- PagerDuty /
- Blog /
- Gestion et réponse aux incidents /
- Vendredi des échecs : Comment nous garantissons la fiabilité de PagerDuty
Blog
Vendredi des échecs : Comment nous garantissons la fiabilité de PagerDuty
par Kenneth Rose
20 novembre 2013 | 7 min de lecture
Demandez à n'importe quel employé de PagerDuton quelle est l'exigence la plus importante de notre service et vous obtiendrez la même réponse : la fiabilité. Nos clients comptent sur nous pour les alerter en cas de problème avec leurs systèmes ; à temps, systématiquement, de jour comme de nuit.
Notre code est déployé sur trois centres de données et deux fournisseurs de cloud afin de garantir la distribution de toutes les alertes (téléphone, SMS, notifications push et e-mail). Les parties critiques de notre code sont sauvegardées, et même ces sauvegardes le sont également. Cette triple redondance assure qu'aucune alerte ne soit manquée, qu'aucun SMS ne soit oublié ou qu'aucun e-mail ne soit oublié.
Nous avons besoin de plus qu'une conception tolérante aux pannes
Bien qu'une conception tolérante aux pannes soit un atout, des problèmes d'implémentation peuvent parfois empêcher son bon fonctionnement. Par exemple, des sauvegardes déclenchées uniquement en cas de dysfonctionnement peuvent masquer des bogues ou du code parfaitement fonctionnel en environnement de test, mais défaillant en production. L'hébergement cloud nous oblige à anticiper une éventuelle défaillance de notre infrastructure.
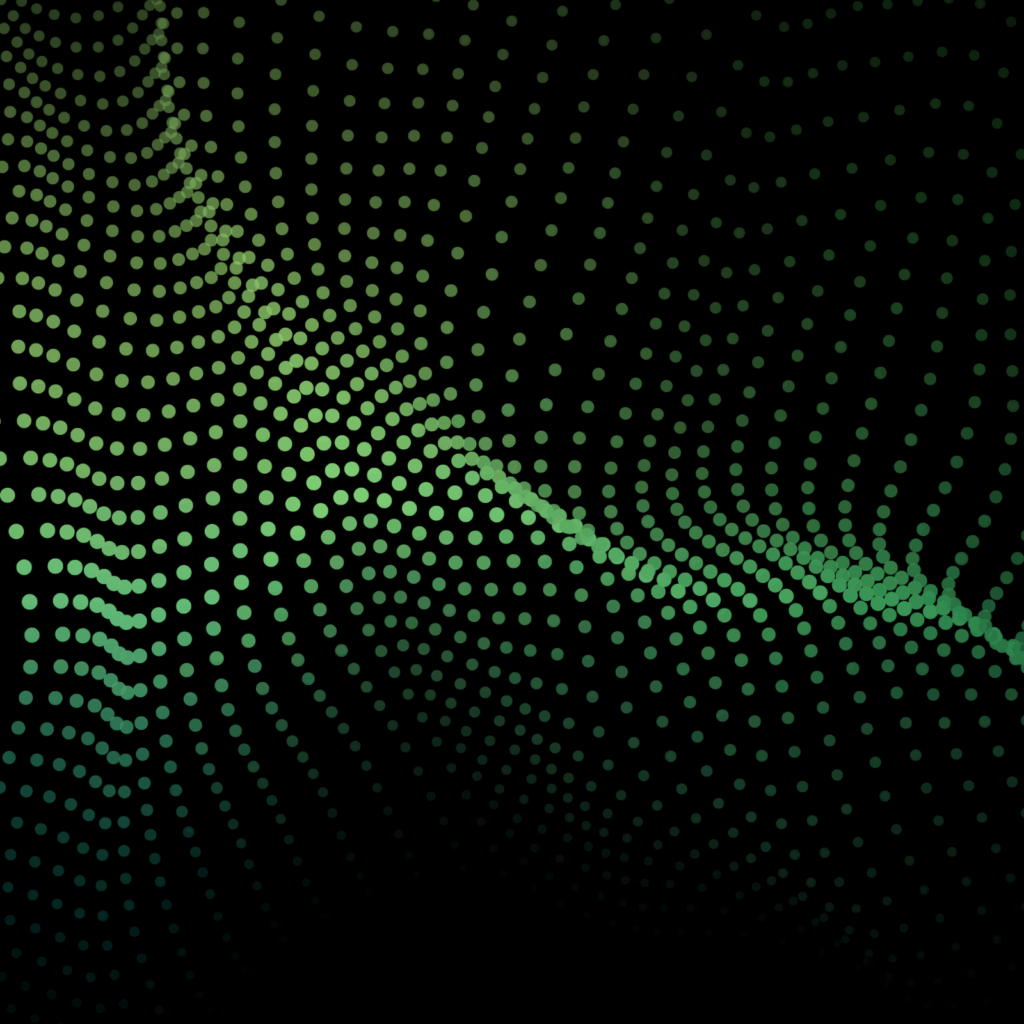
Internet lui-même est source de défaillances. On observe régulièrement des augmentations importantes de la latence et des pertes de paquets entre les centres de données. Certains de ces incidents sont liés à des problèmes connus, comme les attaques DDoS, mais d'autres causes restent inconnues. Dans tous les cas, il n'y a rien d'autre à faire que de contourner ces problèmes.
Latence inter-centres de données en millisecondes
Netflix a résolu ces problèmes grâce à son « Armée des Sims » : un ensemble d'outils automatisés qui testent la résilience des applications face aux pannes. Chaos Monkey arrête les instances, qui sont ensuite redémarrées par des groupes de mise à l'échelle automatique. Latency Monkey introduit une latence artificielle dans les appels réseau. Chaos Gorilla, quant à lui, met hors service une zone de disponibilité entière. Bien que certains de ces outils soient disponibles gratuitement, ils supposent que votre application est déployée exclusivement sur AWS à l'aide de groupes de mise à l'échelle automatique, alors que la nôtre est déployée chez plusieurs fournisseurs.
Ne souhaitant pas nous enliser dans la création de nos propres outils équivalents, nous avons opté pour une méthode simple et directe : planifier une réunion et procéder manuellement. Nous utilisons des commandes Linux courantes pour tous nos tests, ce qui facilite la prise en main.
Avantages du vendredi en cas de défaillance de PagerDuty
Chez PagerDuty, nous avons instauré le « Vendredi de l'échec » ces derniers mois. Nous avons déjà constaté plusieurs avantages :
- Découvre des problèmes de mise en œuvre qui réduisent notre résilience.
- Détecte proactivement les carences afin d'éviter que ces divergences ne deviennent la cause première d'une future panne.
- Construit une culture d'équipe solide En se réunissant une fois par semaine pour partager leurs connaissances, les équipes d'exploitation peuvent apprendre comment les équipes de développement résolvent les problèmes de production sur leurs systèmes. Les développeurs, quant à eux, comprennent mieux le déploiement de leurs logiciels. Et c'est un avantage non négligeable de former les nouvelles recrues à gérer les pannes le vendredi à 11 h plutôt que le samedi à 3 h du matin.
- Cela nous rappelle que l'échec est inévitable. L'échec n'est plus considéré comme un événement isolé qu'on peut ignorer ou minimiser. Tout le code écrit par les équipes d'ingénierie est désormais testé afin de vérifier sa résistance lors du « Failure Friday ».
Préparer notre équipe à l'échec vendredi
Avant le « Vendredi de l'échec », il est important d'établir un ordre du jour recensant tous les échecs que nous souhaitons aborder. Nous prévoyons une réunion d'une heure et travaillons sur autant de sujets que possible.
Injecter une défaillance peut entraîner une défaillance plus grave que prévu. Il est donc essentiel que tous les membres de votre équipe adhèrent à l'idée d'introduire une défaillance dans votre système. Afin de limiter les risques, nous veillons à ce que chaque membre de l'équipe soit informé et impliqué.
En prévision de la première attaque, nous désactiverons toutes les tâches cron programmées pour s'exécuter pendant l'heure prévue. L'équipe dont le service sera ciblé disposera de tableaux de bord pour surveiller ses systèmes pendant l'injection de la faille.
La communication est essentielle lors du « Failure Friday ». Chez PagerDuty, nous utiliserons une salle HipChat dédiée et une conférence téléphonique pour échanger rapidement les informations. L'utilisation d'une salle de discussion est particulièrement utile car elle nous fournit un historique horodaté des actions entreprises, que nous pouvons ensuite corréler avec les indicateurs que nous collectons.
Nous gardons également nos alertes PagerDuty activées pour confirmer que nous recevons bien les alertes et observer leur rapidité d'arrivée par rapport à la panne survenue.
Introduire l'échec dans notre système
Chaque attaque que nous lançons contre notre service dure cinq minutes. Entre chaque attaque, nous rétablissons systématiquement le service à son état de fonctionnement optimal et vérifions que tout fonctionne correctement avant de passer à l'attaque suivante.
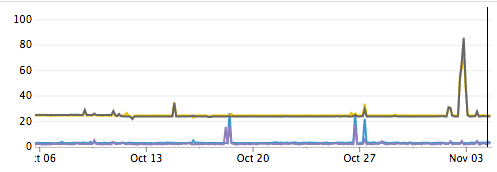
Pendant l'attaque, nous consultons nos tableaux de bord pour identifier les indicateurs clés et comprendre l'impact du problème sur les autres systèmes. Nous notons également dans notre messagerie instantanée les moments où nous avons été alertés et l'utilité de ces alertes.
Pour chaque attaque, nous commençons généralement par attaquer un seul hôte. Si le résultat est conforme aux attentes, nous répétons le test sur un centre de données entier. Pour les services hébergés exclusivement sur AWS, nous vérifions leur capacité à survivre à la perte d'une zone de disponibilité complète.
Attaque n° 1 : Défaillance du processus
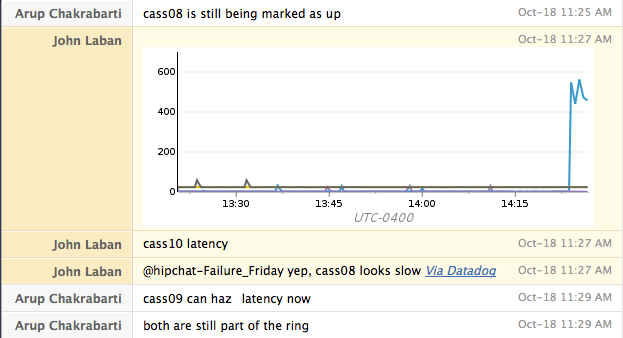
Notre première attaque est assez simple : nous arrêtons le service pendant 5 minutes. Cela se fait généralement avec la commande « sudo service cassandra stop ». Nous nous attendons à ce que le service continue de traiter le trafic malgré cette interruption. Nous pouvons également vérifier si nos alarmes signalent correctement l’indisponibilité du service. Pour le redémarrer, nous exécutons la commande « sudo service cassandra start ».
Attaque n° 2 : Redémarrage des hôtes
Après avoir confirmé notre capacité à survivre à la perte d'un seul nœud et d'un centre de données entier, nous procédons au redémarrage des machines. Cette attaque permet de vérifier qu'au redémarrage, la machine lance correctement tous les services requis. Elle nous aide également à identifier les cas où notre système de surveillance est lié à la machine exécutant le service, ce qui nous empêche de recevoir des alertes pendant son arrêt.
Attaque n° 3 : Isolation du réseau
Lors des deux attaques précédentes, les services ont été arrêtés proprement, puis les serveurs ont été redémarrés. La prochaine attaque vise à évaluer notre résilience face à une panne inattendue. Nous bloquons la connectivité réseau via iptables et supprimons les paquets entrants et sortants. Ce test vérifie que les clients disposent de délais d'attente raisonnables et ne dépendent pas d'arrêts de service corrects.
| sudo iptables -I INPUT 1 -p tcp –dport $PORT_NUM -j DROP |
| sudo iptables -I OUTPUT 1 -p tcp –sport $PORT_NUM -j DROP |
Pour réinitialiser le pare-feu une fois l'opération terminée, il suffit de le recharger depuis le disque :
| sudo reconstruire-iptables |
Attaque n° 4 : Lenteur du réseau
Notre test final évalue la façon dont le service gère les ralentissements. Nous simulons un service lent au niveau du réseau à l'aide de tc.
| sudo tc qdisc add dev eth0 root netem delay 500ms 100ms loss 5% |
Cette commande ajoute un délai de 400 à 600 millisecondes à tout le trafic réseau. Une perte de paquets de 5 % est également à prévoir. En cas de défaillance, une dégradation des performances est généralement attendue. Idéalement, les clients peuvent contourner ce délai. Un client Cassandra, par exemple, pourrait choisir de communiquer avec les nœuds les plus rapides et d'éviter d'envoyer du trafic au nœud défaillant. Cette attaque vise à tester la capacité de nos tableaux de bord à identifier le nœud lent. Notez que cela affecte également toutes les sessions SSH actives.
Le retard est facilement rattrapable.
| sudo tc qdisc del dev eth0 root netem |
Pour conclure
Une fois le « Fallway Breaking Friday » terminé, nous publions un message de confirmation et réactivons nos tâches cron. Enfin, nous tirons les enseignements utiles et les assignons à un membre de notre équipe dans JIRA.
Le « Vendredi des échecs » nous permet non seulement de corriger les problèmes, mais aussi de les prévenir. La fiabilité de PagerDuty est primordiale pour nous, et la participation de notre équipe au « Vendredi des échecs » est essentielle pour la garantir.
Envie d'en savoir plus ? Visionnez la conférence de Doug Barth sur le « Failure Friday », filmée ici même au siège de PagerDuty !
4 ans plus tard
N'oubliez pas de consulter notre prochain article de blog : « Les Vendredis de l'Échec : 4 ans déjà « pour voir comment notre processus a évolué au fil des ans. »
Vous aimerez peut-être aussi...

