
- PagerDuty /
- Blog /
- Meilleures pratiques et perspectives /
- 3x en 3 ans : faire évoluer une organisation d'ingénierie
Blog
3x en 3 ans : faire évoluer une organisation d'ingénierie
par Roman Shekhtmeyster
27 juillet 2017 | 13 minutes de lecture
Il y a trois ans, j'ai rejoint PagerDuty , une jeune pousse prometteuse, en tant que responsable de l'ingénierie. Après avoir reçu un financement de série A en 2013, l'entreprise était en pleine croissance et recrutait massivement dans tous les domaines. L'équipe d'ingénierie comptait alors moins de 30 personnes, et l'un de mes principaux atouts était (et est toujours) de découvrir les défis structurels auxquels est confrontée une organisation en pleine croissance. Alors que nous approchons de la centaine de Dutoniens en ingénierie, il me semble opportun de revenir sur les changements intervenus jusqu'à présent.
L'évolution des structures organisationnelles est un processus fascinant, semé d'erreurs, d'impasses, de réinventions et, espérons-le, d'enseignements. La littérature consacrée aux organisations d'ingénierie est abondante, se résumant souvent à des listes abstraites d'avantages et d'inconvénients ou à des articles de blog vantant les mérites du processus adopté par l'entreprise au moment de la rédaction. Je souhaite adopter une approche différente et examiner les raisons historiques qui ont poussé notre équipe d'ingénierie à expérimenter et à faire évoluer continuellement notre structure, avec tous les faux pas et les apprentissages qui en découlent.
Remarque : Certains événements et détails ont été simplifiés pour les besoins du récit ; nombre d'entre eux méritent d'être publiés séparément. Ajoutez ce blog à vos favoris pour rester informé des nouveautés.
L'organisation cloisonnée
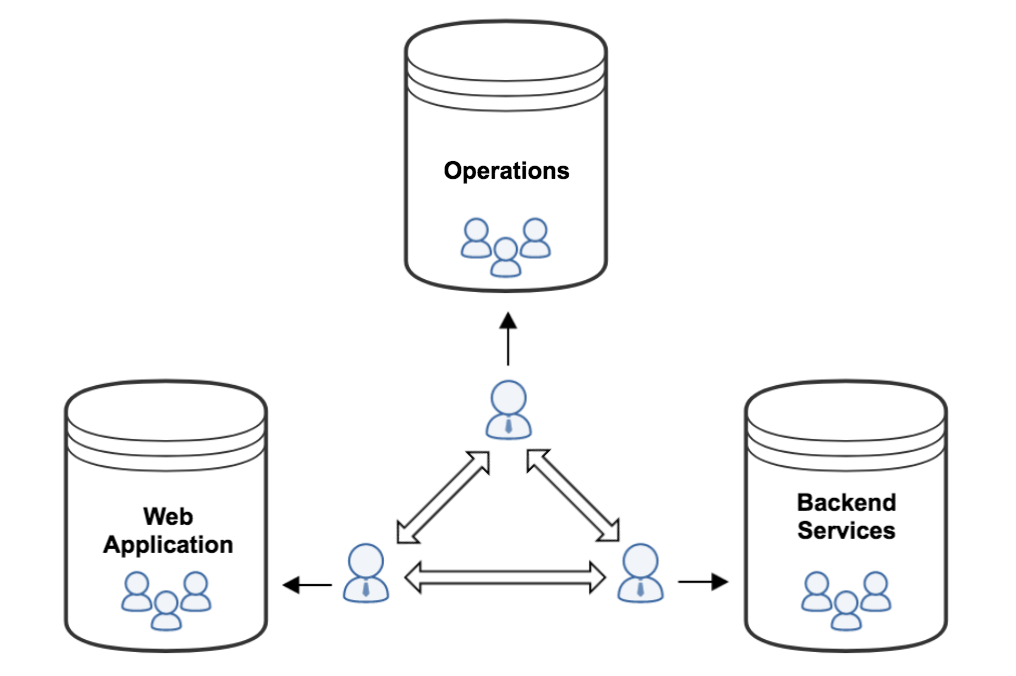
PagerDuty début 2014 ressemblait à ceci :
- L'organisation d'ingénierie a été divisée entre les bureaux de San Francisco et de Toronto.
- L'équipe des opérations était responsable de l'automatisation de l'infrastructure, de la sécurité et de la persistance (SF uniquement).
- L'équipe d'application Web était responsable des aspects client de PagerDuty (SF uniquement) et développée principalement avec Ruby on Rails et MySQL.
- Le groupe Backend Services était responsable de l'ingestion fiable des données et de la diffusion des notifications (divisé en équipes colocalisées à SF et à Toronto) et développé principalement avec Scala et Cassandra.
- Il n'y avait qu'une adhésion partielle à DevOps : l'équipe des opérations était de garde pour les alertes de surveillance de l'infrastructure, d'autres équipes sur appel pour le code qu'ils ont déployé .
Alors que l'ingénierie est passée d'une poignée de personnes à plusieurs équipes dispersées en très peu de temps, le processus de développement produit est resté relativement immature. Malgré des signes superficiels d'agilité avec des réunions debout et des sprints, nous utilisions essentiellement le Modèle de cascade La direction définissait les projets à réaliser, affectait les ingénieurs à ces projets et fixait les dates de livraison cibles. Comme on pouvait s'y attendre, ces dates étaient rarement respectées et les feuilles de suivi des projets étaient en perpétuel état de délabrement, voire de désuétude.
Sur le terrain, la situation n'était guère plus rose. Les chefs de produit lançaient les nouveaux projets en rédigeant de longs cahiers des charges fonctionnels, s'efforçant d'anticiper les éventuelles questions, conséquence du manque d'interaction entre les équipes Produit et Ingénierie pendant le développement ! Le cahier des charges était présenté aux équipes Applications Web et Services Backend, qui travaillaient ensuite indépendamment sur les aspects utilisateurs et backend. Les nouvelles demandes d'infrastructure devaient être adressées à l'équipe Opérations des semaines à l'avance.
Intégrer tous ces efforts distincts dans une version fonctionnelle cohérente a été un véritable cauchemar. Nous avions une infrastructure manquante ou incomplète, des bugs récurrents, des lacunes fonctionnelles (chaque équipe pensait que l'autre s'en occupait), un manque d'appropriation et de responsabilisation des ingénieurs et des équipes produit, des dates non respectées et des silos organisationnels. La volonté de respecter les délais nous a incités à prendre moins de risques et à adopter une approche plus conservatrice dans nos implémentations, tout en évitant d'ajuster les spécifications produit.
Cette combinaison de structure départementale et de processus de développement a propulsé le sujet du cloisonnement au cœur de toutes les discussions au sein de l'ingénierie cette année-là. Et quel cloisonnement !
- Application Web vs services back-end. La tension était palpable entre les deux groupes. Aucun des deux ne comprenait vraiment ce sur quoi travaillait l'autre, et tous deux étaient frustrés.
- Ruby contre Scala. Des lignes de conflit similaires à celles décrites ci-dessus, avec beaucoup de démantèlement de vélos et de construction identitaire autour de langues spécifiques.
- Équipes d'exploitation vs équipes de développement. Les deux parties étaient frustrées par le fait que l'équipe opérationnelle constituait un goulot d'étranglement pour le provisionnement de tous les serveurs. Les opérations subissaient également une forte pression liée à l'approche des échéances.
- San Francisco contre Toronto. Avec la colocalisation de toutes les équipes, une ambiance de « eux contre nous » s'est installée entre les ingénieurs des deux sites. Les deux camps ont trouvé matière à râler.
Les responsabilités rigoureusement définies ne laissaient guère de place à la collaboration interfonctionnelle entre les équipes. Nous avons brièvement expérimenté le concept de « groupes de travail » : de petites équipes temporaires et diversifiées, composées de membres des équipes existantes, pour travailler sur des projets transversaux, définis dans le temps et avec une portée limitée. Ces groupes ont fini par semer le chaos en déstabilisant les équipes principales, et l'expérience a donc été abandonnée.
Néanmoins, la nécessité de collaborer et de fournir des résultats plus cohérents et prévisibles était primordiale. Tout le monde en avait assez du cloisonnement, il fallait donc y mettre un terme. Nous avions du pain sur la planche.
L'organisation Matrix
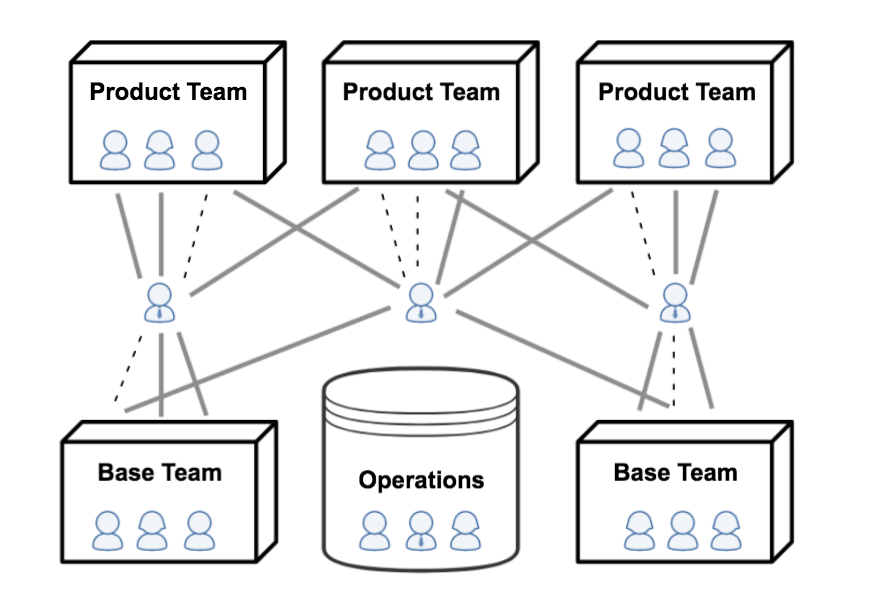 Début 2015, l'insatisfaction face à la situation actuelle et l'intérêt croissant pour les méthodologies Agile ont atteint un seuil critique et ont entraîné une restructuration des services. Plusieurs nouvelles équipes ont été constituées, alignées sur des orientations produit spécifiques. Elles suivaient le processus Scrum et étaient composées d'ingénieurs des équipes Applications Web et Services Backend, ainsi que de Product Owners, de Scrum Masters et de concepteurs UX.
Début 2015, l'insatisfaction face à la situation actuelle et l'intérêt croissant pour les méthodologies Agile ont atteint un seuil critique et ont entraîné une restructuration des services. Plusieurs nouvelles équipes ont été constituées, alignées sur des orientations produit spécifiques. Elles suivaient le processus Scrum et étaient composées d'ingénieurs des équipes Applications Web et Services Backend, ainsi que de Product Owners, de Scrum Masters et de concepteurs UX.
Compte tenu du rythme de progression du produit moins qu'optimal l'année précédente, les nouvelles équipes ont été optimisées pour la livraison du produit. Afin de leur permettre de consacrer 100 % de leur temps au développement de nouvelles fonctionnalités, les tâches de maintenance ont été déléguées aux équipes des services back-end. Celles-ci sont devenues les « équipes de base » à mesure qu'elles adoptaient Méthodologie Kanban et a pris en charge tous les services de production, y compris tous les produits responsabilités de garde . De plus, les équipes de base alimentaient les équipes de produits : les ingénieurs migraient de l’une à l’autre à mesure que le travail sur les produits augmentait.
Il s'agissait évidemment de changements majeurs. Afin de minimiser l'impact des remaniements d'équipe sur les ingénieurs (et de retarder la gestion des rapports à distance), les relations hiérarchiques n'ont pas été modifiées. Cela a évidemment énormément compliqué la vie de tous, car nous avions désormais une structure hiérarchique double, appelée « structure hiérarchique ». organisation matricielle ! De nombreux ingénieurs se sont retrouvés dans des équipes qui n’étaient pas affectées à leur supérieur hiérarchique direct et les managers jouaient désormais les rôles de « gestionnaire de personnes » (responsables de personnes, dont certaines étaient dans d’autres équipes) et de « gestionnaire fonctionnel » (responsable d’équipes, où certains ingénieurs rendaient compte ailleurs).
La bonne nouvelle, c'est que les anciens cloisonnements ont été pour la plupart brisés, et ne sont plus jamais revenus. Les ingénieurs d'applications web, travaillant en étroite collaboration avec les ingénieurs des services back-end, ont pu dépasser leurs différences et progresser vers des objectifs communs. La plupart des équipes étaient désormais géographiquement dispersées, ce qui a permis de rapprocher les deux bureaux.
La mauvaise nouvelle est qu’une série de nouveaux problèmes ont été introduits :
- Il était très difficile de fédérer une équipe autour de la maintenance technique. Les équipes de base ont eu du mal à élaborer des feuilles de route à long terme et à accepter la propriété opérationnelle de tous les services de production.
- Le modèle de recrutement a eu un impact très réel sur la cohésion de l’équipe Il s’avère que changer sans cesse la composition de l’équipe n’est pas très bon pour le moral.
- La structure de reporting double a créé de nombreuses inefficacités. Il y avait un manque de visibilité sur les activités quotidiennes d’un subordonné direct, des frais de communication supplémentaires entre les responsables du personnel et les responsables fonctionnels, et une confusion générale autour des responsabilités.
- Nous avons adopté des processus Agile plutôt que l'agilité Scrum a certainement contribué à la surspécification, à l'intégration et à l'implication des responsables produit. Cependant, notre approche de la livraison logicielle n'a pas changé : les versions de fonctionnalités restaient des opérations massives à la valeur douteuse.
- Plus d’équipes signifiaient plus de charge pour le personnel des opérations. Avec des demandes d’infrastructure fréquentes et des responsabilités d’astreinte supplémentaires pour chaque nouveau service, il est clair que cette approche n’était pas évolutive.
Tout bien considéré, nous étions encore en bien meilleure forme qu'il y a un an. Mais il restait encore beaucoup de chemin à parcourir.
L'organisation agile
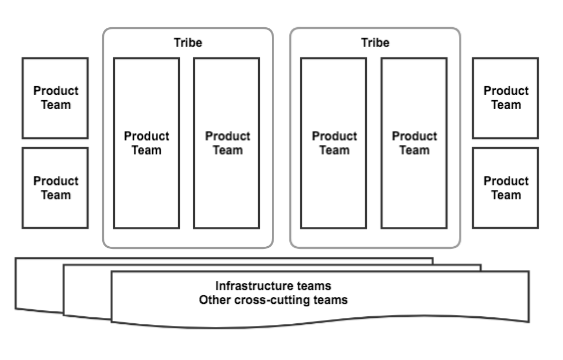 Après avoir vécu avec la nouvelle structure organisationnelle pendant un an, nous avons beaucoup appris. Agile était une bonne chose (mais nous ne l'avons pas suffisamment utilisé), DevOps était une bonne chose (mais nous ne l'avons pas suffisamment utilisé), la gestion matricielle était moins efficace (et nous en avions assez).
Après avoir vécu avec la nouvelle structure organisationnelle pendant un an, nous avons beaucoup appris. Agile était une bonne chose (mais nous ne l'avons pas suffisamment utilisé), DevOps était une bonne chose (mais nous ne l'avons pas suffisamment utilisé), la gestion matricielle était moins efficace (et nous en avions assez).
Début 2016, nous avons procédé à une nouvelle restructuration. Les équipes Scrum produit « verticales » étaient désormais responsables de segments spécifiques du produit. Les équipes « horizontales » étaient responsables des problématiques transversales liées au produit ou à l'infrastructure, et étaient chargées de définir les meilleures pratiques et de permettre aux autres équipes d'avancer rapidement. Les équipes de livraison produit étaient responsables de leur feuille de route, de la définition des exigences, de la mise en œuvre, du déploiement et de la maintenance de leur code et de leur infrastructure (!) en production. Nous avions adopté une véritable approche DevOps. vous le codez, vous le possédez ' approche.
Comment cela a-t-il résolu nos préoccupations précédentes ?
- Plus d'équipes de maintenance. Chaque équipe possédait une partie du produit ou de l’infrastructure et était habilitée à agir rapidement et à innover.
- Plus d'équipes nourricières. Le décompte a été ouvert pour des équipes spécifiques.
- Fini les doubles déclarations ! En tant qu'organisation, nous avons acquis une plus grande aisance avec le recrutement et la gestion d'ingénieurs à distance. La distance physique n'étant plus un obstacle, nous avons pu affecter des managers à des équipes sans lien hiérarchique.
- Nous nous concentrons sur l’accomplissement des tâches. Le mantra GSD (Get Sh*t Done) a imprégné notre conscience collective, mettant au défi les équipes d'introspecter et de se débarrasser de l'héritage de surspécification et de sur-ingénierie afin de devenir des machines de livraison pragmatiques, productives et agiles.
- Croissance facilitée par le libre-service. L'équipe des opérations a fait beaucoup de travail pour responsabiliser les équipes de livraison de produits, notamment en leur fournissant des fonctionnalités sophistiquées. Outils ChatOps pour répondre en libre-service à tous les besoins d'infrastructure. Cela a été essentiel pour adopter DevOps à tous les niveaux et transférer les alertes d'infrastructure des équipes Opérations vers les équipes concernées, propriétaires des hôtes (qui pouvaient de toute façon résoudre les problèmes plus rapidement).
Le sujet du GSD mérite d'être approfondi. Avec la pratique, nous sommes devenus de plus en plus à l'aise avec les notions d'autonomie en équipe. l'innovation plutôt que l'invention , et les entreprises qui apportent des problèmes à résoudre plutôt que des solutions à mettre en œuvre. Il est difficile d'abandonner l'idée que nous savons ce qui est le mieux pour les clients. Une concentration absolue sur la fourniture de produit minimum viable , et solliciter un feedback immédiat et l'intégrer tout au long du cycle de développement a été essentiel. Cela nous a permis d'itérer rapidement, de maximiser la valeur, de minimiser la sur-qualification et de raccourcir le délai de mise à disposition d'un prototype au client, passant de plusieurs mois à quelques jours, voire quelques semaines. En d'autres termes, nous sommes passés d'une organisation « appliquant des processus agiles » à une véritable organisation agile.
À mesure que le nombre d’équipes de livraison de produits augmentait, un phénomène intéressant s’est développé : nous avons assisté à l’émergence de ce que l’on appelle les « tribus » (merci à Le modèle d'équipe de Spotify ); c'est-à-dire des groupes d'équipes liées par des fonctionnalités ou une mission communes. Ces arrangements ont généré des avantages tels qu'une appropriation partagée, des connaissances partagées, une feuille de route commune (indépendamment des arriérés individuels des équipes) et une vision partagée. L'organisation tribale est une approche que nous expérimentons encore ; restez à l'écoute pour de futures mises à jour sur nos apprentissages avec les tribus.
Nous utilisons cette structure depuis 16 mois maintenant et elle fonctionne parfaitement. Les équipes et les structures de propriété associées évolueront certainement à mesure que l'entreprise poursuit sa croissance rapide, et certains détails changeront à mesure que nous investissons dans notre amélioration. Parallèlement, il est clair que nous avons commis suffisamment d'erreurs pour apprendre à adopter la bonne approche.
Leçons apprises
En repensant à certaines décisions prises au début et à certains des états intermédiaires difficiles que notre organisation a traversés, je suis tenté de me demander pourquoi il ne nous est pas venu à l'esprit de passer à l'état final, manifestement supérieur. La réalité, bien sûr, n'est jamais aussi simple : ces décisions étaient fonction de notre situation, de nos priorités, de nos collaborateurs et de nos défis. à l'époque Vous avez peut-être également reconnu certains de vos propres défis, auquel cas j'espère que vous pourrez tirer quelque chose de notre expérience.
Si je devais tout recommencer, voici les enseignements que j'emporterais avec moi :
- Minimiser les dépendances entre les équipes Les dépendances engendrent blocages, bugs, malentendus et ressentiments. Donnez à vos équipes les moyens de livrer sans attendre les autres et vous constaterez des gains de productivité considérables.
- Minimiser les changements dans la composition de l'équipe La réalité des affaires exige parfois des transferts de ressources. Réfléchissez bien avant de déplacer des personnes, car cela peut avoir un impact sérieux sur le moral et la productivité de l'équipe.
- Ne prescrivez pas trop de propriété et de responsabilités à l’équipe La flexibilité ici mène à des gains à long terme. Encouragez les équipes à résoudre leurs propres problèmes et vous aurez moins de difficultés avec les deux points précédents.
- N’ayez pas peur de l’apprentissage continu et de l’expérimentation Cela s'applique à tout : code, processus, organisation. On ne s'améliore pas en répétant sans cesse les mêmes choses.
- Les processus agiles sont bien, la culture agile est meilleure r. Les stand-ups et les revues de sprint n'apportent pas beaucoup de valeur en soi. Se concentrer sur le produit minimum viable, les boucles de rétroaction rapides et la collaboration nécessite un changement culturel, mais maximise la valeur client.
- Opérationnel la propriété du code doit appartenir aux équipes C’est le meilleur moyen d’équilibrer la fiabilité du système, la qualité du code et l’évolutivité organisationnelle.
- Les équipes interfonctionnelles et complètes sont idéales pour la livraison de produits Cela rejoint parfaitement le point de minimisation des dépendances mentionné précédemment. Chaque équipe devrait pouvoir passer de la collecte des exigences au déploiement sans avoir recours à des experts externes ni à des transferts de projet. Les équipes spécialisées ont certes leur place, mais davantage dans le cadre des équipes « horizontales » évoquées précédemment.
- Embauchez des généralistes qui peut fonctionner dans n'importe quel environnement. Les membres de l'équipe ne doivent pas s'attacher à des outils, frameworks et piles spécifiques, au gré des évolutions technologiques et techniques. Les personnes les mieux placées pour s'épanouir dans un environnement en forte croissance sont celles qui se concentrent sur l'apprentissage et l'utilisation de l'outil adapté à leur poste. Par conséquent, soyez prêt à offrir ces opportunités d'apprentissage et de développement.
- Évitez la gestion matricielle si vous pouvez l’éviter . Examinez s’il existe d’autres moyens de résoudre les problèmes que la double déclaration semble pouvoir résoudre.
- Adoptez les équipes distribuées Construire des équipes soudées avec des membres distants n’est pas sans défis, mais les avantages sont nombreux. Martin Fowler a souligné que, « En créant une équipe à distance, vous élargissez le cercle des personnes que vous pouvez intégrer. Une équipe à distance peut être moins productive que la même équipe colocalisée, mais peut tout de même être plus productive que la meilleure équipe colocalisée que vous puissiez former. « En d’autres termes, autoriser les membres à distance crée un bassin de recrutement beaucoup plus large, ce qui vous permet de constituer une équipe globale plus solide.
À mesure que les organisations grandissent et mûrissent, elles ont tendance à ralentir, à se figer et à devenir plus conservatrices. Grâce à l'amélioration continue et à l'évolution de nos pratiques, nous avons réussi à inverser la tendance et à gagner en agilité, pragmatisme et productivité au fil du temps ; vous pouvez faire de même.
Voici trois (et de nombreuses) années supplémentaires d’apprentissage !
Vous aimerez peut-être aussi ceux-ci...

