
- PagerDuty /
- Blog /
- Gestion et réponse aux incidents /
- 6 étapes essentielles pour réduire le temps de résolution des incidents
Blog
6 étapes essentielles pour réduire le temps de résolution des incidents
par Michael Churchman
13 octobre 2016 | 7 minutes de lecture
Qu'est-ce que le délai de résolution ?
Le délai de résolution (TTR) ou délai moyen de résolution (MTTR) désigne le temps moyen nécessaire pour résoudre un ticket ou une demande de service client une fois ouvert. Lorsqu'un client ou un utilisateur contacte votre équipe suite à un problème rencontré avec votre service, il est important de minimiser le MTTR afin de garantir une expérience optimale avec un temps d'arrêt minimal. Par exemple, imaginons qu'un client vous appelle pour signaler un problème avec votre produit. Le TTR démarre dès l'interaction et s'arrête une fois la résolution obtenue. Plus le délai de résolution est court, plus le client est satisfait.
Le TTR peut être calculé pour différents employés et différentes catégories d'incidents afin de mettre en évidence les tendances et les axes d'amélioration. L'objectif doit toujours être de minimiser le temps nécessaire à la résolution d'un problème afin que les clients puissent utiliser correctement votre service avec le moins de perturbations possible.
« Comment réduire le temps de résolution des incidents ? Nos délais moyens de résolution (MTTR) nous freinent ! »
Si vous vous posez cette question à cor et à cri, vous n'êtes pas seul. Il s'agit d'un problème de support chronique. Comment réduire le temps de résolution des incidents ? Il s'avère qu'il existe des solutions très efficaces et judicieuses. Nous les examinerons dans cet article.
Des métriques, des métriques, des métriques
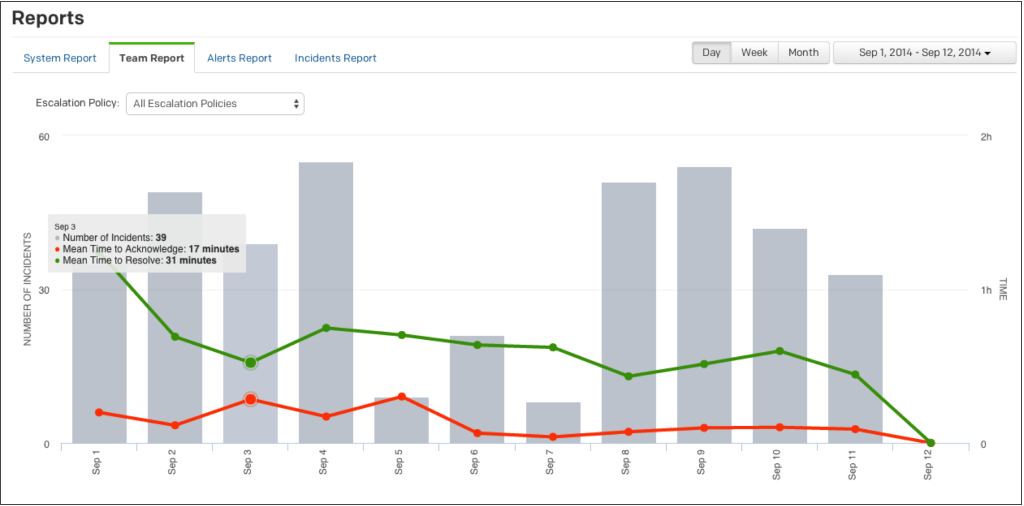 Avant tout, il est important de comprendre la manière dont les mesures sont utilisées pour évaluer la résolution des incidents et de décider quels aspects de ces mesures comptent le plus pour vous.
Avant tout, il est important de comprendre la manière dont les mesures sont utilisées pour évaluer la résolution des incidents et de décider quels aspects de ces mesures comptent le plus pour vous.
La mesure la plus élémentaire du temps de résolution est, bien sûr, MTTR (temps moyen de résolution) C'est un de ces indicateurs que la haute direction apprécie car il condense tout en un chiffre clair et simple. Malheureusement, c'est aussi un de ces chiffres qui peuvent s'avérer aussi simple, en extrayant les informations importantes et en ne laissant qu'une moyenne presque dénuée de sens.
Le MTTR global (couvrant la réponse à tous les incidents) est une mesure fiable si les données ne sont pas influencées par trop de valeurs aberrantes et si elles reposent sur un large spectre d'incidents s'inscrivant parfaitement dans une courbe en cloche. En revanche, s'il existe deux groupes d'incidents distincts, représentant deux types de problèmes différents avec des délais de résolution très différents, le MTTR peut être trompeur. Étant donné que les courbes en cloche larges incluent souvent des valeurs aberrantes anormales, le MTTR global à l'échelle du système peut ne pas être une mesure fiable du tout.
Si vous avez le choix en matière de métriques, quelles sont les alternatives au MTTR global ? Voici quelques recommandations :
- MTTR distincts pour chaque classe d'incident : Si vous pouvez définir des classes d'incidents spécifiques, vous pouvez utiliser des MTTR distincts pour chaque classe. Cela peut être très utile si les incidents concernés se divisent naturellement en classes distinctes. Mais ne cédez pas à la tentation de concevoir des classes d'incidents artificiellement juste pour avoir des MTTR fiables à présenter lors de la prochaine réunion.
- Pourcentage résolu : Vous pouvez également consulter le pourcentage de résolutions dans un délai cible ou le pourcentage de non-résolutions après un délai défini. Cela vous permet de mesurer le temps de résolution par rapport à un objectif et d'ajuster vos pratiques de gestion des incidents afin d'atteindre cet objectif.
- Nombre total d'incidents et durée cumulée des incidents : Cependant, pour que les chiffres du MTTR ou du délai de résolution cible soient pertinents, il est nécessaire de prendre en compte le nombre total d'incidents et la durée cumulée des incidents sur une période donnée. Pourquoi ? Examinons le tableau A ci-dessous. Deux services informatiques différents surveillent et mesurent les incidents de la même manière. En se basant uniquement sur le pourcentage d'incidents dépassant le délai cible et le MTTR, le service informatique B est clairement le gagnant. Sans tenir compte du nombre total d'incidents réels et de leur durée cumulée, il est trop facile de comparer des statistiques erronées.
Tableau A : Gestion des incidents et MTTR
| Département informatique | nombre d'incidents par mois | # incidents dépassant temps cible | Cumulatif heure de l'incident | % d'incidents dépassant temps cible |
MTTR |
| UN | 3 | 1 | 4,5 heures | 33,33% | 1,5 heure |
| B | 35 | 10 | 26,25 heures | 28,57% | 0,75 heure |
Gardez vos chiffres bas
Quelle que soit la façon dont vous mesurez le temps de résolution, la seule constante est la nécessité (généralement accompagnée de pression de la part de la direction) de le maintenir à un niveau bas. Que pouvez-vous faire ?
Plusieurs mesures peuvent être prises et, mises en œuvre ensemble, elles peuvent avoir un impact positif. Voici six étapes essentielles à mettre en œuvre dès maintenant :
- Utilisez un système de gestion des incidents rapide et précis.
Une réponse commence par votre système de gestion des incidents. Comment votre équipe d'intervention reçoit-elle les alertes ? Reçoit-elle des appels téléphoniques et des courriels des utilisateurs finaux pendant les heures de bureau ? Ce type de système convient parfaitement aux problèmes non prioritaires et aux demandes de fonctionnalités. Vous avez besoin d'un système automatisé de gestion des incidents qui avertira immédiatement les responsables de l'équipe d'intervention concernés par le biais de moyens de communication multicanaux (appels téléphoniques, SMS, courriels ou tout autre système de communication rapide) dès qu'un incident est détecté ou signalé. Les incidents doivent être acheminés aux responsables d'équipe appropriés afin d'éviter toute confusion ou tout malentendu quant à la responsabilité de leur gestion. - Réduisez le bruit des alertes et filtrez les non-alertes.
Filtrez et limitez le bruit des alertes dès le départ, afin que les équipes d'intervention ne soient pas accablées par des incidents de faible priorité, ou pire encore, des incidents non prioritaires qui n'ont pas été filtrés avant leur intervention. Ces fonctions doivent être intégrées à votre système d'alerte et de répartition et peuvent être largement automatisées. - Gardez les délais d’accusé de réception des incidents courts.
Cela implique à la fois le système d'alerte et les équipes d'intervention. En l'absence de confirmation d'un incident après un délai défini (et très court), celui-ci doit être automatiquement transmis à un deuxième membre de l'équipe, puis à un troisième, etc. Si aucun membre de l'équipe n'a confirmé l'incident, celui-ci doit être transmis à une deuxième équipe (ou à la direction informatique). Les incidents ne doivent pas être laissés en suspens indéfiniment, sans confirmation. - Établissez des priorités dès le départ .
Définissez une priorité claire, basée sur des éléments tels que la gravité et l'étendue de l'incident, les systèmes affectés et leur impact sur les opérations de l'entreprise. Cela peut avoir un effet mitigé sur votre MTTR, mais en commençant par identifier clairement les incidents nécessitant une attention particulière et ceux qui peuvent attendre, vous réduirez les pertes de temps et, in fine, les délais de résolution. - Utilisez la collaboration en temps réel.
Si nécessaire, mobilisez des équipes spécialisées et des ressources de soutien aux moments cruciaux de la résolution de l'incident. Une collaboration en temps réel via les médias appropriés (par exemple, VPN, vidéo en direct, SMS et voix) peut faire toute la différence entre une résolution rapide et immédiate et l'attente d'un e-mail le jour ouvrable suivant. - Mettre en place des équipes d’intervention avec des rôles clairs.
La réponse aux incidents ne doit jamais être improvisée. Chaque équipe doit avoir un responsable et tous ses membres doivent être clairement informés des responsabilités de chacun. La communication, tant au sein de l'équipe qu'avec les parties prenantes externes, doit être claire et ouverte.
Il existe de nombreuses autres mesures que vous pouvez mettre en œuvre pour réduire le temps de réponse. Par exemple, pour les grandes organisations, un système de commandement formel avec des exercices d'intervention peut être approprié. En suivant les directives ci-dessus, vous devriez pouvoir réduire le temps moyen de réponse (MTTR) de votre équipe informatique à un niveau qui ne vous laissera pas tomber.

