur des zones précises.
Et si je concevais pour des non-humains ? Par exemple, si je concevais pour l’apprentissage automatique ? Je prendrais probablement tout ce que je sais ou ai appris sur l’apprentissage automatique et j’orienterais le message en conséquence.
Ce que je veux que vous reteniez de tout cela, c'est que vous devez toujours garder à l'esprit l'humain lorsque vous commencez à intégrer la notion d'apprentissage automatique pour améliorer votre expérience avec le regroupement intelligent des alertes.
Tirer parti du titre de votre alerte
Lorsque vous rédigez le titre de l'alerte, n'oubliez pas de :
- Soyez concis. Comme vous pouvez le constater, les notifications push et les SMS ont une limite de caractères.
- Les limites varient selon le système d'exploitation et le navigateur web. Par exemple, Android limite le titre des annonces à 65 caractères et la description à 240 caractères, tandis qu'iOS limite le titre et la description à 178 caractères au total.
- Soyez clair. Ne soyez pas si concis que le titre devienne confus ou ne transmette aucune information.
- Ne privilégiez pas le champ « Titre » au détriment des autres champs.
- Les applications mobiles PagerDuty , ainsi que l'interface web, contiennent toutes les informations relatives à l'incident, y compris les autres incidents, leurs services et leurs descriptions. Ne surchargez pas le champ « Titre » simplement parce qu'il apparaît en premier.
Pour plus d'informations à ce sujet, veuillez consulter notre Alerte des directeurs page de notre Guide des opérations de réponse aux incidents.
Pour l'apprentissage automatique, gardez les points suivants à l'esprit :
- Tirez parti de votre singularité et de votre fréquence.
- Les modèles de données ne peuvent pas lire (au même sens que les humains).
- Les modèles de données ne peuvent pas déduire une intention.
La raison d'être de cette approche réside dans la compréhension du fonctionnement du « traitement automatique du langage naturel » par les machines. Ce traitement permet à un correcteur orthographique et grammatical de distinguer « it's » et « its » et d'en informer l'auteur, ou encore à la correction automatique de suggérer le mot, sa conjugaison et sa déclinaison appropriés. Appliqué aux titres d'alertes, le traitement automatique du langage naturel se déroule comme suit : les titres sont anonymisés (nous y reviendrons), puis décomposés en phrases et en mots (par des processus appelés respectivement « tokenisation de phrases » et « tokenisation de mots »), puis les mots sont lemmatisés. Le résultat final sert à déterminer la fréquence d'apparition des alertes et à rechercher des corrélations avec d'autres alertes.
Commençons par l'anonymisation : son objectif est de remplacer les informations trop spécifiques par leur format, par exemple une adresse IP particulière par xx.xx.xx.xx. Ce texte n'est pas entièrement supprimé afin de ne pas appauvrir le contexte potentiellement pertinent, mais aussi d'éviter que les informations spécifiques n'empêchent la corrélation des titres. La lemmatisation est le processus de simplification des mots conjugués ou déclinés en une forme de base, appelée lemme. Par exemple : {« dogs », « dog's », « dogs' », « dog »} seraient tous lemmatisés en « dog », et de même {« is », « are », « be », « were »} en « be ». Ainsi, les phrases comme « The dog's bones. » et « The dogs' bones. » sont toutes deux lemmatisées en {« the », « dog », « bone », « . »} à cette étape.
À ce stade, le modèle de regroupement intelligent des alertes utilise à la fois les n-grammes (groupes de N mots) et notre connaissance des schémas linguistiques des incidents pour extraire des informations du titre de l'alerte et établir des corrélations pertinentes. Revenons sur les exemples que j'ai inclus dans mon… article précédent :
- Premier motif :
- Utilisation de la mémoire élevée (> N %) sur le serveur $NAME dans la région $REGION
- Deuxième modèle :
- L'utilisation de la mémoire sur l'hôte est élevée (> N %).
J'ai déjà effectué une partie de l'anonymisation avec N % et $NAME, mais passons en revue l'exercice de tokenisation du contenu de ces titres :
- premier modèle tokenisé et lemmatisé :
- {'memory', 'use', 'high', '(', '>', 'N', '%', ')', 'on', 'server', '$NAME', 'in', 'region', '$REGION'}
- deuxième modèle tokenisé et lemmatisé :
- {'mémoire', 'utiliser', 'sur', 'hôte', 'être', 'haut', '(', '>', 'N', '%', ')'}
Si l'on considère l'impact de la signification des modèles, dans la seconde alerte, seul le terme N varie, selon sa valeur. Si le seuil est constant et non lié à l'utilisation actuelle de la mémoire, alors N pourrait ne pas varier du tout ou ne prendre qu'une ou deux valeurs dans le titre. En revanche, le titre de la première alerte présente une plus grande unicité grâce au nom du serveur et à sa région. On compte donc trois termes variables au lieu d'un seul, voire aucun. Du point de vue du traitement du langage, les alertes du second modèle sont par conséquent beaucoup plus susceptibles d'être corrélées que celles du premier.
Où aller à partir d'ici
Il est important de prendre en compte à la fois les humains et l'apprentissage automatique lors de la création des titres de vos alertes, avec un léger L'optimisation par apprentissage automatique repose sur l'utilisation de l'intégralité des détails des alertes et incidents pour obtenir un contexte et des informations supplémentaires, contrairement au regroupement intelligent des alertes qui se base uniquement sur le titre. Pour en savoir plus sur les principes fondamentaux du traitement automatique du langage naturel, consultez la documentation. Introduction au traitement automatique du langage naturel pour le texte Article de blog sur le blog Towards Data Science. Pour connaître les bonnes pratiques concernant les informations pertinentes à inclure dans les alertes et les incidents en général, veuillez consulter notre Guide des opérations de réponse aux incidents .
Vous pourriez aussi aimer ces articles...

