
- PagerDuty /
- Blog /
- Meilleures pratiques et perspectives /
- Rétrospective Asie-Pacifique : Leçons tirées d’une année de pannes technologiques, Restauration : Réparation ou cause profonde
Blog
Rétrospective Asie-Pacifique : Leçons tirées d’une année de pannes technologiques, Restauration : Réparation ou cause profonde
par David Ridge
22 janvier 2024 | 7 min de lecture
Notre exploration de l'année 2023 se poursuit à partir de troisième partie de notre série de blogs, Démantèlement des silos de connaissances , Un fait demeure indéniable : les incidents sont une réalité inévitable pour les organisations, quels que soient leur secteur d’activité ou leur taille.
Les tendances récentes en Asie-Pacifique montrent que les organismes de réglementation durcissent le ton envers les grandes entreprises en cas de mauvaise prestation de services, leur infligeant de lourdes sanctions en raison des conséquences négatives. Les enjeux d'un incident ne se limitent plus à une simple perte de revenus et à une érosion de la confiance ; ils incluent désormais des amendes substantielles et des restrictions d'exploitation.
Face à une multitude de perturbations, allant des pannes techniques majeures aux défaillances des services cloud en passant par les risques de cybersécurité, les entreprises d'aujourd'hui doivent se préparer stratégiquement à la gestion des incidents. Dans ce quatrième volet, nous poursuivons notre exploration des étapes critiques du cycle de vie d'un incident, en fournissant aux organisations les clés pour se préparer à ce qui est désormais inévitable : leur prochain incident.

Partie 4 : Restauration : Réparation ou cause profonde
Dans le contexte actuel des systèmes complexes, le débat entre la priorité donnée à la restauration du service et la résolution de la cause profonde d'un incident persiste. Trouver le juste équilibre est crucial. Une restauration immédiate du service protège l'entreprise des pertes financières et préserve la satisfaction client. Des procédures de restauration standardisées et automatisées sont essentielles à cet égard. Une définition claire de la notion de « Résolu » est indispensable pour des indicateurs fiables et une gestion efficace des incidents, mais la possibilité de filtrer et d'ajuster la granularité d'indicateurs tels que le MTTR est nécessaire pour garantir leur exactitude et leur utilité.
Lorsqu'une panne informatique survient, la priorité absolue est le rétablissement rapide des services. L'année dernière, nous avons constaté à quel point les interruptions de service peuvent engendrer des pertes financières considérables, nuire à la réputation d'une marque et perturber le service client. Dans ces situations critiques, l'attention se porte non plus sur l'analyse de la cause première, mais sur la remise en service rapide des systèmes affectés. La philosophie sous-jacente est simple et repose sur quelques principes fondamentaux :
- La disponibilité, c'est de l'argent Dans notre monde numérique, la disponibilité des services est étroitement liée au chiffre d'affaires. Plus les interruptions de service se prolongent, plus l'impact financier sur l'organisation est important. Le rétablissement du service permet à l'entreprise de reprendre rapidement ses activités, limitant ainsi les pertes financières potentielles.
- Attentes des clients Qu’il s’agisse des employés ou des clients, les utilisateurs finaux exigent un accès continu aux services. Un rétablissement rapide permet non seulement de préserver la satisfaction client, mais aussi de préserver la réputation de l’organisation.
- Continuité opérationnelle Certains problèmes peuvent ne pas avoir de cause première immédiate et évidente. S'engager dans un processus long pour identifier et résoudre le problème sous-jacent peut ne pas être compatible avec les impératifs de continuité opérationnelle. La restauration du service permet à l'organisation de fonctionner pendant qu'une enquête plus approfondie est menée.
Solutions temporaires en attendant la réparation
Identifier la cause première d'un incident informatique est une étape cruciale pour prévenir sa récurrence. Cependant, la résolution du problème sous-jacent peut s'avérer longue, notamment si elle implique un cycle complet de développement et de tests. Dans de nombreux cas, les organisations exploitent des systèmes complexes et interdépendants, ce qui rend difficile la prévision précise de l'impact des modifications.
Imaginez un scénario où un bug critique est identifié et où l'équipe opérationnelle remonte jusqu'à un déploiement de code récent. En cherchant la cause racine, elle découvre que la résolution du problème sous-jacent implique des modifications dans plusieurs modules et nécessite des tests approfondis. Ou peut-être qu'il est tout simplement 2 heures du matin, et que ce n'est pas vraiment le meilleur moment pour se mettre à coder !
La solution appropriée, notamment en cas d'interruption de service, consiste à annuler rapidement la modification ayant introduit le bogue. Cette annulation permet à l'organisation de revenir rapidement à un état stable connu et contribue à minimiser les temps d'arrêt et à rétablir les services au plus vite. Cette approche permet également aux développeurs de travailler efficacement et de réduire la pression liée à l'urgence.
Une autre stratégie de rétablissement de service consiste à mettre en œuvre des mesures temporaires, comme l'augmentation des ressources allouées au maintien des services critiques. Cette approche reconnaît que la résolution du problème sous-jacent peut prendre du temps et que l'organisation ne peut se permettre une interruption de service prolongée.
Par exemple, si une augmentation soudaine et inattendue de l'activité des utilisateurs surcharge l'infrastructure existante, l'augmentation temporaire des ressources ou l'ajout de puissance de calcul peuvent atténuer la pression immédiate. Bien que cela ne résolve pas la cause profonde de l'augmentation de la demande, cela garantit la continuité des services, ce qui permet de gagner du temps pour une analyse plus approfondie et la mise en œuvre d'une solution à long terme.
Une approche mixte
Dans les deux cas, l'automatisation est essentielle.
Dans l'article précédent, nous avons expliqué comment les organisations peuvent accélérer la phase de triage du cycle de vie d'un incident et identifier sa cause première. Une approche similaire peut être adoptée pour la restauration des services. Disposer d'outils opérationnels accessibles en un clic pour effectuer des procédures de récupération standard, comme la restauration d'un déploiement ou l'augmentation des ressources, permet de réduire la pression et de gagner un temps précieux.
Les arguments en faveur de la priorité donnée à la restauration du service plutôt qu'à la résolution de la cause profonde brouillent parfois la frontière entre gestion des incidents et gestion des problèmes. La gestion des incidents vise à rétablir rapidement les services, tandis que la gestion des problèmes a pour objectif d'identifier et d'éliminer les causes profondes des incidents récurrents. Trouver un juste équilibre entre ces deux approches est essentiel pour maintenir un environnement informatique robuste et résilient.
Dans certaines situations, une approche mixte peut être adoptée. Elle consiste à mettre en œuvre des mesures temporaires pour rétablir rapidement le service, tout en menant simultanément une enquête sur la cause profonde du problème. L'essentiel est de trouver un juste équilibre pragmatique qui minimise les interruptions de service sans recourir à des correctifs incessants ni négliger la stabilité à long terme de l'infrastructure informatique.
L'automatisation des procédures de récupération standard, pouvant être déclenchées en quelques secondes par les équipes opérationnelles, est indispensable aux organisations opérationnellement matures pour leur donner la marge de manœuvre nécessaire pour résoudre les problèmes sous-jacents, sans interruption de service inutile.
MTTR – Réparé ou résolu ?
Dans le domaine de la gestion des incidents, le terme « Résolu » revêt une importance capitale. Les organisations matures reconnaissent l’importance d’une définition claire de ce terme afin d’utiliser avec assurance des indicateurs tels que le temps moyen de résolution (MTTR) et de respecter les accords de niveau de service (SLA).
Cependant, la résolution d'un incident peut parfois être ambiguë. Si la perturbation immédiate est résolue, le problème sous-jacent peut persister ou une vérification par l'utilisateur peut être nécessaire. Cela soulève la question de savoir si l'incident peut être considéré comme véritablement résolu.
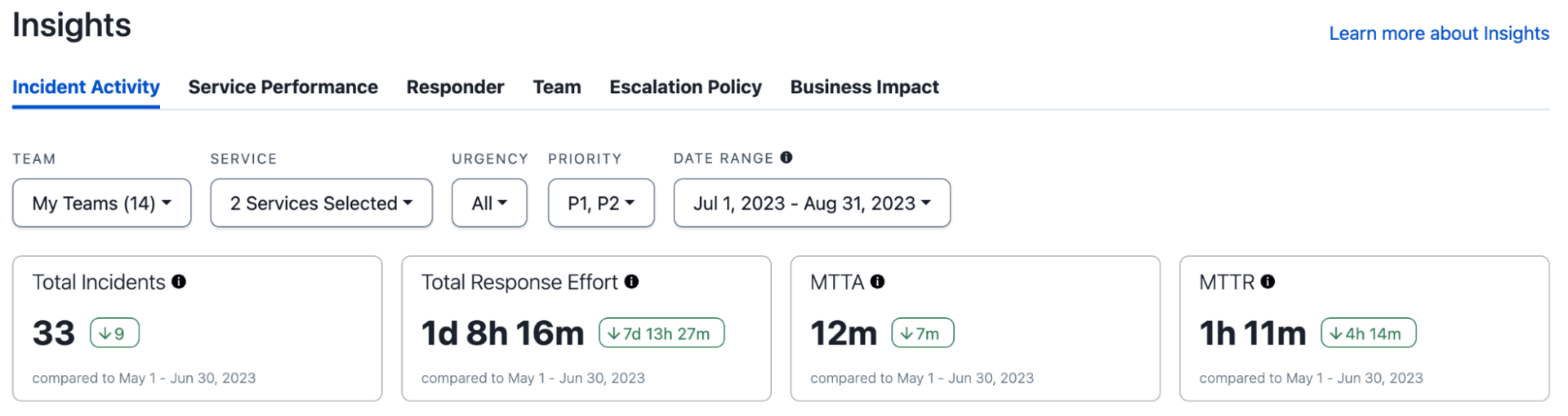
Des indicateurs comme le MTTR et les SLA sont essentiels pour évaluer la performance d'une organisation en matière de réponse aux incidents, tant en interne qu'en externe. Cependant, sans définition claire de la résolution, ces indicateurs peuvent donner une fausse impression de sécurité ou une image déformée de la réalité. Les organisations comprennent la nécessité de définir avec précision le moment où un incident est réellement résolu, ainsi que de disposer de rapports permettant de suivre et de mesurer précisément cette résolution à différents niveaux de granularité et de priorité.
Cette granularité est essentielle lorsqu'on utilise une mesure comme la « moyenne ». La durée d'un incident n'étant pas limitée, les résultats peuvent être faussés pour des échantillons dont la taille ne suit pas une distribution normale. Pour une excellente analyse approfondie de MTTR, ce blog récemment publié décrit parfaitement les avantages et les défis.
En définitive, l'approche pragmatique consiste à comprendre le contexte de chaque panne et à choisir la solution la plus efficace. L'objectif principal des équipes opérationnelles doit toujours être de minimiser les interruptions de service et d'assurer la continuité des activités. Bien que le traitement de la cause profonde soit essentiel pour prévenir les incidents futurs, les organisations doivent évaluer l'urgence du rétablissement du service au regard des retards potentiels liés à un dépannage et à une résolution approfondis.
Rétablir rapidement les services, même par des mesures temporaires ou des restaurations, peut constituer une décision stratégique répondant aux besoins immédiats de l'entreprise. Cette approche tient compte des défis concrets posés par les environnements complexes et du caractère imprévisible des incidents. Trouver le juste équilibre entre la gestion des incidents et la gestion des problèmes, associé à la capacité de le mesurer avec précision, permet aux organisations de gérer l'équilibre délicat entre un rétablissement rapide et une stabilité à long terme.
Un aperçu de l'avenir
Dans ce cinquième et dernier article, nous conclurons notre exploration du cycle de vie des incidents afin de comprendre comment utiliser les principes d'amélioration continue et d'apprentissage pour améliorer de manière itérative la gestion des incidents à chaque incident.
Vous souhaitez en savoir plus ?
Nous organiserons également une série de webinaires en trois parties consacrée au compte de résultat et à son utilité pour aider nos clients à se concentrer sur la croissance et l'innovation. Cliquez sur les liens ci-dessous pour en savoir plus et vous inscrire :
- 7 février 2024 : Partie 1 : Meilleure gestion des incidents : éviter les interruptions de service critiques en 2024
- 21 février 2024 : Partie 2 : De la crise au contrôle : comment moderniser la gestion des incidents grâce à l’automatisation et à l’IA
- Du 26 au 29 février 2024 : Partie 3 : PagerDuty 101

