
- PagerDuty /
- Blog /
- Automation /
- Débogage de Kubernetes avec des runbooks automatisés et des conteneurs éphémères
Blog
Débogage de Kubernetes avec des runbooks automatisés et des conteneurs éphémères
par Jake Cohen
2 mai 2023 | 5 min de lecture
Dans notre blog précédent Nous avons évoqué la difficulté de recueillir tous les diagnostics pertinents lors d'un incident avant d'appliquer une solution de fortune. L'exemple concret le plus courant est celui d'une application exécutée dans un conteneur, puis de ce conteneur redéployé (éventuellement vers une version antérieure ou la même) afin de résoudre le problème immédiat. Pour les entreprises où chaque milliseconde de performance et chaque seconde de disponibilité ont un impact significatif sur l'expérience client, ces solutions à court terme sont indispensables. Cependant, les coûts pour l'entreprise deviennent importants lorsque les ingénieurs sont chargés de développer des solutions plus durables. à long terme Pour résoudre ces incidents, qu'il s'agisse d'incidents majeurs ou mineurs (récurrents), les ingénieurs doivent consacrer un temps considérable à recueillir des preuves de l'état de l'application et de l'environnement au moment de l'incident.
Bien qu'une bonne partie de ces données de diagnostic réside dans les outils de surveillance et soit donc persistante, il est parfois nécessaire d'obtenir un accès shell à un conteneur pour récupérer des informations disponibles uniquement pendant la durée de vie de ce conteneur. Dans Kubernetes, cela se fait à l'aide de… kubectl exécu commande. Avec les bons paramètres, les utilisateurs peuvent obtenir un shell actif dans leur conteneur en cours d'exécution et commencer à exécuter des commandes pour récupérer des informations de diagnostic. Par exemple, une fois qu'un utilisateur dispose d'un shell dans un conteneur Java, il peut invoquer jstack pour obtenir un dump des threads de leur application.
Mais de nombreuses équipes opérationnelles ne le permettent pas n'importe qui exécutif Dans les environnements de production (où surviennent les incidents critiques), le nombre de personnes pouvant intervenir est très limité, pour des raisons de sécurité et en raison du nombre restreint de personnes maîtrisant Kubernetes. Par conséquent, pour récupérer des données de diagnostic lors d'un incident, il est régulièrement nécessaire de faire appel à des experts Kubernetes. Ce processus augmente le coût des incidents en allongeant le MTTR (temps moyen de résolution) et en accroissant le nombre de personnes impliquées.

Pour ces raisons, il est préférable d'utiliser une automatisation qui élimine la nécessité pour les utilisateurs de exécutif dans des pods en cours d'exécution. Grâce à cette architecture d'automatisation, lorsqu'un problème survient, un runbook automatisé est invoqué. Ce runbook récupère les données de débogage, les envoie vers un emplacement de stockage persistant (S3, stockage Blob, serveur SFTP, etc.) et informe ensuite les ingénieurs de l'endroit où ils peuvent localiser et utiliser ces données.
PagerDuty Process Automation fournit un runbook préconfiguré et standardisé pour ce cas d'utilisation précis : lorsqu'une alerte crée un incident dans PagerDuty, cela peut déclencher automatiquement (ou par un simple clic sur un bouton) le runbook pour exécuter des commandes dans le pod, envoyer la sortie vers un stockage persistant et fournir des détails sur l'emplacement de ces données dans l'incident.
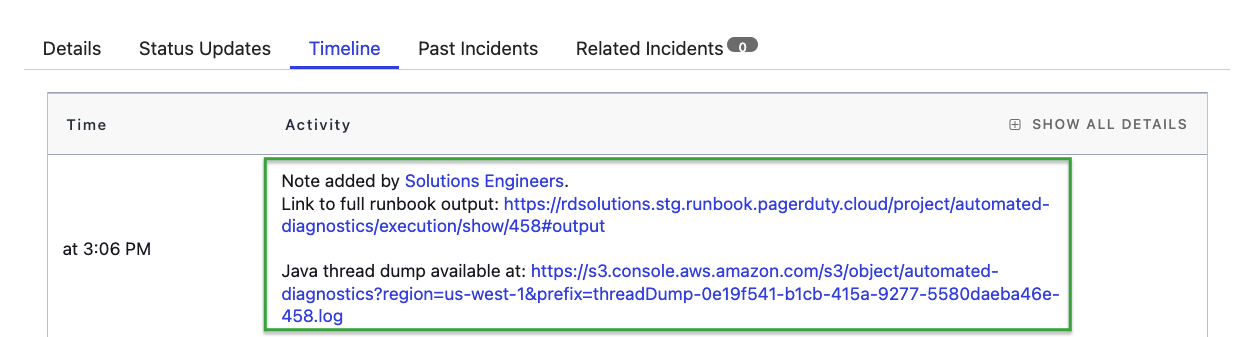
Un lien vers les données de débogage est fourni aux ingénieurs pendant et après l'incident.
Les utilisateurs de nos deux produits d'automatisation commerciale ( Automatisation des processus et automatisation des manuels d'exploitation ) et open source Pont de course peuvent suivre les instructions ici pour télécharger et commencer à utiliser le manuel d'exécution automatisé.
Ce guide d'exécution automatisé est idéal lorsque l'image du conteneur contient déjà les utilitaires en ligne de commande (binaires) nécessaires au débogage. Par exemple, de nombreuses applications Java conteneurisées sont livrées avec ces utilitaires. jstack L'image du conteneur contient-elle des utilitaires ? Mais que se passe-t-il lorsque ces utilitaires ne sont pas inclus ? Ou, comme c'est de plus en plus fréquent, que se passe-t-il lorsque le conteneur est « sans distribution » et ne fournit donc même pas d'interpréteur de commandes ?

C'est ici que Conteneurs éphémères Kubernetes entrent en jeu, offrant aux utilisateurs un mécanisme permettant d'attacher un conteneur (de n'importe quelle image) à un pod en cours d'exécution sans avoir besoin de modifier la définition du pod ou de redéployer le pod.
En partageant l'espace de noms du processus, le conteneur éphémère peut utiliser ses outils de débogage pour un autre conteneur du pod, même si le conteneur d'origine est en panne. Voici un exemple : blog par Ivan Velichko qui détaille le partage d'espace de noms de processus avec des conteneurs éphémères :
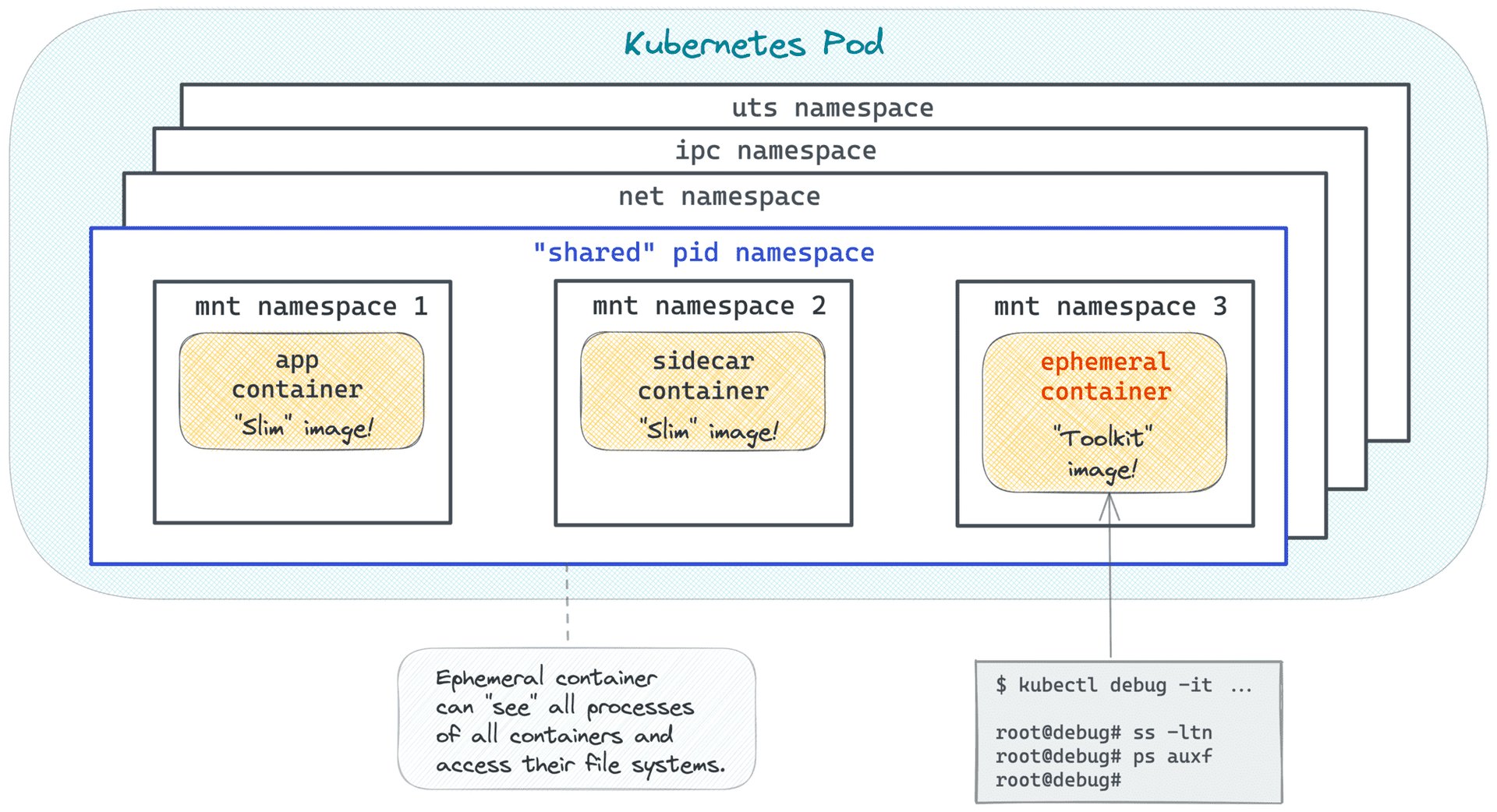
Source : https://iximiuz.com/en/posts/kubernetes-ephemeral-containers/
Similaire à l'utilisation kubectl exécu , l'utilisation correcte des conteneurs éphémères nécessite toujours un accès à l'exécution kubectl Les commandes sur le cluster Kubernetes sont rarement accessibles aux opérations externes. Et comme auparavant, savoir comment construire correctement la commande exige une excellente maîtrise de Kubernetes :
kubectl debug -it -n ${namespace} -c debugger --image=busybox --share-processes ${pod_name}
(Exemple de commande pour utiliser les conteneurs éphémères Kubernetes)
Pour permettre aux utilisateurs disposant de conteneurs sans utilitaires de débogage ou de conteneurs sans distribution de distribution de s'exprimer, nous avons conçu un nouveau plugin Kubernetes qui exploite la fonctionnalité des conteneurs éphémères :
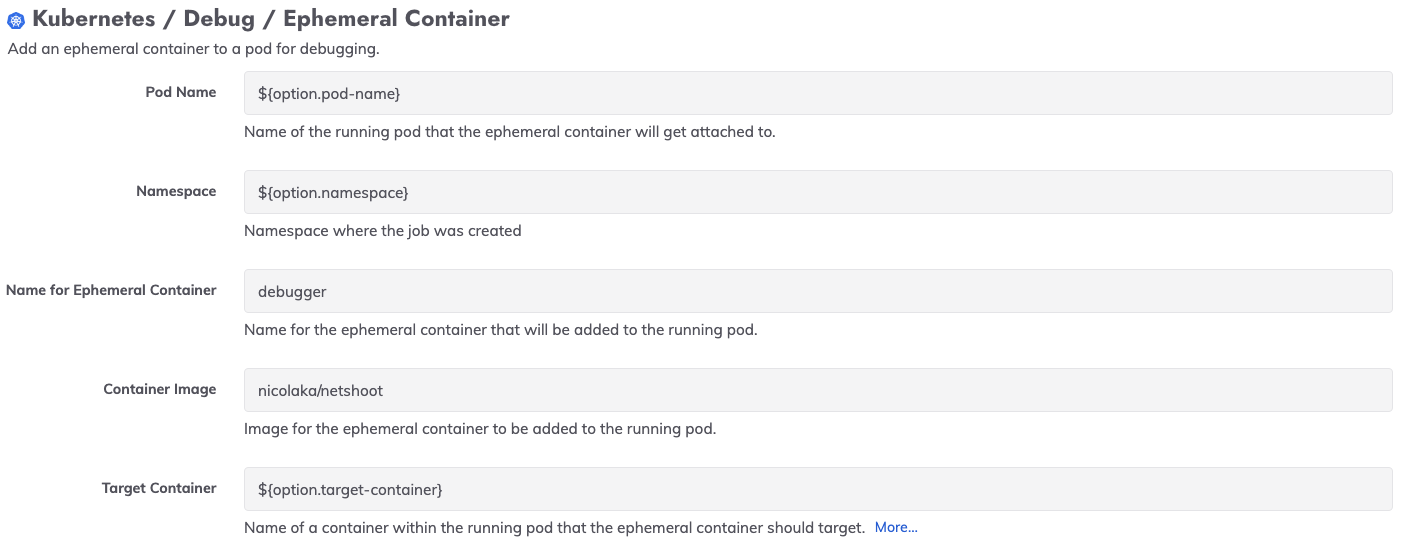
Nous avons utilisé ce plugin dans un modèle de runbook automatisé qui capture également les résultats de diagnostic et les envoie vers un emplacement permanent. Les utilisateurs de Process Automation et de Runbook Automation peuvent démarrer avec ce modèle en le téléchargeant dans le cadre du projet de diagnostic automatisé. ici .
Si vous ne possédez pas encore de compte Process Automation ou Runbook Automation, cliquez ici. ici pour commencer à utiliser les produits d'automatisation de PagerDuty.

