
- PagerDuty /
- Blog /
- Gestion et réponse aux incidents /
- Minimiser la dérive des modèles de science des données en exploitant PagerDuty
Blog
Minimiser la dérive des modèles de science des données en exploitant PagerDuty
par PagerDuty
15 août 2022 | 7 minutes de lecture
Par Thomas Pin – Data Scientist
PagerDuty dispose d'un système d'alerte précoce (EWS) qui aide les services Customer Success et Sales à évaluer la santé des clients PagerDuty existants en fonction de l'utilisation des produits et de facteurs externes. Ce système d'alerte précoce est devenu une infrastructure essentielle et la première ligne de défense pour identifier les mauvaises utilisations des produits susceptibles d'entraîner une perte de clientèle. Le succès de ce système et les efforts considérables du service Customer Success ont permis de réduire l'utilisation à risque de nos produits. Avec un modèle aussi crucial en production, il est primordial qu'il génère des scores précis et soit actualisé en permanence.
En janvier 2021, le modèle du système d'alerte précoce a publié un score de risque client inexact en raison d'une modification en amont, ce qui a entraîné la publication d'un score erroné pendant quelques jours. Ce n'est que lorsqu'un responsable de la réussite client nous a contactés au sujet de cette erreur que nous avons pu immédiatement diagnostiquer et corriger le modèle. L'équipe Plateforme de données et Business Intelligence, connue en interne sous le nom de DataDuty, a décidé de trouver une solution pour éviter de tels problèmes à l'avenir.
Le problème mentionné ci-dessus n'est pas propre à PagerDuty. Dans la communauté des data scientists, ce serait un exemple de Dérive du modèle et cela se présente sous des formes plus diverses que de simples modifications de données en amont. L'équipe DataDuty était déterminée à minimiser l'impact de ce phénomène en utilisant des tests automatisés et Alertes PagerDuty lorsque ces problèmes surviennent.
PagerDuty
Le produit PagerDuty est la pièce maîtresse pour être proactif et éviter les dérives de modèle. Les modèles d'apprentissage automatique exploitant plusieurs plateformes, il devient impossible d'ingérer les journaux de ces plateformes, de créer des incidents, de les escalader en fonction de leur priorité et d'alerter les praticiens sans un logiciel dédié de tri des incidents, tel que PagerDuty. Quelle que soit la robustesse de nos tests automatisés, ils ne serviront à rien si nous ne parvenons pas à transmettre les résultats à la bonne personne au bon moment. PagerDuty a permis la réussite de notre stratégie et nous a permis de détecter tout changement préjudiciable avant même qu'un praticien ne le remarque.
Dérive du modèle
La dérive du modèle peut être divisée en trois catégories : concept, données et en amont, chacune nécessitant une approche différente pour la résolution.
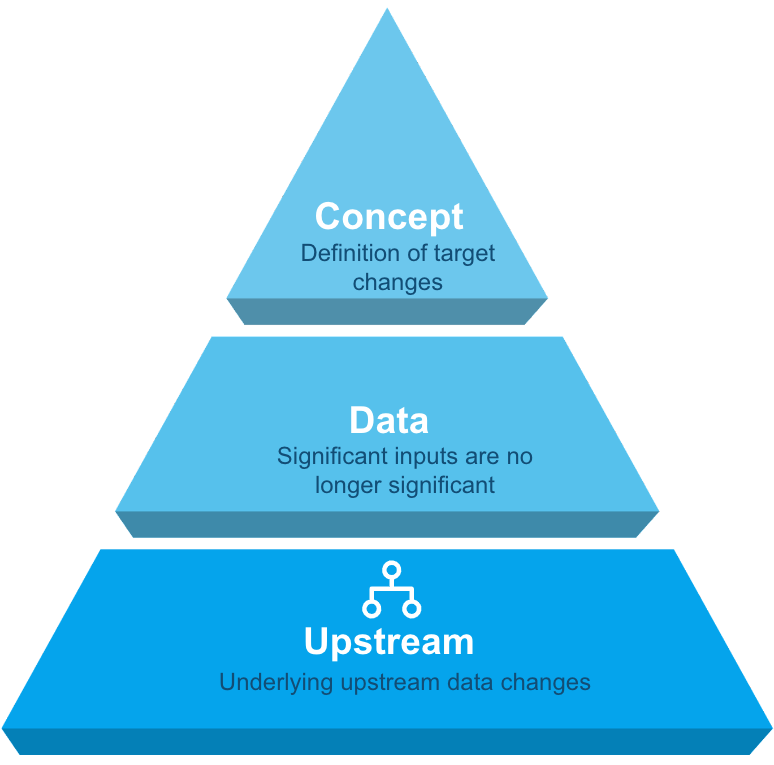 Concept : Définition de la cible des changements du modèle
Concept : Définition de la cible des changements du modèle
Données :Les entrées significatives ne le sont plus
En amont :Modifications sous-jacentes des données en amont
Tests de dérive conceptuelle
Il est difficile de concevoir un test pour détecter les changements de concept, car il s'agit d'une construction développée par les data scientists et les parties prenantes. Cependant, dans le cas du modèle de système d'alerte précoce, la cible est le « churn », dont la définition est simple. Chez PagerDuty, le « churn » désigne l'activation ou la désactivation d'un compte, et cette définition est restée stable.
Pour vérifier que le modèle du système d'alerte précoce prédit correctement le score de risque client, nous effectuons quelques tests unitaires :
- Avant le système d'alerte précoce, le taux de désabonnement mensuel de PagerDuty se situait entre x % et y %. Par conséquent, un taux de désabonnement mensuel supérieur à z % serait considéré comme problématique.
- Les scores globaux du système d'alerte précoce se sont stabilisés ces dernières années, et les scores des comptes individuels peuvent augmenter ou diminuer au fil du temps. Cependant, PagerDuty prévoit une répartition de 25* % des comptes présentant un score de risque client faible, 25* % présentant un score de risque client moyen-faible, 25* % présentant un score de risque client moyen et 25* % présentant un score de risque client élevé. * Chiffres non réels.
- Historiquement, le score mensuel moyen du système d'alerte précoce se situe dans une tolérance de 2,5 % du score moyen du système d'alerte précoce.
Si l'un de ces tests échouait, il serait classé comme une priorité élevée et PagerDuty enverrait une alerte à l'un des scientifiques de données de garde de DataDuty pour vérifier si la définition du « churn » du modèle était exacte et si elle nécessitait une mise à jour.
Tests de dérive des données
Au fil du temps, les caractéristiques du modèle peuvent devenir plus ou moins pertinentes pour le score du système d'alerte précoce, et PagerDuty a développé des tests pour atténuer ces risques. Par exemple, l'année dernière, l'un des indicateurs clés était le pourcentage d'incidents « acquittés » ( taux de reconnaissance des incidents ). Cette fonctionnalité était pertinente pour prédire la probabilité de désabonnement d'un compte. Cependant, il a récemment été constaté que taux de reconnaissance des incidents de haute urgence était plus pertinent et a remplacé l'incident d'origine taux de reconnaissance . PagerDuty effectue les tests suivants pour déterminer la pertinence d'une fonctionnalité dans notre magasin de fonctionnalités :
- d de Cohen Estime l'ampleur de l'effet entre deux moyennes. Le moteur du modèle du système d'alerte précoce repose sur la présence de caractéristiques présentant un écart significatif entre les moyennes, la distribution des clients et celle des clients perdus.
- Kurtosis Mesure la « queue » entre deux distributions. Les queues de distribution des clients et des clients perdus doivent présenter un écart significatif.
- Test de Kolmogorov-Smirnov Il s'agit d'un test non paramétrique d'égalité de distributions de probabilité continues et unidimensionnelles, permettant de comparer un échantillon à une distribution de probabilité de référence ou deux échantillons. Le modèle d'alerte précoce compare les deux distributions pour les clients et les clients perdus.
- Test T Il s'agit d'une statistique inférentielle utilisée pour déterminer s'il existe une différence significative entre les moyennes de deux groupes et leurs relations. En cas d'échec, calculez la significativité des caractéristiques.
Les fonctionnalités doivent rester dans les limites fixées, sinon PagerDuty créera un incident et l'attribuera à l'un des data scientists d'astreinte de DataDuty pour enquêter sur l'écart. De plus, ces indicateurs sont analysés chaque trimestre afin de déterminer si une nouvelle fonctionnalité doit être ajoutée au modèle du système d'alerte précoce.
Dérive des données en amont
En amont du modèle de système d'alerte précoce se trouvent les tables de données agrégées qui stockent les indicateurs pertinents pour une utilisation potentielle. Il existe actuellement neuf tables agrégées principales à surveiller, ainsi que plus de cinquante tables de base sur lesquelles ces tables s'appuient. Pour garantir l'intégrité et la disponibilité des données, la pile technologique de PagerDuty comprend : Snowflake pour l'entreposage des données, Monte Carlo pour la préservation de l'intégrité des données, Apache Airflow pour la planification des tâches, Databricks pour la construction et la réalisation d'expériences sur le modèle, et PagerDuty pour le tri des incidents en cas de problème. Par exemple, lorsqu'une « mauvaise charge » de données affecte le modèle du système d'alerte précoce, PagerDuty crée un incident et avertit l'ingénieur de données de garde de DataDuty.
Exemple de PagerDuty et de dérive de modèle
Voici un exemple réel d'une alerte PagerDuty qu'un membre de l'équipe DataDuty a reçue alors qu'il était de garde.
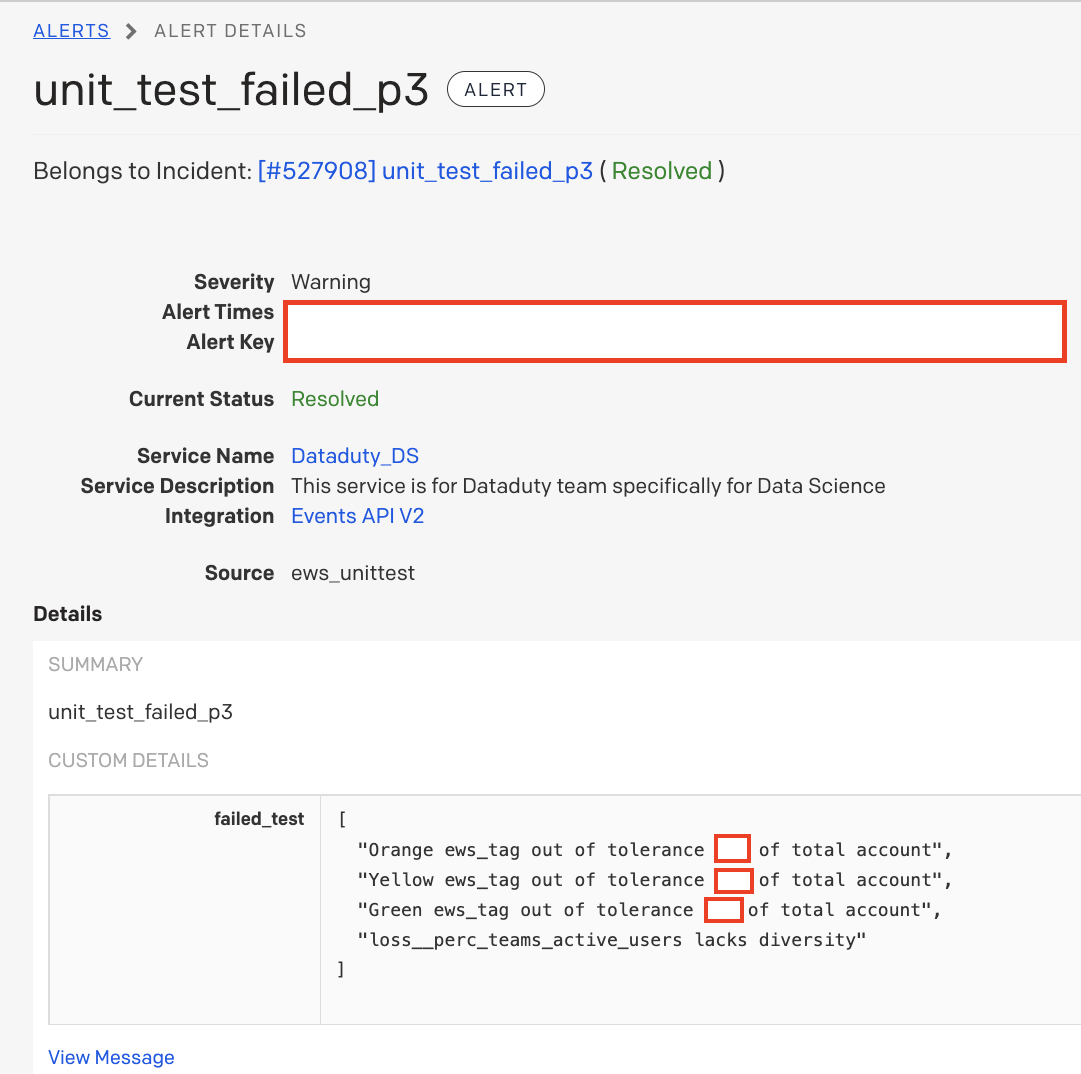
Le data scientist a été le premier à recevoir une alerte indiquant une possible anomalie dans les scores du modèle de système d'alerte précoce, car ces tests étaient conçus pour détecter les dérives conceptuelles. L'incident provenait de la source « ews_unittest », où se trouvent les tests de dérive du modèle. Ensuite, le data scientist a examiné le failed_text et a constaté que toutes les allocations de scores de risque client étaient inférieures aux tolérances attendues et que l'une des métriques affichait peu de variations. Fort de son expérience, le data scientist en déduit que la métrique du failed_text a probablement été remise à zéro, car la table d'agrégation n'a pas été mise à jour. Après quelques minutes d'investigation, il a confirmé qu'il s'agissait de la cause première de l'incident. Il a réaffecté l'incident à un ingénieur de données et a ajouté une note pour recharger la table d'agrégation d'où provenait la métrique problématique et relancer les calculs du modèle. En trente minutes, le modèle a affiché un signal de fin d'alerte et les scores corrects ont été mis en production avant même que les responsables de la réussite client ne soient informés du problème. Grâce à la puissance de ces tests automatisés et de PagerDuty, l'équipe DataDuty a réussi à diagnostiquer et à résoudre l'incident avant d'affecter les opérations de l'organisation avec une interruption minimale du travail quotidien de l'ingénieur de données et du scientifique des données de DataDuty.
Lorsque les modèles de science des données deviennent une infrastructure critique pour une organisation où la précision et la disponibilité sont primordiales, les équipes de science des données doivent envisager d'ajouter des tests pour surveiller les dérives des modèles et alerter les parties prenantes concernées dès les premiers signes de problème. Instaurer la confiance entre les praticiens des modèles de données est essentiel au succès des modèles de machine learning d'entreprise. Comme l'a dit Kevin Plank : « La confiance se construit par petites touches et se perd par petites touches », alors ne laissez pas la dérive des modèles affecter la confiance de vos modèles.
Vous aimerez peut-être aussi ceux-ci...

