
- PagerDuty /
- Blog /
- Meilleures pratiques et perspectives /
- Améliorer au-delà du MTTR avec PagerDuty Analytics
Blog
Améliorer au-delà du MTTR avec PagerDuty Analytics
par Murs de Mandi
2 janvier 2024 | 8 minutes de lecture
Améliorer au-delà du MTTR
Nous avons publié un article sur l'ambiguïté autour du MTTR avant , mais nous voulons approfondir la confusion et peut-être le faux sentiment de sécurité que provoque notre dépendance au MTTR, d'un point de vue qualitatif et quantitatif.
Nos amis de la VIDE nous avons également abordé le MTTR du point de vue où nous ne pouvons souvent pas identifier de manière concluante la partie temporelle ; nous suivons le temps à partir du moment où une alerte est reçue ou peut-être à partir du moment où un client signale un problème, mais ces méthodes ne sont aussi bonnes que nos métriques et nos canaux de reporting client le permettent.
Si nos objectifs sont d'accroître notre fiabilité et de réduire notre MTTR global, nous pourrions constater que ce dernier ne nous fournit pas toutes les informations nécessaires à notre amélioration. Si vous aimez les simulations de Monte-Carlo (et qui ne les aime pas !), ce papier Google explore certaines faiblesses du MTTR avec les mathématiques. Beaucoup de mathématiques.
Être méchant envers la méchanceté
Vous avez probablement appris à l'école les statistiques récapitulatives comme la moyenne, le mode et la médiane d'un ensemble de valeurs. Le mode est vraiment étrange ici : c'est la valeur qui apparaît le plus souvent. La médiane est la valeur médiane de l'ensemble lorsqu'elle est classée par ordre numérique, et la moyenne est la moyenne de toutes les valeurs.
Nous utilisons assez souvent la moyenne en réponse aux incidents. Votre équipe peut suivre vos temps moyen pour reconnaître en plus de votre temps moyen de récupération/réparation/résolution Lorsque nous réfléchissons à la moyenne d'un ensemble de nombres, nos exemples de cours d'algèbre préférés sont des choses comme « la moyenne des notes d'un examen d'histoire » ou « la température moyenne dans notre ville ce mois-ci ». Ces nombres se situent déjà dans une plage bien définie, avec des bornes supérieures et inférieures raisonnables. Ils sont très utiles pour les ensembles avec un normale distribution.
Ce qui est fou avec votre temps de résolution, c'est qu'il n'y a pratiquement pas de limite supérieure ; en fonction des limites que votre équipe fixe pour le MTTR, les incidents peuvent durer pratiquement indéfiniment, ce qui rend le MTTR... étrange.
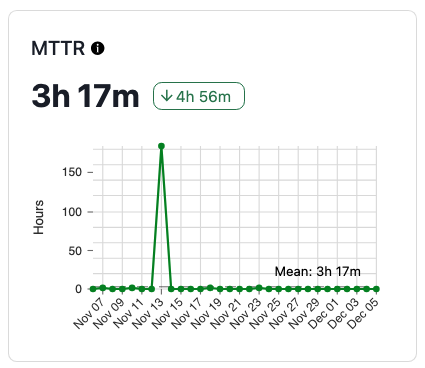
Les statistiques récapitulatives sont utiles pour extraire les caractéristiques d'un ensemble de valeurs, mais dès que ces valeurs commencent à dépasser leurs limites, il faut prendre des décisions sur l'utilité d'aspects comme la moyenne, ou éventuellement décider comment gérer les anomalies. En cas d'incident logiciel, les anomalies peuvent être tout à fait légitimes ; les équipes peuvent attendre l'approbation et le déploiement d'un travail, ou la publication d'un correctif par un fournisseur en amont.
Pour d’autres données dans le domaine de la fiabilité, l’industrie a évolué vers des mesures plus robustes et plus utiles des données qui pourraient être dans un biaisé ou multimodal distribution. Peut-être que vous examinez certaines de vos données en fonction de percentiles au lieu de moyennes. Cela vous en dit plus sur la forme des valeurs elles-mêmes et sur la probabilité d'une valeur « mauvaise » pour le point de données choisi.
Pour la qualité, pas la quantité
Le MTTR peut être un indicateur difficile à améliorer pour de nombreuses équipes travaillant dans des environnements complexes, car il ne s'agit pas d'une mesure unidimensionnelle et uniforme. C'est souvent un instrument approximatif, mais pour les équipes sans expérience en gestion des incidents, c'est un bon point de départ. Une fois les mécanismes de vos workflows de réponse aux incidents maîtrisés, certaines de ses faiblesses commencent à apparaître.
Je pense aux résultats de l'examen d'histoire mentionné plus tôt. Tous les élèves de la classe ont passé le même examen ; ils avaient probablement accès aux mêmes cours et supports avant l'examen. Si certains élèves souhaitent améliorer leur score au prochain examen, ils étudieront davantage. Que devrait faire votre équipe pour améliorer votre MTTR ? Pouvez-vous étudier davantage ?
De plus, nous espérons que vous ne résolvez pas le même problème à plusieurs reprises lors de vos incidents. Nous souhaitons que les gens apprendre des incidents et exploiter ces enseignements pour améliorer la fiabilité de leurs services. De plus, de nombreux autres facteurs modifient l'environnement de vos services : habitudes d'utilisation des clients, nouveaux codes et fonctionnalités, autres changements. Il est très difficile de dire que l'incident 150 de ce mois est identique à l'incident 120 du mois dernier, mais qu'il a pris moins de temps, car les circonstances de l'environnement ne sont jamais les mêmes.
Comprendre ce qui se passe dans un système complexe afin de remédier à un incident peut être un processus complexe, impliquant plusieurs systèmes et équipes. Comparer le temps de récupération de chaque incident survenu par un service sur une période donnée ne vous en dira pas beaucoup sur son comportement. Les incidents complexes sont multidimensionnels, et ce que nous en savons est important pour nous améliorer et en tirer des leçons.
Une grande partie de la discussion qualitative autour d'un incident devrait être abordée lors de l'examen post-incident, mais si vous recherchez des données de tendance pour montrer des améliorations, il existe des moyens de découper et de segmenter vos incidents pour avoir une meilleure vue d'ensemble et donner à vos équipes des conseils sur ce qui doit être amélioré.
Devez-vous prendre la peine de mesurer le MTTR ?
Nous constatons que de nombreuses équipes qui utilisent PagerDuty sans plan de gestion des incidents améliorent considérablement leur MTTR en peu de temps. La résolution des incidents repose en grande partie sur la mobilisation des équipes, l'automatisation et la communication. Pour ceux qui ne maîtrisent pas encore ces outils, la mise en place de bons outils est un premier pas vers une solution. Enregistrer les améliorations du MTTR est un excellent point de départ pour ces équipes.
Une fois que votre équipe utilise efficacement un workflow de réponse aux incidents, se concentrer uniquement sur le MTTR ne suffira probablement pas à améliorer la fiabilité de votre service. Votre MTTR pourrait tout à fait rester le même, augmenter, voire diminuer si vous… doublé Le nombre d'incidents sur un service, mais l'ensemble de données présentait la même plage (l'article de Google présente un exemple de ces scénarios). Vos utilisateurs ressentiraient certainement une baisse de fiabilité si le nombre d'incidents augmentait. Le MTTR ne peut pas révéler cette variation de fiabilité globale. L'utilisation d'une moyenne atténue trop les détails.
Il existe d'autres informations que vous pouvez consulter, dont beaucoup sont incluses dans l'offre Analytics de PagerDuty, dans le cadre de Connaissances Rapports. Ils vous aideront à analyser en profondeur les autres dimensions de vos incidents, mais nécessiteront une attention particulière à l'hygiène des données.
Un bon point de données sur lequel les équipes doivent se concentrer est de s’assurer que les incidents reçoivent une priorité.
Priorités
Dans votre compte PagerDuty , vous avez la possibilité de définir un ensemble de priorités qui correspondent à vos objectifs de fiabilité. Votre équipe peut déterminer les niveaux de priorité, comme le pourcentage de clients impactés, la durée d'un incident ou d'autres heuristiques pertinentes.
La priorité n'est pas automatiquement attribuée à un incident ; certaines équipes utiliseront les données d'alerte pour déterminer la priorité via Orchestration d'événements D'autres équipes mettront à jour manuellement la priorité au fur et à mesure de l'incident. D'autres équipes peuvent attendre la résolution de l'incident et mettre à jour la priorité rétroactivement afin de mieux refléter l'incident.
Le fait d'attribuer des priorités à chaque incident auquel votre équipe répond vous permet de voir comment votre équipe se comporte sur les incidents les plus impactants, et vous pouvez utiliser la priorité comme filtre sur l'écran Insights, et les données récapitulatives vous montreront des données récapitulatives et des tendances pour les priorités les plus importantes.
Cela vous permet d'analyser l'hétérogénéité de vos incidents et de vous concentrer sur ceux qui intéressent le plus vos utilisateurs. Si votre équipe est confrontée à de nombreux incidents de faible priorité et de courte durée, votre MTTR ne vous renseignera pas sur le nombre plus restreint d'incidents de haute priorité.
Surveiller le nombre d'incidents hautement prioritaires sur les services destinés aux utilisateurs, combiné à un ensemble de mesures axées sur l'utilisateur SLO , peut aider votre équipe à établir des repères et à prendre de meilleures décisions. Si un service a subi trop d'incidents SEV-1 impactant les clients au cours des 30 derniers jours, et que le SLO est proche d'être dépassé, les équipes de développement peuvent prendre la décision éclairée de geler les versions ou de prioriser les fonctionnalités liées à la fiabilité afin de rétablir la fiabilité du service.
Résumé
Suivre votre MTTR peut être utile pour évaluer les améliorations apportées par votre équipe lors du déploiement d'un nouveau workflow de réponse aux incidents. Les équipes plus expérimentées peuvent tirer davantage de bénéfices d'une analyse plus approfondie de leurs données d'incident, et PagerDuty Analytics peut vous aider. Pour plus d'informations et découvrir les dernières fonctionnalités d'Analytics, consultez notre chaîne YouTube où nous avons publié quelques-unes des dernières fonctionnalités ! Pour en savoir plus, consultez le Connaissances et le nouveau Tableau de bord d'analyse avec notre équipe produit !
Vous aimerez peut-être aussi ceux-ci...

