
- PagerDuty /
- Blog /
- Automation /
- Exploitez pleinement les métriques de valeur de votre automatisation de runbook avec Snowflake, Jupyter Notebooks et Python
Blog
Exploitez pleinement les métriques de valeur de votre automatisation de runbook avec Snowflake, Jupyter Notebooks et Python
par Justyn Roberts
5 janvier 2024 | 8 minutes de lecture
Ce blog a été co-écrit par Sebastian Joseph, consultant senior en solutions, PagerDuty, et Gabriel Ismael Felipe, ingénieur en automatisation.
L'automatisation est devenue un élément essentiel des pratiques commerciales des organisations modernes. Souvent, lorsqu'on entend parler d'automatisation, on l'imagine comme un moyen de supprimer l'aspect manuel du travail et d'accélérer les processus. Cependant, ce qui manque de visibilité, c'est la valeur et le retour sur investissement que l'automatisation peut apporter à une organisation, à une équipe, voire à un processus spécifique.
Comprendre la valeur dérivée des tâches automatisées et le retour sur investissement (ROI) de ces processus automatisés est une mesure essentielle pour la réalisation de la valeur, que ce soit en termes de temps gagné, d'erreurs évitées, d'atténuation des risques, de nombre d'exécutions, etc.
Avec PagerDuty Operations Cloud, les équipes sont en mesure de créer, de centraliser et d'exécuter l'automatisation à volonté, sans avoir à changer de contexte ou à apporter des modifications drastiques à leur ensemble d'outils, en grande partie grâce à notre vaste gamme de plus de 700 outils. écosystème d'intégration Dans ce blog, nous allons nous concentrer sur deux intégrations clés, Flocon de neige et Carnets Jupyter Comment collecter des informations sur le retour sur investissement lié à l'automatisation dans Pagerduty Process Automation et créer des rapports qui capturent cette valeur ? C'est parti.
Le paradoxe de la spirale de l'automatisation
Les équipes technologiques qui construisent et innovent au quotidien se retrouvent souvent prises dans la spirale infernale de l'automatisation des opérations et des processus. La conversation se déroule généralement ainsi :
- « Nous sommes trop occupés pour automatiser. »
- « Pourquoi sommes-nous trop occupés pour automatiser ? »
- « Nous avons toutes ces tâches ! »
- « Pourquoi ne pas automatiser ces tâches ? »
- « Nous sommes trop occupés pour prendre le temps d’automatiser ces tâches ! »
En montrant la valeur continue de l'automatisation à l'équipe élargie, nous pouvons briser ce cycle et montrer que nous ne pouvons pas nous le permettre. pas pour automatiser ce travail.
Dans ce blog, nous allons plonger dans deux différentes manières de procéder :
- Une intégration API de Pagerduty Automation et Snowflake : comment utiliser une intégration basée sur API de Pagerduty Automation et Snowflake pour capturer les données de retour sur investissement pour chaque exécution de tâche et créer un tableau de bord avec ces données dans Snowflake pour présenter la valeur du retour sur investissement de l'automatisation
- Créez d'autres intégrations ou des rapports personnalisés à l'aide de Jupyter Notebooks
Exploitez pleinement les indicateurs de valeur (ROI) de votre automatisation de runbook avec Snowflake
Pourquoi Snowflake ?
De nombreuses organisations utilisent Snowflake comme lac de données, et son tableau de bord permet de capturer et de représenter la valeur de l'automatisation. En utilisant conjointement Snowflake et PagerDuty Operations Cloud , les organisations peuvent améliorer l'efficacité opérationnelle de leurs données, minimiser les temps d'arrêt et établir une communication en temps réel avec les parties prenantes pour une gestion efficace des données.
Configuration du FLOCON DE NEIGE :
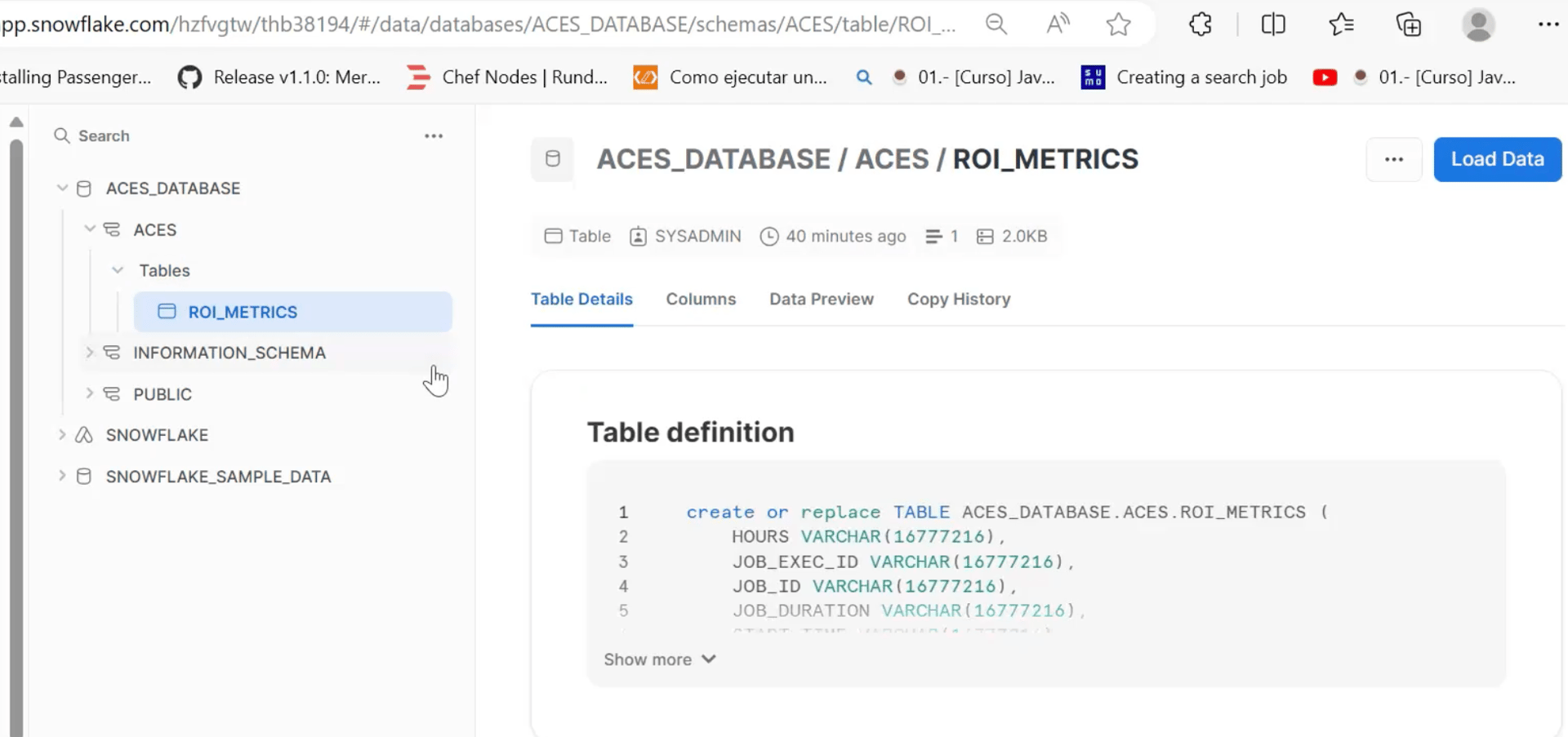
Définissons d’abord l’intégration de la sécurité dans Snowflake :

Nous pouvons ensuite définir la table et les champs de la feuille de calcul dans Snowflake. Voici quelques exemples d'instantanés et d'étapes :

Étapes de configuration de l'automatisation des processus PagerDuty :
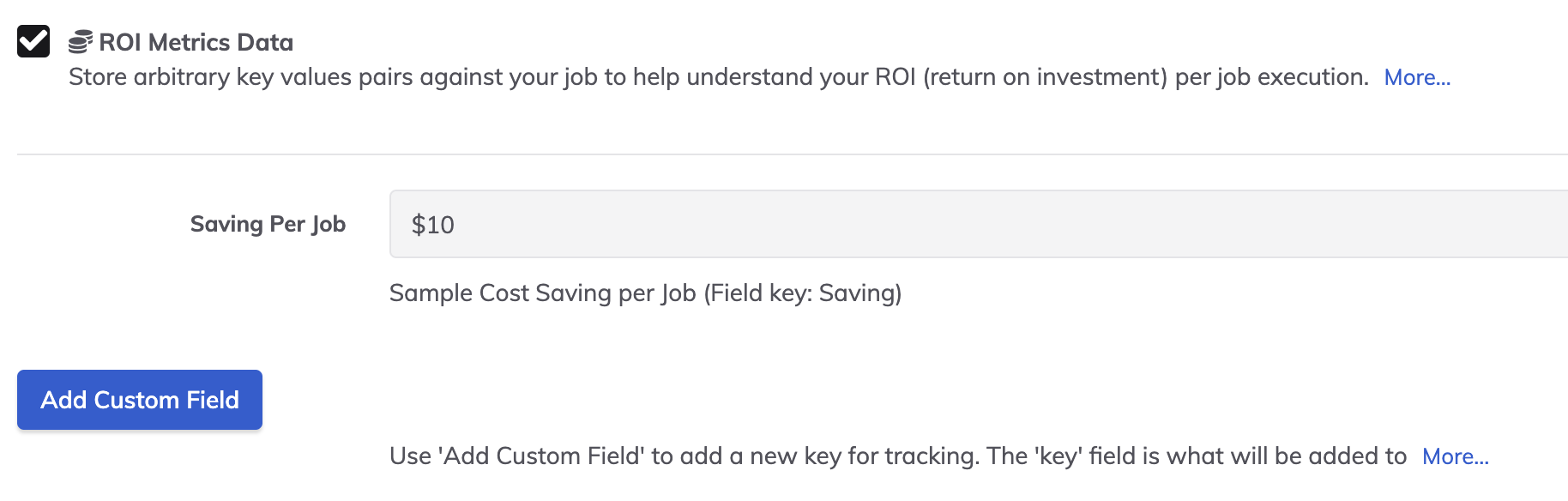
Marquez un travail pour la mesure et les valeurs en temps ou en revenus attachées à votre travail d'automatisation.
Chaque tâche peut avoir sa ou ses propres métriques. Dans cet exemple, supposons que la tâche économise 10 minutes de travail à un membre intermédiaire de l'équipe DevOps, soit 10 $ par exécution.
Plus d'informations détaillées dans le PagerDuty Documentation sur l'automatisation du Runbook.
Étapes détaillées :
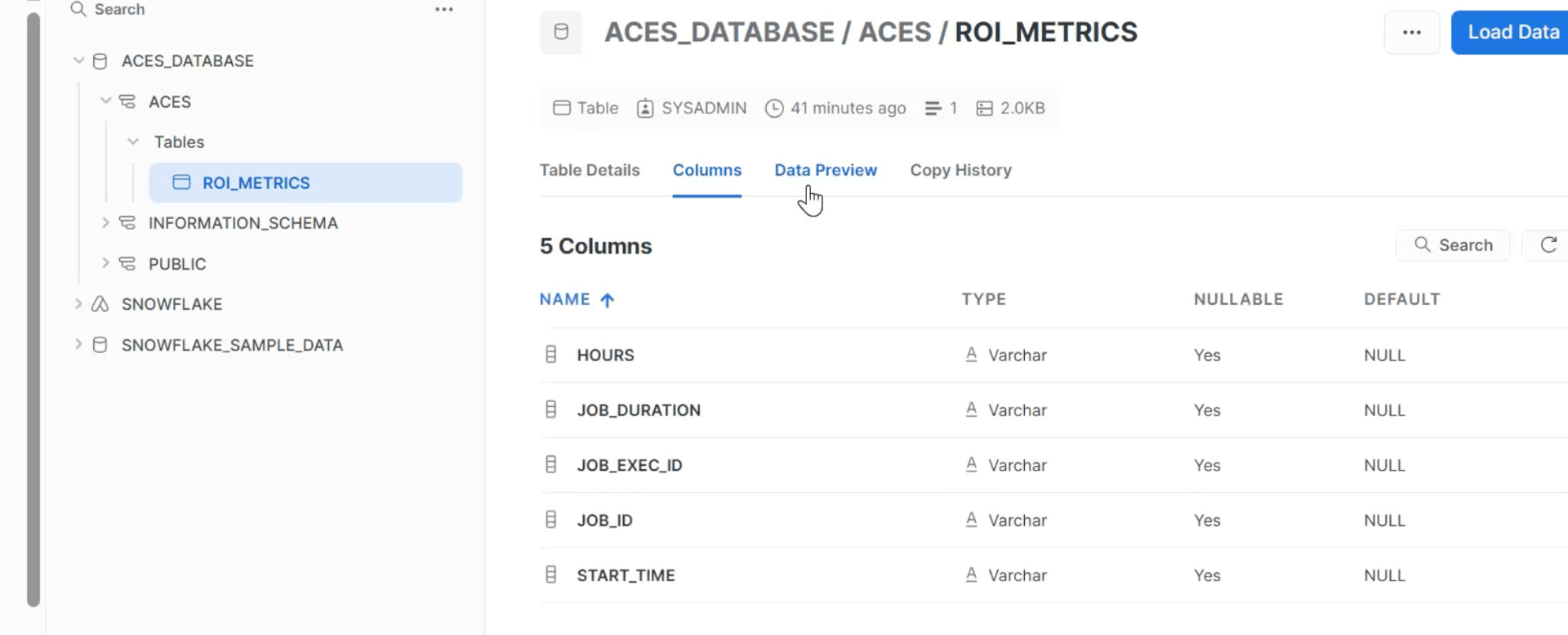
Nous utilisons les « indicateurs ROI » plugin Disponible dans la définition de tâche pour capturer les données « Heures économisées » lors de l'exécution d'une tâche d'automatisation. Cette option doit être définie manuellement pour la tâche en fonction du temps économisé grâce à l'automatisation.
Dans le Modifier plus du poste en automatisation des processus, cochez la case « Données sur les mesures du retour sur investissement ' drapeau. (Modifier le travail -> Plugins d'exécution -> Vérifier les données des métriques ROI (avec des informations valides « Heures économisées » renseignées, exemple : 1,25 heure).
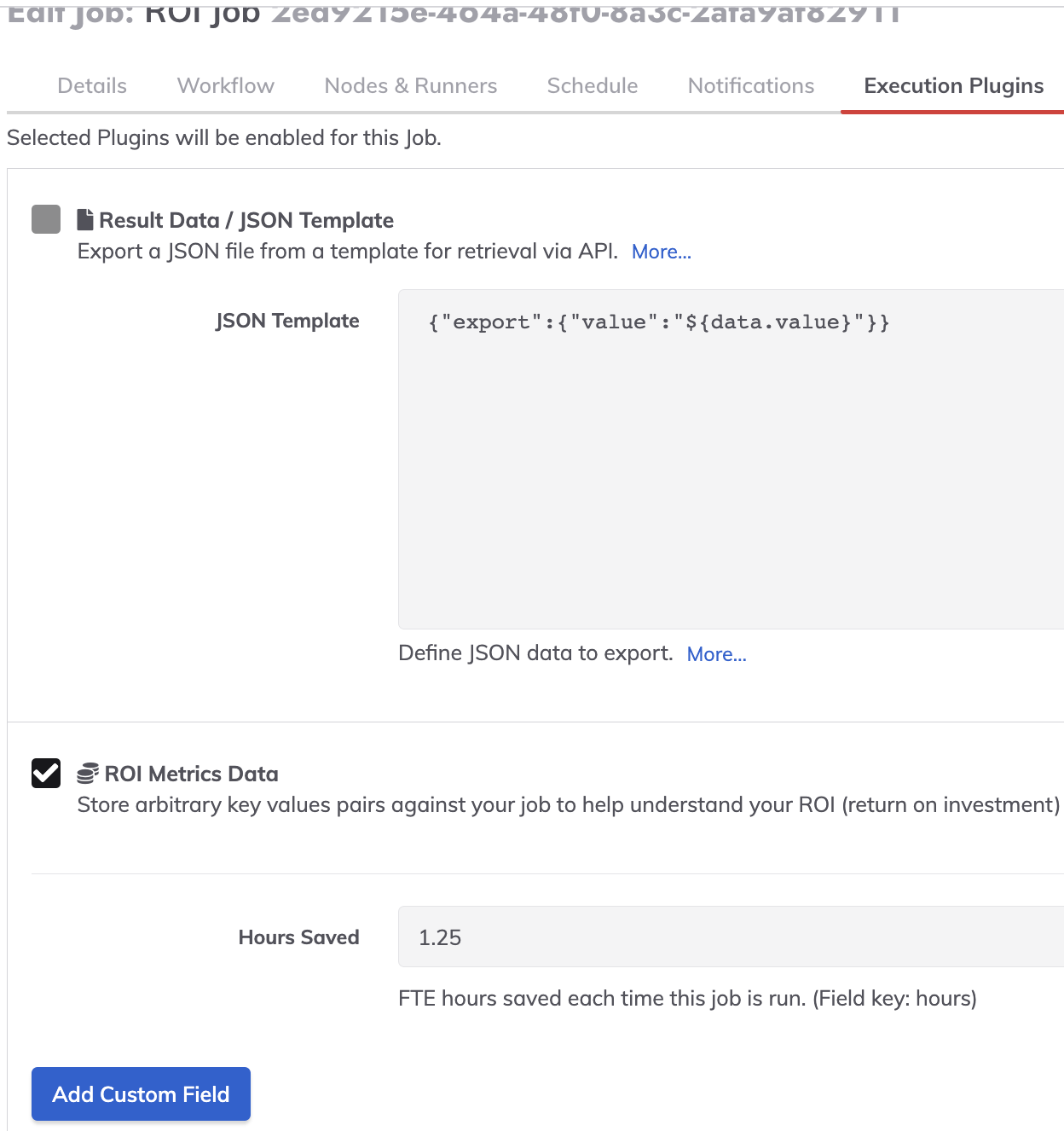
Ce qui précède fournira la sortie de données de métrique ROI suivante lorsque le travail s'exécute :
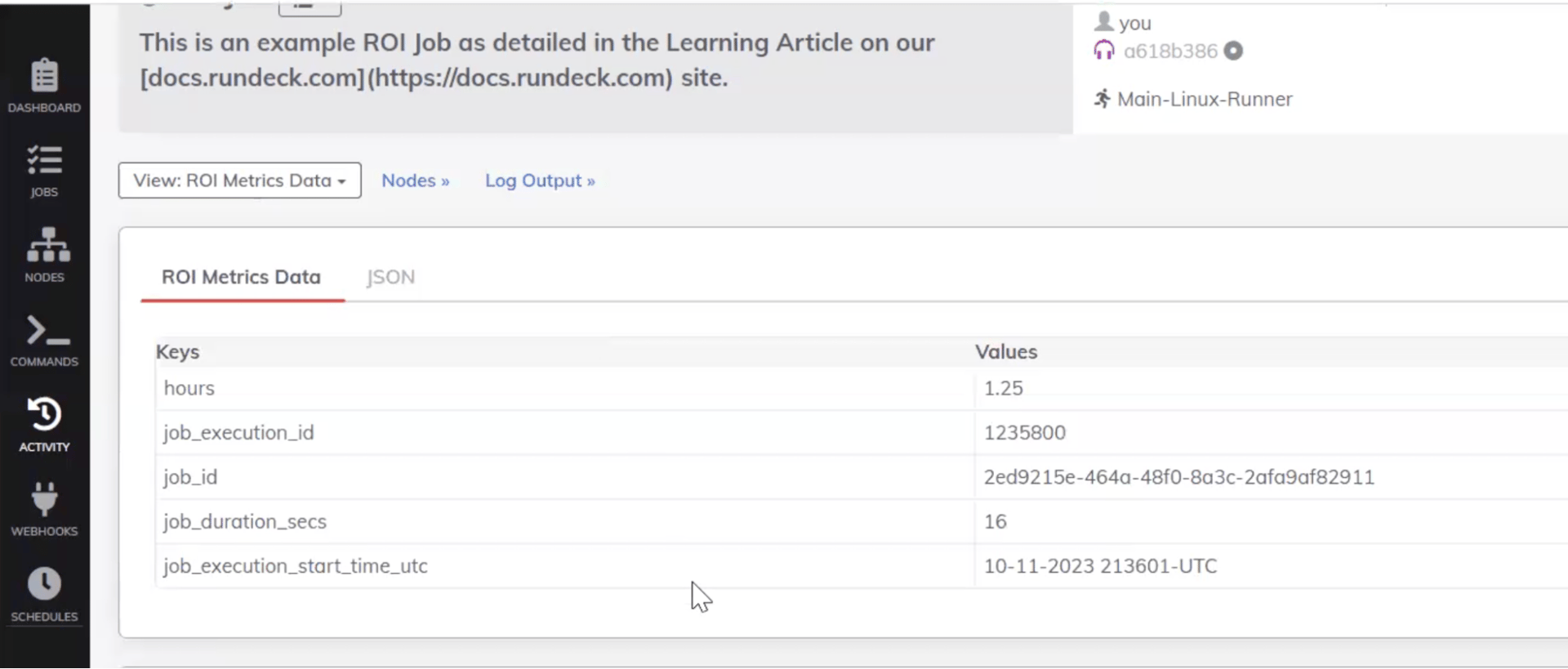
Ensuite, publiez les données ROI clé-valeur collectées dans l'étape de travail PA dans une base de données définie dans Snowflake à l'aide d'une méthode HTTP : Post et de l'instruction SQL intégrée.
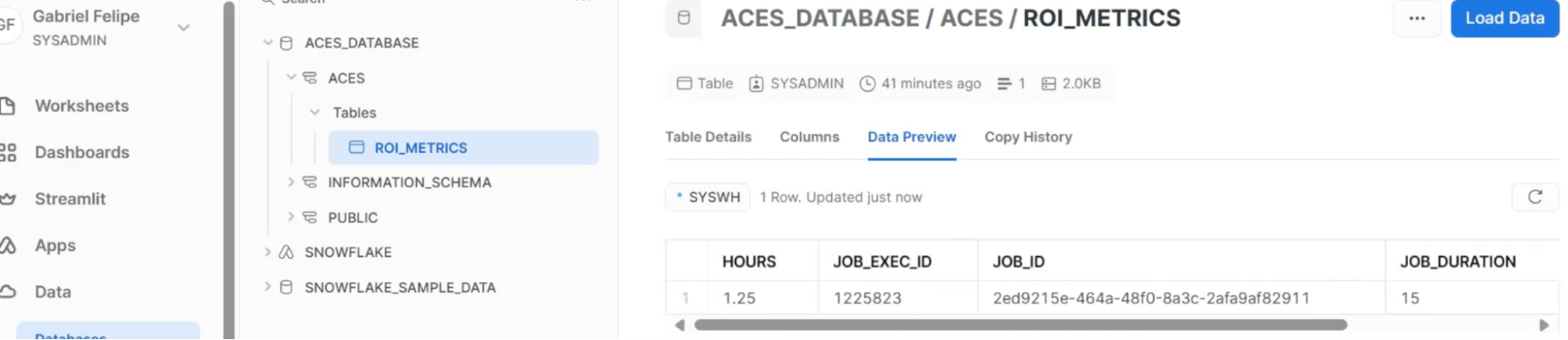
Sortie lors de la publication dans Snowflake (pour chaque exécution du travail, une ligne sera ajoutée avec la métrique) :
Métriques de valeur d'automatisation du runbook (ROI) à l'aide de Jupyter Notebook :
Pourquoi un Jupyter Notebook ?
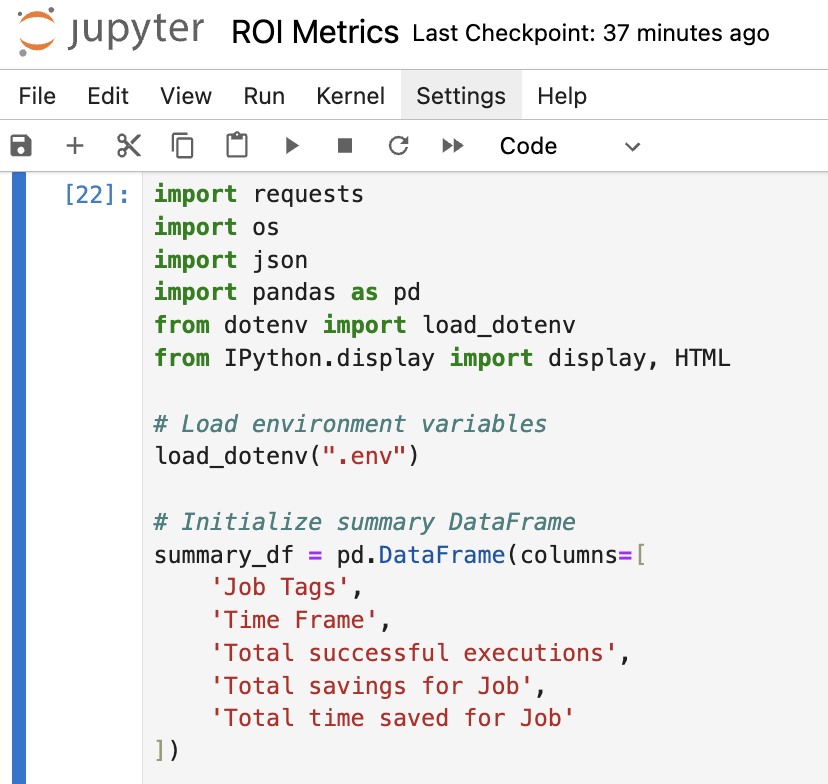
Les Jupyter Notebooks offrent un environnement informatique interactif permettant aux utilisateurs de combiner code, texte Markdown et rendus visuels. Ils sont donc idéaux pour l'analyse de données, le partage d'informations et même la distribution d'outils logiciels. Découvrons un script Python conçu pour extraire des indicateurs de retour sur investissement via l'API Runbook Automation. Nous verrons également comment distribuer cet outil sous forme de Jupyter Notebook, accompagné d'un fichier .env pour une configuration simplifiée.
L'exemple de code peut être modifié ou étendu pour s'adapter à vos environnements, notebooks, outils de business intelligence (BI) ou scripts planifiés. L'approche peut également être adaptée à votre langage préféré.
- 🔗 Installation de Jupyter Notebooks
- 🔗 Exemple de bloc-notes avec code fonctionnel
- 🔗 Exemple de modèle .env
Avant de commencer :
Les tâches devront être étiquetées pour collecter leurs propres mesures de retour sur investissement ( décrit ici ).
Chaque tâche peut avoir sa ou ses propres métriques. Dans cet exemple, supposons que la tâche économise 10 minutes de travail à un membre intermédiaire de l'équipe DevOps, soit 10 $ par exécution.
Plus d'informations détaillées dans le Documentation sur l'automatisation du Runbook
Concepts de base
Variables de configuration et d'environnement
Le fichier .env sert de base à la configuration de notre script. En distribuant ce fichier avec le Jupyter Notebook, les utilisateurs peuvent configurer leur environnement en toute sécurité et externaliser des fonctionnalités sensibles, comme la clé API requise.
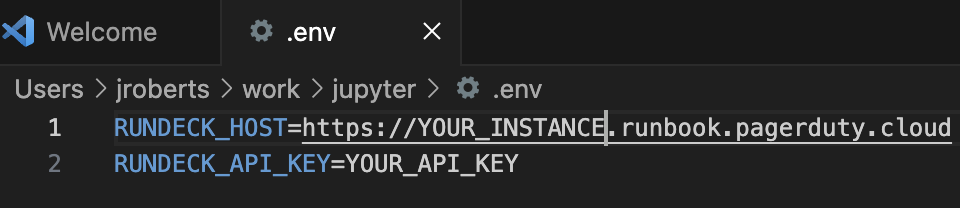
Autoriser la référence aux données de configuration dans le notebook :

Vous pouvez facilement modifier le carnet de notes pour le projet, les balises et l'historique (par exemple 1h, 24h, 1j, 14j).
Authentification et récupération des données de travail
L'authentification s'effectue via un jeton porteur, généré dans Runbook Automation et stocké dans le fichier d'environnement pour des raisons de sécurité.
Une fois authentifié, le flux dans le code ressemble à ceci :
- Grâce à l'API Runbook Automation, le script récupère une liste de tâches en fonction de balises spécifiques. Il renvoie ensuite la liste des identifiants de tâches par balise.
![]()
- Pour chaque ID, nous examinons la liste d'exécution du Job, renvoyant une liste d'ID d'exécution
![]()
- Enfin, nous parcourons les exécutions pour renvoyer les données ROI.

Agrégation et analyse des données
Toutes les données que nous collectons sont stockées dans un DataFrame Pandas, ce qui simplifie les analyses et les rapports ultérieurs. En raison de l'itération des données, le traitement de certains ensembles de données volumineux peut prendre un certain temps.
Résumer les métriques
Certaines modifications sont nécessaires pour traiter les valeurs de sortie comme des valeurs de temps ou d'Int, mais le code fourni doit être explicite.
Pour l'exemple, nous avons également ajouté le temps d'exécution total de chaque tâche réussie, au cas où une sorte de comparaison serait nécessaire « par rapport à une exécution manuelle d'une ou plusieurs tâches ».
Améliorations potentielles et modifications futures
- Gestion des erreurs : pour l'instant, le notebook ne dispose pas d'une gestion approfondie des erreurs, ce qui le rendrait plus robuste.
- Pagination : Actuellement, le script récupère jusqu'à 1 000 enregistrements d'exécution. L'implémentation de la pagination lui permettrait de gérer des ensembles de données plus volumineux.
- Visualisation des données : l’intégration de représentations graphiques des données fournirait des informations plus exploitables.
- Modifier pour exécuter plusieurs tâches et stocker sur une plateforme BI externe.
Conclusion et prochaines étapes
1. Ce Jupyter Notebook est un outil puissant pour collecter des indicateurs de retour sur investissement et évaluer vos processus automatisés. Fonctionnant tel quel, il peut devenir un atout indispensable à votre boîte à outils d'automatisation grâce à quelques améliorations.

2. Des indicateurs de retour sur investissement plus précis peuvent être collectés et un tableau de bord présentant les résultats peut être créé grâce à une intégration plus poussée des notebooks Jupyter et Snowflake. Jupyter Notebook est utilisé pour le calcul interactif avec Python.
3. Snowflake permet de capturer ces instantanés de ROI et de cumuler les valeurs dans plusieurs environnements, ainsi que d'afficher les données de ROI sur des périodes plus longues. Voici les étapes nécessaires pour effectuer une requête en Python via Jupyter Notebook et utiliser Snowflake :
- Connectez Jupyter Notebook à Snowflake (vous pouvez le faire en utilisant SnowCD et Python Connector, comme illustré dans l'exemple suivant : ( https://blogs.perficient.com/2020/06/06/integration-de-jupyter-notebook-avec-snowflake/ )
- Une fois cela fait, vous pourrez créer des tables, charger des données et effectuer des requêtes en utilisant Python via Jupyter Notebooks.
4. Maintenant que vous avez accès à ces données, elles peuvent être utilisées comme preuve auprès de la haute direction sur la valeur de l'automatisation, comme résumé quotidien pour vos utilisateurs d'automatisation ou comme partie de la valeur que vous restituez aux clients dans un environnement de service géré.
Nos équipes Services sont également en mesure d'intervenir sur toutes tâches spécifiques liées aux données et à la personnalisation.
Quelle est la prochaine étape ?
PagerDuty Automation continuera d'améliorer les capacités de capture du retour sur investissement de sa plateforme d'automatisation. L'objectif est de mettre en avant les différentes façons dont l'automatisation contribue à l'efficacité, à la réduction des risques, aux économies de coûts et à d'autres aspects où l'automatisation est source de valeur. Nous tiendrons ce blog à jour au fur et à mesure du déploiement de ces fonctionnalités.
Un moyen efficace de démontrer l'impact de l'automatisation et de la placer au cœur de la transformation numérique de l'organisation est de diffuser les données de retour sur investissement et les tableaux de bord à la direction afin qu'elle puisse comprendre et exploiter la valeur ajoutée de l'automatisation. Les données parlent d'elles-mêmes, et PagerDuty simplifie la capture des données pertinentes dans la plateforme d'automatisation à chaque exécution.
Amusez-vous!

