- PagerDuty /
- Blog /
- Vorfallmanagement und Reaktion /
- Titel für intelligente Alarmgruppierung erstellen
Blog
Titel für intelligente Alarmgruppierung erstellen
von Quintessenz Anx
27. Januar 2022 | 7 Minuten Lesezeit
Mitverfasst von Chris Bonnell, PagerDuty Data Scientist VI
Wir setzen unsere Reihe zum Thema „Intelligente Alarmgruppierung (IAG) nutzen und verbessern“ fort! Falls Sie es verpasst haben: In unserem ersten Beitrag haben wir Ihnen die Funktion „Intelligente Alarmgruppierung“ vorgestellt. ( Hier Im zweiten Beitrag haben wir erklärt, wie IAG mithilfe von Zusammenführung Warnungen gruppiert. (Hier) Wir haben am Ende des letzten Beitrags bereits auf das heutige Thema angespielt: Heute werden wir darüber sprechen, wie man Benachrichtigungstitel nutzen kann, um IAG-Übereinstimmungen zu verbessern.
Wo Sie den Titel der Benachrichtigung sehen – eine kurze Zusammenfassung
Wenn in unserer Plattform ein Alarm ausgelöst wird, kann die Benachrichtigung über verschiedene Wege versendet werden: per E-Mail, SMS oder Push-Benachrichtigung direkt aus der App. Unabhängig vom gewählten Weg werden mindestens folgende Informationen angezeigt: Alarmnummer, Dienst und Alarmtitel. Diese Informationen werden an mehreren gut sichtbaren Stellen angezeigt. Je nachdem, wie Sie Erhalten Sie Ihre Benachrichtigungen Einige oder alle dieser Angaben könnten Ihnen bekannt vorkommen. Beachten Sie, dass die Dringlichkeitsstufe (z. B. hoch) zwar zur Bestimmung Ihrer Kontaktmöglichkeiten dient, aber nicht sichtbar angezeigt wird (sondern in den Vorfalldetails enthalten ist).
Telefon-Push-Benachrichtigungen und SMS-Benachrichtigungen
Betrachten wir beispielsweise den Sperrbildschirm eines iPhones (zusätzlich zur SMS-Benachrichtigung und dem Anruf im Zusammenhang mit demselben Vorfall):
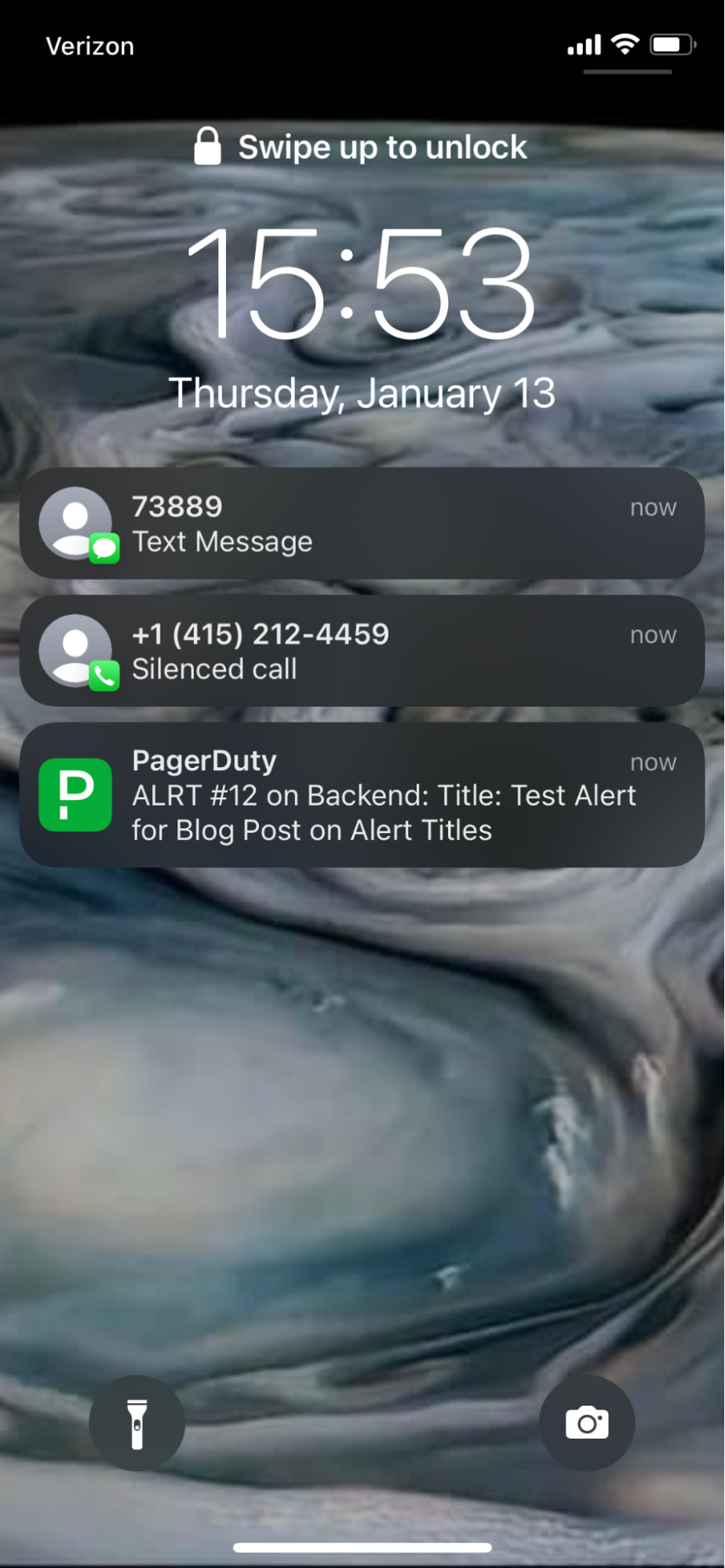
In diesem Fall lasse ich die Benachrichtigung für den Blogbeitrag an alle Kanäle senden. Hier sehen Sie, dass Titel, Nummer und Dienst der Benachrichtigung angezeigt werden. Eine SMS sieht ähnlich aus:

E-Mail-Benachrichtigungen
Diese sehen etwas anders aus. Der Betreff der E-Mail ist nicht sehr aussagekräftig, aber die vollständigen Benachrichtigungsdetails sind im Nachrichtentext enthalten:
Warum überprüfen wir, wo Warnmeldungstitel angezeigt werden?
Wenn es Ihnen wie mir geht, haben Sie beim Verfassen von Benachrichtigungstiteln und -beschreibungen für reale Situationen und Dienste wahrscheinlich die menschliche Wahrnehmung im Blick gehabt. Spuren davon sehen Sie auch oben. Der Benachrichtigungstitel liest sich eher wie ein Blogbeitragstitel und enthält den Begriff „Titel“ auffällig im Titel selbst, um dessen Platzierung zu betonen. Das ist für Menschen gedacht – wenn Sie diese Bilder überfliegen, möchte ich Ihre Aufmerksamkeit auf bestimmte Bereiche lenken.
Was wäre, wenn ich für Nicht-Menschen designen würde? Was wäre zum Beispiel, wenn ich im Bereich des maschinellen Lernens designen würde? Wahrscheinlich würde ich alles, was ich über maschinelles Lernen weiß oder gelernt habe, nutzen und die Botschaft so anpassen, dass sie diesem System zugutekommt.
Was ich Ihnen aus all dem mitgeben möchte, ist Folgendes: Vergessen Sie nicht, dass Sie den Menschen immer noch im Blick behalten müssen, wenn Sie Ihr Wissen über maschinelles Lernen einsetzen, um Ihre Erfahrung mit Intelligent Alert Grouping zu verbessern.
Nutzen Sie Ihren Alarmtitel zu Ihrem Vorteil
Wenn Sie den Benachrichtigungstitel für Personen erstellen, denken Sie daran:
- Fassen Sie sich kurz. Wie Sie sehen, gibt es sowohl für Push- als auch für Textbenachrichtigungen eine kurze Zeichenbegrenzung.
- Die Beschränkungen variieren je nach Betriebssystem und Webbrowser. Android beispielsweise erlaubt maximal 65 Zeichen für den Titel einer Benachrichtigung und zusätzlich 240 Zeichen für die Beschreibung, während iOS insgesamt maximal 178 Zeichen für Titel und Beschreibung vorsieht.
- Seien Sie klar und deutlich. Formulieren Sie nicht so knapp, dass der Titel verwirrend ist oder nichts aussagt.
- Bevorzugen Sie nicht das Titelfeld und vernachlässigen Sie nicht die anderen Felder.
- Die PagerDuty Mobil-Apps sowie die Weboberfläche bieten vollständige Vorfallsinformationen, einschließlich anderer Vorfälle, deren Dienste und Beschreibungen. Fügen Sie Informationen nicht einfach oben in das Titelfeld ein, nur weil es an erster Stelle steht.
Weitere Informationen hierzu finden Sie in unserer Schulleiter benachrichtigen Seite in unserem Leitfaden für die Reaktion auf Zwischenfälle.
Beim maschinellen Lernen sollten Sie Folgendes beachten:
- Nutzen Sie Einzigartigkeit und Häufigkeit zu Ihrem Vorteil.
- Datenmodelle können nicht lesen (im selben Sinne wie Menschen).
- Datenmodelle können keine Absichten ableiten.
Der Grund dafür liegt im Verständnis der sogenannten „natürlichen Sprachverarbeitung“ (NLP). NLP ermöglicht es Rechtschreib- und Grammatikprüfungen, zwischen „it’s“ und „its“ zu unterscheiden und den Autor entsprechend zu benachrichtigen. Auch die Autokorrektur weiß so, welches Wort, welche Konjugation und welche Form (Konjugation, Deklination) vorgeschlagen werden soll. Bei der NLP-Verarbeitung von Warnmeldungstiteln werden diese anonymisiert (dazu später mehr), in Sätze und anschließend in Wörter zerlegt (Satz-Tokenisierung bzw. Wort-Tokenisierung). Die Wörter werden dann lemmatisiert, und das Ergebnis dient der Bestimmung der Häufigkeit und der Suche nach Korrelationen mit anderen Warnmeldungen.
Zunächst zur Anonymisierung: Ziel ist es, ansonsten zu eindeutige Informationen durch deren Muster zu ersetzen, beispielsweise eine spezifische IP-Adresse durch xx.xx.xx.xx. Dieser Text wird nicht vollständig entfernt, um potenziell relevanten Kontext nicht völlig zu verlieren, sondern um zu verhindern, dass die eindeutigen Informationen dazu führen, dass Titel nicht mehr zusammenpassen. Die Lemmatisierung vereinfacht konjugierte oder deklinierte Wörter zu einer Grundform, dem Lemma. Ein weiteres Beispiel: {„dogs“, „dog's“, „dogs'“, „dog“} werden alle zu „dog“ lemmatisiert, ebenso wie {„is“, „are“, „be“, „were“} zu „be“. Das bedeutet, dass Sätze wie „The dog's bones.“ und „The dogs' bones.“ in dieser Phase beide zu {„the“, „dog“, „bone“, „.“} lemmatisiert werden.
An dieser Stelle nutzt das Modell der intelligenten Alarmgruppierung sowohl N-Gramme (Gruppen von N Wörtern) als auch unser Wissen über sprachliche Muster in Vorfallsmeldungen, um Informationen aus dem Alarmtitel zu extrahieren und sinnvolle Korrelationen herzustellen. Schauen wir uns die Beispiele, die ich in meinem Beitrag angeführt habe, noch einmal genauer an. vorheriger Beitrag :
- Erstes Muster:
- Hohe Speicherauslastung (> N %) auf Server $NAME in Region $REGION
- Zweites Muster:
- Die Speicherauslastung des Hosts ist hoch (> N %).
Ich habe bereits mit N % und $NAME einiges anonymisiert, aber lasst uns nun die Übung der Tokenisierung dessen, was in diesen Titeln steht, durchgehen:
- Tokenisiertes und lemmatisiertes erstes Muster:
- {“memory”, “use”, “high”, “(“, “>”, “N”, “%”, “)”, “on”, “server”, “$NAME”, “in”, “region”, “$REGION”}
- Tokenisiertes und lemmatisiertes zweites Muster:
- {“memory”, “use”, “on”, “host”, “be”, “high”, “(“, “>”, “N”, “%”, “)”}
Betrachtet man die Bedeutung der Muster, so ist im zweiten Warnhinweis der einzige variable Wert N, abhängig vom eingegebenen Wert. Ist der Schwellenwert konstant und nicht die aktuelle Speichernutzung, ändert sich N möglicherweise gar nicht oder es erscheinen nur ein oder zwei Werte im Titel. Im Gegensatz dazu ist der Titel des ersten Warnhinweises durch den Servernamen und die Region eindeutiger. Hier variieren also drei Werte anstatt nur einem oder keinem. Für den Sprachprozessor sind Warnhinweise des zweiten Musters daher deutlich stärker korreliert als die des ersten.
Wie geht es von hier aus weiter?
Bei der Erstellung von Benachrichtigungstiteln ist es wichtig, sowohl menschliche Faktoren als auch maschinelles Lernen zu berücksichtigen. leicht Die Verzerrung bei der Optimierung von maschinellem Lernen liegt darin begründet, dass Nutzer die vollständigen Alarm- und Vorfalldetails nutzen können, um zusätzlichen Kontext und Informationen zu erhalten, während die intelligente Alarmgruppierung nur das Titelfeld verwendet. Weitere Informationen zu den Grundlagen der natürlichen Sprachverarbeitung finden Sie unter [Link einfügen]. Einführung in die Verarbeitung natürlicher Sprache für Texte Blogbeitrag im Towards Data Science-Blog. Für Best Practices, welche Informationen in Warnmeldungen und Vorfallsmeldungen allgemein relevant sind, werfen Sie bitte einen Blick auf unsere Leitfaden für die Reaktion auf Vorfälle Die
Diese könnten Ihnen auch gefallen...

