
- PagerDuty /
- Blog /
- Bewährte Verfahren und Erkenntnisse /
- Über die MTTR hinaus mit PagerDuty Analytics verbessern
Blog
Über die MTTR hinaus mit PagerDuty Analytics verbessern
von Mandi Walls
2. Januar 2024 | 8 Minuten Lesezeit
Verbesserung über MTTR hinaus
Wir haben bereits etwas über die Unklarheiten bezüglich MTTR geschrieben. vor Wir möchten jedoch die Verwirrung und das möglicherweise falsche Sicherheitsgefühl, das unsere Abhängigkeit von MTTR verursacht, sowohl qualitativ als auch quantitativ genauer untersuchen.
Unsere Freunde bei der LEERE Wir haben uns auch mit MTTR unter dem Gesichtspunkt auseinandergesetzt, dass wir oft nicht einmal den genauen Zeitpunkt bestimmen können; wir erfassen die Zeit ab dem Zeitpunkt des Eingangs einer Benachrichtigung oder vielleicht ab dem Zeitpunkt, an dem ein Kunde ein Problem meldet, aber diese Methoden sind nur so gut wie unsere Kennzahlen und die Kanäle für die Kundenberichterstattung.
Wenn unser Ziel darin besteht, unsere Zuverlässigkeit zu erhöhen und unsere mittlere Reparaturzeit (MTTR) zu senken, stellen wir möglicherweise fest, dass die MTTR uns nicht alle Informationen liefert, die wir zur Verbesserung benötigen. Wenn Sie sich für Monte-Carlo-Simulationen interessieren (und wer tut das nicht!), dieses Papier Google untersucht mithilfe von Mathematik einige Schwächen von MTTR. Und zwar sehr viel Mathematik.
Gemeinheit gegenüber Gemeinheiten
Wahrscheinlich haben Sie in der Schule etwas über deskriptive Statistiken wie Mittelwert, Modalwert und Median einer Wertereihe gelernt. Der Modalwert ist dabei etwas ungewöhnlich, da er der Wert ist, der am häufigsten vorkommt. Der Median ist der mittlere Wert einer Wertereihe, wenn diese der Größe nach geordnet ist, und der Mittelwert ist der Durchschnitt aller Werte.
Wir verwenden den Mittelwert recht häufig bei der Reaktion auf Vorfälle. Ihr Team kann Ihre Daten verfolgen. mittlere Zeit bis zur Bestätigung zusätzlich zu Ihren mittlere Zeit zur Wiederherstellung/Reparatur/Problemlösung Wenn wir an den Mittelwert einer Zahlenmenge denken, erinnern wir uns an Beispiele aus dem Algebraunterricht wie „die durchschnittliche Punktzahl in einer Geschichtsprüfung“ oder „die durchschnittliche Temperatur in unserer Stadt für diesen Monat“. Diese Zahlen liegen bereits in einem klar definierten Bereich mit vernünftigen oberen und unteren Grenzen. Sie sind besonders nützlich für Mengen mit einem Normal Verteilung.
Das Verrückte an Ihrer Lösungszeit ist, dass es praktisch keine Obergrenze gibt; je nachdem, welche Grenzen Ihr Team für die mittlere Reparaturzeit (MTTR) festlegt, können Vorfälle im Grunde ewig dauern, was die MTTR… seltsam erscheinen lässt.
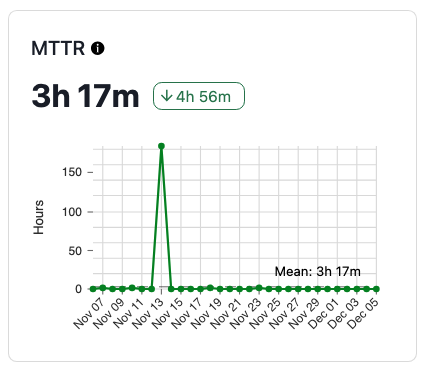
Zusammenfassende Statistiken sind hilfreich, um die Merkmale einer Wertemenge zu abstrahieren. Sobald diese Werte jedoch ihre Grenzen überschreiten, muss man über die Nützlichkeit von Aspekten wie dem Mittelwert entscheiden oder gegebenenfalls festlegen, wie mit Anomalien umzugehen ist. Bei Softwarevorfällen können Anomalien durchaus berechtigt sein; Teams warten möglicherweise auf die Genehmigung und Bereitstellung von Arbeiten oder auf die Veröffentlichung eines Fixes durch einen Zulieferer.
Im Bereich der Zuverlässigkeitsdaten hat sich die Branche weiterentwickelt und setzt nun auf robustere und nützlichere Messgrößen, die möglicherweise in einem bestimmten Bereich liegen. verzerrt oder multimodal Verteilung. Vielleicht betrachten Sie einige Ihrer Daten basierend auf Perzentile statt Mittelwerten. Das sagt mehr über die Form der Werte selbst aus und darüber, wie wahrscheinlich ein „schlechter“ Wert für den gewählten Datenpunkt ist.
Qualität steht an erster Stelle, nicht Quantität.
Die Verbesserung der MTTR-Kennzahl kann für viele Teams in komplexen Umgebungen eine Herausforderung darstellen, da sie keine eindimensionale Größe ist. Sie ist oft ein grobes Instrument, aber für Teams ohne Erfahrung im Incident-Management ein guter Ausgangspunkt. Sobald die Mechanismen der Incident-Response-Workflows verinnerlicht sind, werden einige Schwächen der MTTR deutlich.
Ich denke an die Testergebnisse der Geschichtsprüfung, die ich vorhin erwähnt habe. Alle Studierenden des Kurses haben dieselbe Prüfung geschrieben; sie hatten wahrscheinlich vor der Prüfung Zugriff auf dieselben Vorlesungen und Materialien. Wenn Studierende ihre Punktzahl in der nächsten Prüfung verbessern wollen, werden sie mehr lernen. Was sollte Ihr Team tun, um die mittlere Reparaturzeit (MTTR) zu verkürzen? Können Sie mehr lernen?
Wir hoffen außerdem, dass Sie bei Ihren Einsätzen nicht immer wieder dasselbe Problem lösen müssen. Wir möchten, dass die Leute Aus Vorfällen lernen und diese Erkenntnisse nutzen, um die Zuverlässigkeit ihrer Dienste zu verbessern. Hinzu kommen zahlreiche weitere Faktoren, die die Umgebung Ihrer Dienste beeinflussen: Nutzungsmuster der Kunden, neuer Code und neue Funktionen sowie sonstige Änderungen. Es ist sehr schwierig zu sagen: „Vorfall 150 in diesem Monat ist genau wie Vorfall 120 im letzten Monat und hat weniger Zeit in Anspruch genommen“, da die Umgebungsbedingungen nie identisch sind.
Die Ursachenforschung in einem komplexen System zur Behebung eines Vorfalls kann ein komplizierter Prozess sein, der mehrere Systeme und Teams involviert. Der Vergleich der Wiederherstellungszeiten aller Vorfälle eines Dienstes innerhalb eines bestimmten Zeitraums liefert nur wenige Informationen über dessen Verhalten. Komplexe Vorfälle sind vielschichtig, und unser Wissen darüber ist entscheidend für Verbesserungen und die daraus gewonnenen Erkenntnisse.
Ein Großteil der qualitativen Diskussion rund um einen Vorfall sollte im Rahmen der Nachbesprechung des Vorfalls erfolgen. Wenn Sie jedoch Trenddaten suchen, um Verbesserungen aufzuzeigen, gibt es einige Möglichkeiten, Ihre Vorfälle zu analysieren, um einen besseren Überblick über das Gesamtbild zu erhalten und Ihren Teams Hinweise darauf zu geben, was verbessert werden muss.
Sollte man die MTTR überhaupt messen?
Wir beobachten, dass viele Teams, die PagerDuty ohne bestehenden Incident-Management-Plan einsetzen, ihre mittlere Reparaturzeit (MTTR) innerhalb kurzer Zeit drastisch verbessern. Ein wesentlicher Faktor für die erfolgreiche Incident-Behebung ist die Mobilisierung der Teams, der Einsatz von Automatisierung und die Kommunikation. Für diejenigen, die darin noch nicht so geübt sind, bedeutet die Einrichtung geeigneter Tools den Beginn einer neuen Ära. Die Dokumentation der MTTR-Verbesserungen ist ein hervorragender Start für diese Teams.
Sobald Ihr Team einen Workflow für die Reaktion auf Sicherheitsvorfälle effektiv nutzt, wird die alleinige Fokussierung auf die mittlere Reparaturzeit (MTTR) die Zuverlässigkeit Ihrer Dienste wahrscheinlich nicht weiter verbessern. Ihre MTTR kann durchaus gleich bleiben, steigen oder sogar sinken, wenn Sie verdoppelt Die Anzahl der Vorfälle in Ihrem Dienst ist zwar relevant, aber der Datensatz weist dieselbe Spannweite auf (die Google-Veröffentlichung zeigt ein Beispiel für solche Szenarien). Ihre Nutzer würden jedoch definitiv eine geringere Zuverlässigkeit wahrnehmen, wenn mehr Vorfälle auftreten. Die mittlere Reparaturzeit (MTTR) kann diese Veränderung der Gesamtzuverlässigkeit nicht aufzeigen. Die Verwendung eines Mittelwerts verfälscht die Details zu stark.
Es gibt weitere Informationen, die Sie sich ansehen können, von denen viele im Analytics-Angebot von PagerDuty enthalten sind. Einblicke Berichte. Diese helfen Ihnen, die anderen Dimensionen Ihrer Vorfälle genauer zu untersuchen, erfordern aber, dass Sie sorgfältig auf die Datenhygiene achten.
Ein guter Datenpunkt, auf den sich die Teams konzentrieren sollten, ist die Sicherstellung, dass Vorfälle priorisiert werden.
Prioritäten
In Ihrem PagerDuty -Konto haben Sie die Möglichkeit, eine Reihe von Einstellungen zu definieren. Prioritäten die mit Ihren Zuverlässigkeitszielen übereinstimmen. Ihr Team kann festlegen, was die Prioritätsstufen bedeuten, z. B. den Prozentsatz der betroffenen Kunden, die Dauer eines Vorfalls oder andere für Sie sinnvolle Kriterien.
Einem Vorfall wird nicht automatisch eine Priorität zugewiesen; einige Teams nutzen Alarmdaten, um die Priorität zu bestimmen. Event-Orchestrierung Andere Teams aktualisieren die Priorität während des Vorfalls manuell. Wieder andere Teams warten möglicherweise, bis der Vorfall behoben ist, und aktualisieren die Priorität nachträglich, um den Vorfall genauer abzubilden.
Durch die Zuweisung von Prioritäten zu jedem Vorfall, auf den Ihr Team reagiert, können Sie erkennen, wie sich Ihr Team bei den wichtigsten Vorfällen schlägt. Sie können die Priorität als Filter auf dem Insights-Bildschirm verwenden, und die zusammenfassenden Daten zeigen Ihnen zusammenfassende Daten und Trends für die wichtigsten Prioritäten an.
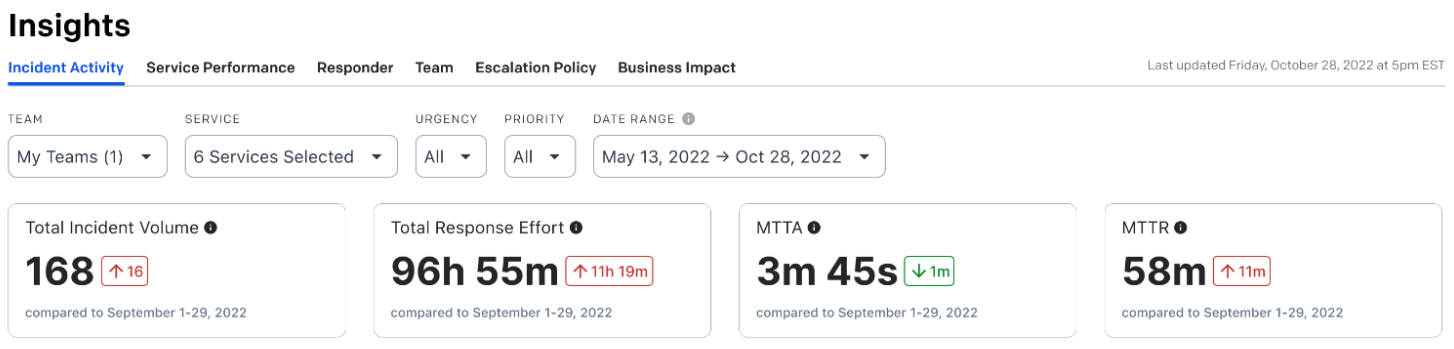
Dies hilft Ihnen, die Heterogenität Ihrer Vorfälle zu analysieren und sich auf diejenigen zu konzentrieren, die für Ihre Benutzer am wichtigsten sind. Wenn Ihr Team viele Vorfälle mit niedriger Priorität und kurzer Dauer hat, gibt Ihnen die mittlere Reparaturzeit (MTTR) keine Auskunft über die geringere Anzahl von Vorfällen mit hoher Priorität.
Die Beobachtung der Anzahl von Vorfällen mit hoher Priorität bei nutzerorientierten Diensten, kombiniert mit einer Reihe von nutzerorientierten SLOs Dies kann Ihrem Team helfen, Benchmarks festzulegen und bessere Entscheidungen zu treffen. Wenn ein Dienst in den letzten 30 Tagen zu viele schwerwiegende Vorfälle (SEV-1) mit Auswirkungen auf Kunden hatte und die Service-Level-Vereinbarung (SLO) kurz vor der Unterschreitung steht, können Entwicklungsteams fundiert entscheiden, ob sie Releases einfrieren oder zuverlässige Funktionen priorisieren, um die Dienstzuverlässigkeit wiederherzustellen.
Zusammenfassung
Die Überwachung Ihrer mittleren Reparaturzeit (MTTR) kann hilfreich sein, um die Verbesserungen Ihres Teams bei der Einführung eines neuen Workflows zur Reaktion auf Sicherheitsvorfälle zu messen. Erfahrene Teams profitieren möglicherweise stärker von einer detaillierteren Analyse ihrer Vorfalldaten. PagerDuty Analytics kann Sie dabei unterstützen. Weitere Informationen und die neuesten Funktionen in Analytics finden Sie auf unserer Website. YouTube-Kanal Dort haben wir einige der neuesten Funktionen veröffentlicht! Mehr dazu finden Sie hier: Einblicke und das neue Analyse-Dashboard mit unserem Produktteam!

