
- PagerDuty /
- Blog /
- Non classé /
- Survivre à une panne de centre de données
Blog
Survivre à une panne de centre de données
par Amanda Folson
20 janvier 2015 | 3 minutes de lecture
PagerDuty a été conçu autour d'une idée simple : alerter les bonnes personnes en cas de problème. Lorsqu'un événement se produit, PagerDuty fait des miracles pour avertir la bonne personne ou l'équipe concernée.

Cependant, s'assurer que le message parvienne jusqu'à vous n'est pas si simple. Comme nous vous envoyons des notifications lorsque vos systèmes sont en panne, notre capacité à fonctionner est fortement limitée. Si vous ne pouvez pas nous faire confiance, à qui pouvez-vous faire confiance ?
Nous utilisons quelques technologies distribuées dans notre pipeline d'alertes, car elles offrent la redondance nécessaire pour garantir la transmission des alertes aux utilisateurs. Nous avons consacré beaucoup de temps à concevoir notre infrastructure pour qu'elle soit aussi tolérante aux pannes que possible afin de garantir des opérations de lecture/écriture durables et cohérentes dans notre pipeline d'alertes critiques.
Ce pipeline commence par un point de terminaison d'événement, HTTP ou e-mail. De là, chaque événement provenant de l'outil de surveillance d'un client passe par un pipeline de services distincts (tels que la gestion des incidents et des notifications) et aboutit finalement au service de messagerie qui contacte les utilisateurs. Nombre de ces services sont basés sur Scala et supportés par Cassandra en back-end pour le stockage des données. Nous utilisons également d'autres technologies comme Zookeeper pour la coordination. Ce pipeline doit être opérationnel en permanence afin de garantir que les notifications parviennent bien aux utilisateurs.
Cassandra chez PagerDuty
Nous utilisons Cassandra en production depuis environ deux ans et demi. Contrairement à certaines entreprises qui utilisent Cassandra pour leurs efforts de « big data », notre ensemble de données est relativement restreint : de l'ordre de quelques dizaines de Go à tout moment. Comme nous l'utilisons pour gérer les événements dans notre pipeline, une fois l'événement terminé, les données le concernant peuvent être purgées du pipeline. Nous nous efforçons de réduire au maximum la taille de notre ensemble de données.

Configuration du cluster
Nous créons généralement des clusters de 5 nœuds Cassandra, avec un facteur de réplication de 5. Ces nœuds sont répartis sur trois centres de données : deux nœuds dans un, deux nœuds dans un autre et un nœud dans une autre installation. Nous utilisons le niveau de cohérence du quorum de Cassandra afin de garantir la durabilité nécessaire au pipeline. Cela signifie que chaque écriture doit être effectuée sur la majorité du cluster, c'est-à-dire sur au moins 3 des 5 nœuds.
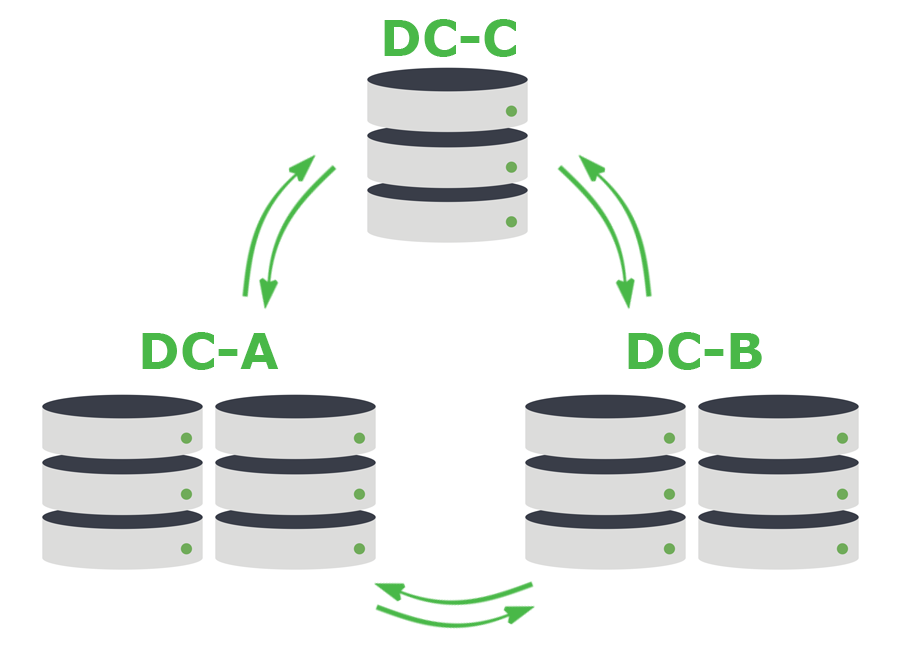
Ce modèle n'est pas sans défauts. Chaque opération s'effectue sur le WAN et subit une latence inter-centres de données. D'une certaine manière, cela va à l'encontre des recommandations habituelles pour les clusters de bases de données. Cependant, comme cette latence n'est pas exposée aux humains, nous sommes prêts à accepter ce compromis compte tenu des avantages : les événements ne sont pas perdus, les messages ne sont pas répétés et nous bénéficions d'une durabilité et d'une disponibilité optimales en cas de perte d'un centre de données entier. Avec ce modèle 3 sur 5, tout est écrit sur au moins deux centres de données.
Comment savons-nous que cela fonctionne ?
Nous introduisons intentionnellement des failles dans notre infrastructure afin de garantir le bon fonctionnement de nos services en cas de panne. Cela inclut des tests approfondis des nœuds Cassandra dans des états dégradés et non fonctionnels. Pour en savoir plus, consultez notre Message du vendredi échec .
Chez PagerDuty, nous aimons résoudre des problèmes techniques complexes. Si vous souhaitez améliorer la robustesse de notre cluster, nous recrutons actuellement pour des postes dans San Francisco et Toronto .

