
- PagerDuty /
- Blog /
- Bewährte Verfahren und Erkenntnisse /
- Als das Internet kurzzeitig ausfiel: Was uns der Ausfall vom 12. Juni über Resilienz lehrt
Blog
Als das Internet kurzzeitig ausfiel: Was uns der Ausfall vom 12. Juni über Resilienz lehrt
von PagerDuty
18. Juni 2025 | 5 Minuten Lesezeit
Am 12. Juni 2025 brach das Internet zusammen. E-Mails verschwanden, Apps stürzten ab, und viele von uns verloren den Kontakt zu ihren digitalen Kollegen (sowohl KI als auch Menschen). Die Welt spürte die Auswirkungen sofort: Unternehmen gerieten ins Stocken, Teams wurden durcheinandergebracht, und digitale Abläufe wurden überall beeinträchtigt.
Es fühlte sich ein bisschen wie ein Déjà-vu an. Kann sich jemand daran erinnern? 19. Juli 2024 ?
Der Ausfall vom 12. Juni hat einmal mehr bewiesen, dass jeder von einer Störung betroffen sein kann. Was erfolgreiche Unternehmen auszeichnet, ist ihre schnelle Reaktionsfähigkeit, wobei KI und Automatisierung den Teams einen entscheidenden Vorsprung verschaffen. Dies ist nicht nur eine technische Herausforderung, sondern eine geschäftliche Notwendigkeit. In einer Welt, in der digitale Dienste das Rückgrat von allem bilden, kann die Störung eines einzelnen Anbieters Auswirkungen auf den gesamten Betrieb haben. Die wahren Kosten gehen weit über die unmittelbaren finanziellen Einbußen hinaus und untergraben Vertrauen und Reputation.
Und obwohl solche umfassenden, systemweiten Ausfälle selten sind, lassen sie sich nicht vermeiden. Wiederherstellung, Redundanz und Zuverlässigkeit sind in diesen schwierigen Zeiten unerlässlich. Sprechen wir darüber, warum.
Vorbereitung und Wissen sind der Schlüssel zu einer schnellen Genesung
Als die Systeme ausfielen, verschwanden nicht nur E-Mails. Teams verloren mit einem Schlag den Zugriff auf Kollaborationstools, KI-Workflows und wichtige Geschäftsanwendungen. Das Problem lässt sich nicht einfach durch die Abhängigkeit von einem bestimmten Anbieter oder Cloud-Dienst lösen. Auch die Gewährleistung von Redundanz über verschiedene Anbieter oder Regionen hinweg reicht nicht aus.
Hier ist der Grund: selbst wenn Du Wenn Sie wachsam bleiben, könnten Ihre Werkzeuge, auf die Sie angewiesen sind, es nicht sein. Und das hängt – Sie ahnen es schon – von deren Abhängigkeiten ab. Was also tun?
Schauen Sie zunächst in sich selbst. Beginnen Sie mit der Erfassung Ihrer Abhängigkeiten. Ermitteln Sie, welche Dienste von welchen Anbietern abhängen. Erkennen Sie, welche Dienste voneinander abhängig sind und wie Sie Ausfälle dieser einzelnen Technologiekomponenten miteinander in Zusammenhang bringen.
Sobald dieser Teil erledigt ist, Beginnen Sie mit der Kartierung der Abhängigkeiten. Analysieren Sie Ihren Tech-Stack. Testen Sie Ihre Ausfallmuster unter Druck oder analysieren Sie sie mithilfe von Chaos Engineering. Was funktioniert ohne GCP? Was passiert, wenn AWS ausfällt? Wissen ist die halbe Miete. Und es kann Ihnen Möglichkeiten aufzeigen, Ihr System zukünftig besser gegen Ausfälle abzusichern.
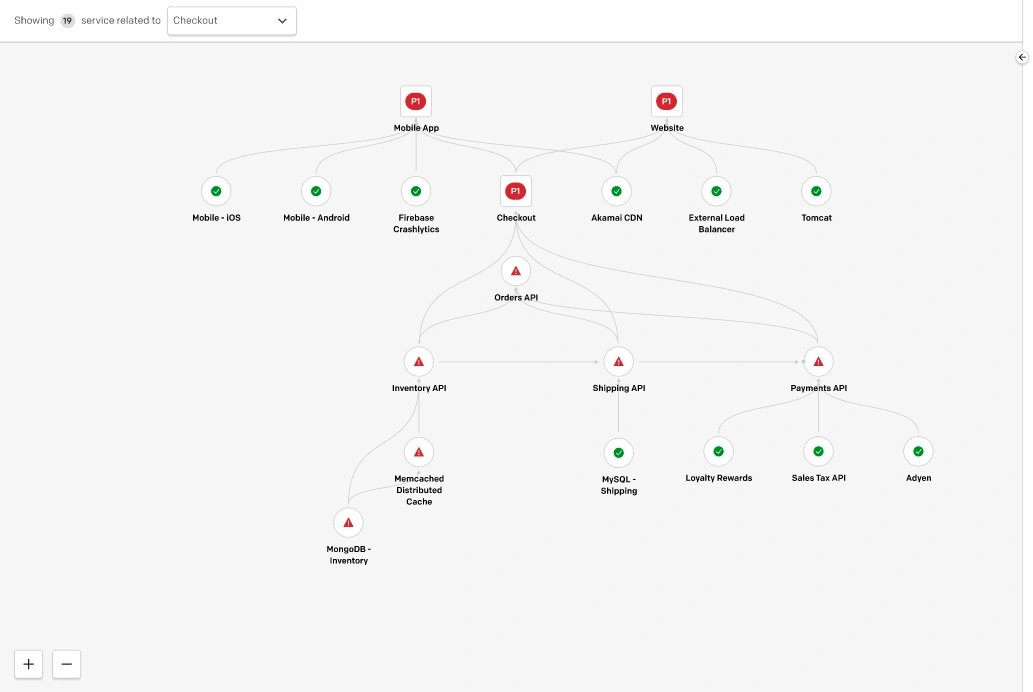
Doch die Kenntnis Ihrer Abhängigkeiten ist nur der Anfang. Wenn etwas schiefgeht, kann Ihre Kommunikation über Erfolg oder Misserfolg Ihrer Reaktion entscheiden, und deshalb sollten Sie Redundanz in Betracht ziehen.
Redundanz, Redundanz, Redundanz
Die erste Frage bei jeder Serviceunterbrechung lautet: „Betrifft es nur uns?“ Am 12. Juni breitete sich die Verwirrung schnell aus. Kunden, Mitarbeiter und Partner wollten sofort Antworten. Schweigen verschlimmerte die Lage nur.
Redundanz bei all Ihren Tools ist möglicherweise nicht kosteneffektiv. Wie viel Geld würden Sie allein im Falle eines solchen Fehlers durch doppelte Lösungen verschwenden? Redundanz bei den Kommunikationsmethoden ist hingegen unerlässlich.
Am 12. Juni konnten die Menschen keine E-Mails versenden. Sie konnten nicht mit ihren Kollegen chatten. Mobile Apps stürzten ab. Und viele fragten sich: Wie geht es weiter und wer hat Antworten?
Backup-Kommunikation ist unerlässlich. Hier einige Punkte, die Sie beachten sollten:
- Habe einen Plan: Ein wesentlicher Bestandteil jedes umfassenden Notfallplans ist das Verständnis der Teamkommunikation während eines Problems. Findet die Kommunikation persönlich statt? Nutzt ihr hauptsächlich Chat? Oder Videokonferenzen? Wo hinterlasst ihr Notizen und arbeitet zusammen? Eine frühzeitige Dokumentation dieser Punkte kann in kritischen Situationen Hektik vermeiden.
- Kommunikation über verschiedene Oberflächen hinweg: Angenommen, Sie nutzen hauptsächlich Chat. Doch dann fällt der Chat aus. Sie brauchen einen Plan B. Redundanz in den Kommunikationskanälen kann lebensrettend sein, insbesondere wenn alle benötigten Informationen über diese Kanäle verfügbar sind. Wenn Sie über die Benutzeroberfläche eines Tools, per Mobilgerät, Chat oder Video kommunizieren können, erweitert das Ihre Möglichkeiten und ermöglicht Ihnen Flexibilität, egal was passiert.
- Lassen Sie die KI einen Teil der Last übernehmen: Die Kommunikation während eines Zwischenfalls ist schon schwierig genug. Noch schwieriger wird es, wenn Ihre Kommunikationskanäle beeinträchtigt sind UND Sie wichtige Stakeholder auf dem Laufenden halten müssen. GenAI entlastet Sie, indem wir maßgeschneiderte Kommunikationsmittel wie Statusberichte und Stakeholder-Updates für Sie erstellen.
Wenn Ihre Pläne stehen, Abhängigkeiten erfasst und wichtige Redundanzen für den Fall eines Ausfalls bereit sind, sind Sie besser gerüstet, um auf ein Problem zu reagieren. Doch was wäre, wenn Sie über robuste Tools verfügen könnten, die selbst unter schwierigsten Bedingungen zuverlässig funktionieren? Die Wahl Ihrer Partner ist entscheidend, insbesondere wenn es brenzlig wird.
Die Zuverlässigkeit ist die eigentliche Frage.
Niemand kann jeden Stromausfall vorhersehen, aber Sie können Partner auswählen, die Ihnen bei der Wiederherstellung helfen und starke Beziehungen zu ihnen aufbauen PagerDuty ist der Partner von fast 70 % der Fortune 100-Unternehmen. Wir waren am 12. Juni, 19. Juli und an jedem anderen Tag seit unserer Gründung vor über zehn Jahren zuverlässig. Zuverlässigkeit ist Teil unserer DNA. Sie ist Kern unserer täglichen Arbeit. Wir sind immer für unsere Kunden da.
Wenn Sie sich eine solche Partnerschaft wünschen, sollten Sie nicht nur auf Funktionen oder eine ansprechende Benutzeroberfläche achten, sondern auf nachweisbare Ergebnisse. Der Ausfall vom 12. Juni hat gezeigt, dass niemand vor Störungen gefeit ist. Die Kenntnis Ihrer Abhängigkeiten, klare Kommunikation mit eingebauter Redundanz und die Wahl der richtigen Partner sind entscheidend, um unvorhersehbare Krisen zu überstehen. Dies sind nicht nur bewährte Vorgehensweisen, sondern Ihre Versicherung.
Wollen Sie eine proaktivere und widerstandsfähigere Zukunft gestalten? Warten Sie nicht auf den nächsten Ausfall, denn Ihre Kunden werden es nicht tun.
Lass uns Resilienz zu deiner Superkraft machen. Verbinden Sie sich mit PagerDuty Erfahren Sie, wie unsere KI-gestützte Plattform Ihr Unternehmen am Laufen hält, egal welchen Herausforderungen die Welt sich Ihnen in den Weg stellt.

