
- PagerDuty /
- Blog /
- Automation /
- Vite ! Récupérez toutes les preuves : capture de l'état de l'application pour une analyse médico-légale post-incident.
Blog
Vite ! Récupérez toutes les preuves : capture de l'état de l'application pour une analyse médico-légale post-incident.
par Jake Cohen
9 février 2023 | 5 minutes de lecture
Ceci est le premier d'une série de plusieurs articles. Dans le prochain, nous vous présenterons un modèle de travail exploitant Conteneurs éphémères Kubernetes pour capturer des preuves à partir d'applications exécutées dans Kubernetes.
Tout le monde aime un bon thriller policier. Bon, pas tout le monde, mais Hollywood, lui, l'apprécie. Qu'il s'agisse de Sherlock Holmes ou d'Hercule Poirot, le public apprécie clairement une intrigue captivante où l'on traque le coupable d'un crime odieux. Nombreux sont ceux, moi y compris, qui préfèrent les thrillers policiers où, à la fin, le mystère est « résolu ». Si les suspenses peuvent stimuler l'imagination et vous faire réfléchir aux dénouements probables (vous souvenez-vous de la fin d'Inception de Chris Nolan ?), en matière de romans policiers, je préfère, j'avoue, connaître la réponse à la question « Qui a commis le crime ? »

Source : https://www.dazeddigital.com/artsandculture/article/24949/1/christopher-nolan-explains-the-spinning-top-in-inception
Pour qu'une histoire de détective soit complètement concluante, les preuves du crime doivent idéalement être parfaitement claires et fournies de manière très détaillée, de sorte que le véritable coupable soit découvert et, espérons-le, traduit en justice.
Dans le monde des opérations techniques et du maintien de la disponibilité des services critiques, un conflit évident surgit, comparable à un roman policier hollywoodien. Lorsque des applications critiques subissent une dégradation des performances, voire une panne totale, les ingénieurs s'empressent de trouver la cause (apparente) de l'incident afin de pouvoir y remédier au plus vite. Les équipes utilisent les outils à leur disposition pour localiser et isoler la ressource de calcul surchargée, la requête bloquée ou la file d'attente saturée, et interviennent rapidement pour corriger le problème.
Il s'avère cependant que ce n'est que le début d'un thriller policier. Dans ce genre de mystère policier, les témoins perçoivent le coupable comme celui qui se trouvait au mauvais endroit au mauvais moment. Mais à mesure que de nouvelles preuves sont découvertes, il devient clair que le « véritable coupable » était un cerveau maléfique qui fomentait un plan plus ambitieux à distance. Malheureusement pour nos ingénieurs « détectives », une fois la cause (apparente) éliminée, il est fort probable qu'ils aient inconsciemment éliminé des preuves pointant vers le coupable : le redémarrage d'un service ou le redéploiement d'un module élimine de précieuses preuves médico-légales.
On peut imaginer l'inspecteur en chef s'arracher les cheveux lorsqu'il réalise qu'une pluie mal programmée a effacé les empreintes digitales qui lui auraient donné leur meilleure piste.

Source : https://www.defendyourcase.com/criminal-defense-blog/2020/february/are-fingerprints-at-the-crime-scene-enough-evide/
De nos jours, les développeurs et les ingénieurs d’exploitation sont confrontés au même bras de fer : restaurer les services le plus rapidement possible sans perdre les preuves critiques qui les aideraient à identifier la cause profonde de leurs incidents au niveau du code.
Mais attendez, n'est-ce pas à cela que servent les outils de surveillance ? La réponse est : parfois. Selon le problème, les erreurs de configuration ou de code peuvent être détectées grâce à des outils d'observabilité sophistiqués. Cependant, les développeurs ont souvent besoin de données encore plus granulaires, non capturées par les outils de surveillance, tout simplement parce que ces données de débogage ne sont pas nécessaires aux alertes ou à la restauration du service. Des données telles que les dumps de tas, de threads et TCP, les requêtes de base de données les plus gourmandes en ressources et les traces de pile permettent d'identifier le « véritable coupable », mais ne sont généralement pas nécessaires à la restauration du service. La collecte de ces données prend du temps, et nous savons tous qu'en cas d'incident, la restauration de la disponibilité du service prime sur tout le reste.
Malheureusement, l’adoption et la prolifération des applications conteneurisées et de l’orchestration des conteneurs n’ont fait qu’intensifier ce bras de fer pour deux raisons principales :
- Les architectures de microservices fournissent des méthodes plus rapides pour restaurer la disponibilité en toute sécurité, comme le redéploiement d’un pod.
- Moins d'utilitaires de débogage sont disponibles dans ces environnements, car les développeurs et les ingénieurs d'exploitation souhaitent minimiser la surface de leurs images de conteneur.
Afin de tenir compte des forces opposées dans ce bras de fer, une solution est nécessaire, capable d'agir à une « vitesse instantanée » de manière à ce que les preuves puissent être capturées et conservées, tout en rétablissant immédiatement le service par la suite :
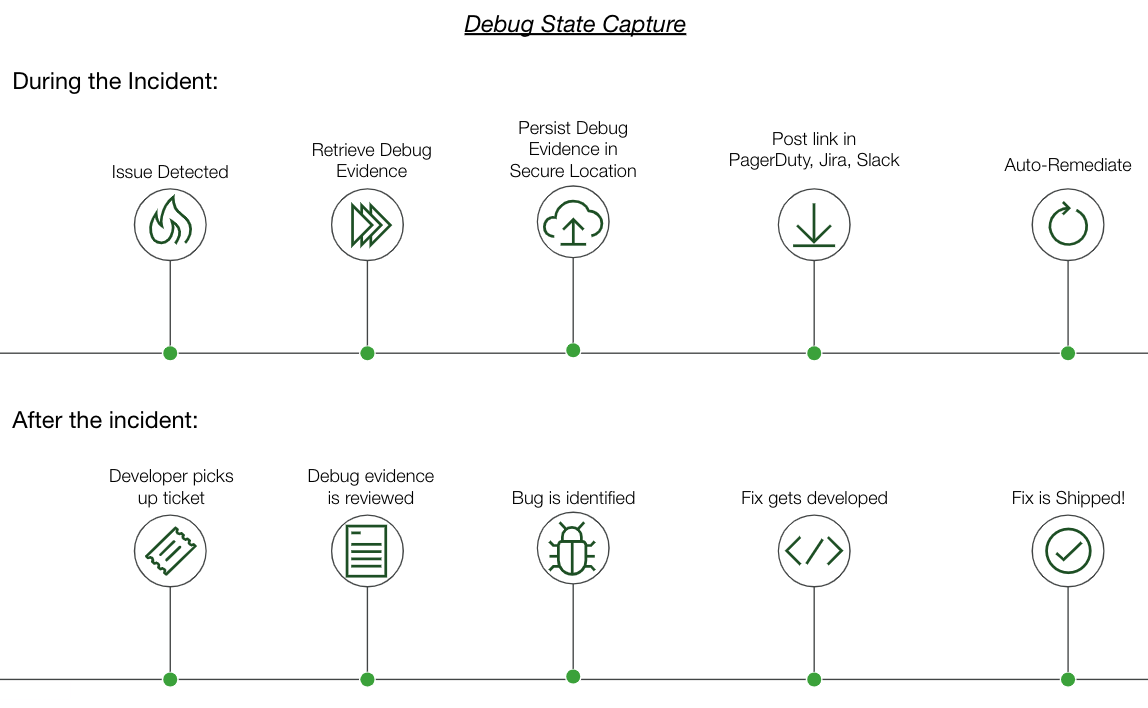
Une telle solution est fournie par Operations Cloud de PagerDuty. Grâce à des runbooks déclenchés instantanément dès la détection d'un problème, des preuves de débogage peuvent être collectées et envoyées à un service de stockage persistant, tel que S3, et les services peuvent être restaurés à l'aide de correctifs connus. Grâce à une vaste bibliothèque d'intégrations prédéfinies pour les environnements sur site et cloud, et à une liste croissante de modèles de runbooks, les utilisateurs de PagerDuty peuvent atteindre cet objectif apparemment audacieux : réduire le MTTR et le temps passé à reproduire les bugs pour résoudre les tickets de dette technique. Les clients PagerDuty peuvent demander un essai de Runbook Automation. ici , tandis que les nouveaux utilisateurs peuvent démarrer avec PagerDuty Incident Response ici .
De plus, n'oubliez pas de consulter notre Guide des solutions de diagnostic automatisé pour voir certains de ces exemples de runbooks.
Ceci est le premier d'une série de plusieurs articles. Dans le prochain, nous vous présenterons un modèle de travail exploitant Conteneurs éphémères Kubernetes pour capturer des preuves à partir d'applications exécutées dans Kubernetes.
Restez curieux, mes chers détectives.

