
- PagerDuty /
- Blog /
- Nicht kategorisiert /
- Steigerung von Qualität und Zuverlässigkeit durch kontinuierliche Integration
Blog
Steigerung von Qualität und Zuverlässigkeit durch kontinuierliche Integration
von Ranjib Dey
14. April 2014 | 8 Minuten Lesezeit
Continuous Integration (CI) ist eine Softwareentwicklungsmethode, bei der Teammitglieder ihre Arbeit regelmäßig zusammenführen, um Probleme und Konflikte zu minimieren. Jeder Commit wird durch einen automatisierten Build (und Test) unterstützt, um Fehler zu erkennen. Durch die häufige Abstimmung können Teams Software schneller und zuverlässiger entwickeln. Im Wesentlichen geht es bei CI darum, die Codequalität zu überprüfen, um sicherzustellen, dass keine Fehler in die Produktionsumgebung gelangen. Werden Fehler beim Testen gefunden, lässt sich die Fehlerquelle leicht identifizieren und beheben. Durch häufiges Testen des Codes nach jedem Commit kann die Fehlersuche deutlich verkürzt werden. Manuelles Testen des Codes ist jedoch aufwendig und redundant. Da viele Tests wiederverwendet werden können, haben wir mehrere automatisierte Tests erstellt, um häufiges Testen zu vereinfachen. Da diese Tests iterativ sind, erstellen wir nach dem Auffinden eines Fehlers einen Test, der diesen in zukünftigen Code-Reviews sucht, sodass alte Fehler nicht erneut auftreten.
Vor einem automatisierten Build
 Bei PagerDuty wird, sobald wir uns für die benötigten Funktionen entschieden haben, ein JIRA-Ticket erstellt, um die Zusammenarbeit zu vereinfachen und alle Teammitglieder über den Status auf dem Laufenden zu halten. Im Ticket beschreiben wir die Funktion bzw. Fehlerbehebung und deren bekannte Auswirkungen. Anschließend erstellen wir lokale Branches aus unserem Git-Repository für die gewünschte Funktion oder den zu behebenden Fehler und geben ihnen denselben Namen wie dem JIRA-Ticket. Git PagerDuty ist ein verteiltes Versionskontrollsystem (DVCS). Daher gibt es kein zentrales Quellcode-Repository, aus dem wir den Code beziehen, sondern mehrere Arbeitskopien. Dies verhindert einen Single Point of Failure, wie er bei herkömmlichen, auf einem einzigen physischen Rechner basierenden Quellcode-Repositorys auftritt. Redundanz ist uns bei PagerDuty sehr wichtig (mehrere Datenbanken, mehrere Hosting-Anbieter, mehrere Kontaktanbieter für verschiedene Kontaktmethoden usw.). Ein DVCS erleichtert uns die lokale Entwicklung, selbst wenn Probleme auftreten. Bazaar und Mercury sind weitere DVCS, die Sie sich ansehen sollten.
Bei PagerDuty wird, sobald wir uns für die benötigten Funktionen entschieden haben, ein JIRA-Ticket erstellt, um die Zusammenarbeit zu vereinfachen und alle Teammitglieder über den Status auf dem Laufenden zu halten. Im Ticket beschreiben wir die Funktion bzw. Fehlerbehebung und deren bekannte Auswirkungen. Anschließend erstellen wir lokale Branches aus unserem Git-Repository für die gewünschte Funktion oder den zu behebenden Fehler und geben ihnen denselben Namen wie dem JIRA-Ticket. Git PagerDuty ist ein verteiltes Versionskontrollsystem (DVCS). Daher gibt es kein zentrales Quellcode-Repository, aus dem wir den Code beziehen, sondern mehrere Arbeitskopien. Dies verhindert einen Single Point of Failure, wie er bei herkömmlichen, auf einem einzigen physischen Rechner basierenden Quellcode-Repositorys auftritt. Redundanz ist uns bei PagerDuty sehr wichtig (mehrere Datenbanken, mehrere Hosting-Anbieter, mehrere Kontaktanbieter für verschiedene Kontaktmethoden usw.). Ein DVCS erleichtert uns die lokale Entwicklung, selbst wenn Probleme auftreten. Bazaar und Mercury sind weitere DVCS, die Sie sich ansehen sollten.
Schreiben Sie zuerst Tests
Obwohl automatisierte Tests für alle unsere Projekte wünschenswert wären, ist deren Entwicklung zeitaufwändig. Unsere Tests werden vor dem eigentlichen Code erstellt, um unsere Designs zu steuern und schwer testbaren Code zu vermeiden. Diese testgetriebene Entwicklung (TDD) verbessert das Softwaredesign und erleichtert die Code-Wartung. Wir priorisieren die Testkriterien in der untenstehenden Reihenfolge, da sie den größten Einfluss auf Zuverlässigkeit und Ressourcen haben.
1. Sicherheit – Kritische Fehler, die unsere Arbeitsabläufe blockieren, fallen in diese Kategorie. Wenn die Behebung einen geschäftskritischen Codeabschnitt verändert, wollen wir sicherstellen, dass wir alles getestet haben.
2. Strategisch – Umfangreiche Code-Umstrukturierungen und das Hinzufügen neuer Funktionen. Diese Tests führen in der Regel zu entsprechenden Spezifikationen in unserer Testsuite. Dies deckt sowohl positive Testfälle als auch bekannte Regressionen ab. Beispiele hierfür sind das Hinzufügen verschiedener Arten von Diensten/Mikrodiensten (z. B. eines neuen persistenten Speichers) oder eines neuen Tools (das repetitive, zeitaufwändige manuelle Arbeiten automatisiert).
3. Konsistenz Als wachsendes Team müssen wir sicherstellen, dass der erstellte Code leicht verständlich ist und von neuen Mitgliedern problemlos weiterentwickelt werden kann. Dies ist eine bewährte Methode, um Codequalität, Fehlerbehandlung und die Identifizierung von Performance-Problemen zu verbessern. Jeder, der mit Chef vertraut ist, sollte unsere Codebasis verstehen können. Beispielsweise isolieren wir unsere Anpassungen, erfassen sie als separate Patches/Bibliotheken und senden diese an die Upstream-Projekte. In diesen Fällen erstellen wir Spezifikationen für die Integrationsschicht (also die Schnittstelle, die Erweiterungen mit externen Bibliotheken wie Community-Cookbooks, Gems, Tools usw. verbindet).
4. Gemeinsames Wissen Jede Funktionalität basiert auf bestimmten Domänenannahmen. Mithilfe von Tests ermitteln wir diese Domänen und definieren so die Grenzen einer Funktion. Diese Domänen sind stark von unserer Infrastruktur, ihren Abhängigkeiten und der Gesamttopologie abhängig. Ein Beispiel hierfür ist die Generierung dynamischer, suchbasierter Konfigurationsdateien für verschiedene Dienste (z. B. sortieren wir Suchergebnisse vor der Verarbeitung). Wir schreiben Tests, um diese Annahmen zu validieren und durchzusetzen. Dies wird auch von nachgelagerten Toolchains genutzt (z. B. Namenskonventionen für Server, Umgebungen usw.).
Unsere Testsuite
Die von uns erstellten Tests lassen sich in fünf Kategorien einteilen. Um Qualität und Zuverlässigkeit zu gewährleisten, muss jeder erstellte Code – mit Ausnahme der Lasttests – die Tests in der unten angegebenen Reihenfolge bestehen.
Semantische Tests: Wir verwenden Lint-Prüfungen für die allgemeine Semantik des Codes und gängige Best Practices. Rubocop für Rubin-Linting und Foodcritic Für Chef-spezifisches Linting. Diese Tools arbeiten codebasiert, daher funktionieren sie je nach Programmiersprache möglicherweise nicht. Linting-Tools werden nach jedem Commit global angewendet, sodass kein zusätzlicher Code erforderlich ist.
Es gibt mehrere Fälle, in denen Lint-Tests neben dem Aufspüren von Styling-Fehlern auch tatsächliche Fehler aufgedeckt haben. Beispielsweise kann Foodcritic Chef-Ressourcen erkennen, die bei Aktualisierungen keine Benachrichtigung senden.
Unit-Tests: Wir schreiben Unit-Tests für nahezu jeden Codeabschnitt. Bei der Entwicklung von Chef-Rezepten werden zuerst Chefspec-Tests geschrieben. Bei der Erstellung von Ruby-Bibliotheken stehen RSpec-Tests an erster Stelle. Linting und Unit-Tests prüfen nicht die Funktionalität, sondern ob der Code gut oder schlecht strukturiert ist.
Gutes Design erleichtert es anderen Teammitgliedern, den Code schnell zu erfassen und zu verstehen. Diese Tests zeigen außerdem, wie einfach sich der Code entkoppeln lässt. Die Technologie entwickelt sich ständig weiter, und der Code muss flexibel sein. Wenn Ubuntu oder Nginx aus Sicherheitsgründen einen Patch veröffentlichen, wie leicht lässt sich diese Änderung akzeptieren?
Funktionstests: Diese Tests dienen der Überprüfung der Funktionalität als Ganzes, ohne Implementierungskenntnisse und ohne das Mocken oder Stuben von Unterkomponenten. Wir bemühen uns außerdem, die Funktionsspezifikationen so verständlich wie möglich in einfachem Englisch und ohne programmiersprachenspezifische Konstrukte zu verfassen.
Diese Tests helfen bei Folgendem:
Bereitstellung neuer Server
Abbau bestehender Server
eine vollständige Cluster-Bereitstellung
ob eine Abfolge von Operationen funktioniert oder nicht
Wir verwenden Gurke Wir verwenden Aruba, um funktionale Tests zu schreiben. Diese Tests legen keinen Wert darauf, wie der Code geschrieben ist, sondern nur darauf, ob er funktioniert. Cucumber ist ein BDD-Tool, mit dem Spezifikationen lesbar (mittels Gherkin) formuliert werden können, während Aruba eine Cucumber-Erweiterung für das Testen von Kommandozeilenanwendungen ist. Da die meisten unserer Tools eine Kommandozeilenschnittstelle (CLI) bieten, empfinden wir diese Testwerkzeuge als sehr praktisch und benutzerfreundlich.
Integrationstests: Diese Tests stellen sicher, dass alles in Kombination mit allen anderen Diensten in einer produktionsnahen Topologie und unter produktionsnahen Verkehrsbedingungen einwandfrei funktioniert. Sie helfen uns auch zu klären, ob unsere Systemautomatisierungssuite reibungslos mit verschiedenen Diensten und allen Änderungen, die an diesen Diensten oder anderen von uns genutzten Drittanbieterdiensten vorgenommen werden, zusammenarbeitet.
Lasttests: Dies hilft uns, die maximal bewältigbare Datenmenge zu ermitteln und die größten Leistungsengpässe schnell zu identifizieren. Wir führen eine Reihe von Vorbereitungsaufgaben durch, um ein produktionsnahes Datenvolumen zu gewährleisten. Da diese Tests in der Regel zeit- und ressourcenintensiv sind, werden sie regelmäßig für verschiedene Codeänderungen durchgeführt (Batch-Tests). Codeänderungen, bei denen die Leistung unserer Meinung nach keine Rolle spielt (Konfigurationsänderungen, UI-Anpassungen), werden mitunter nicht getestet.
Automatisierte Bereitstellung und Plausibilitätsprüfung
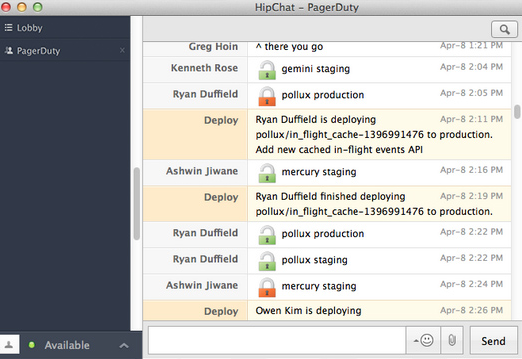 Nachdem der Code alle Tests bestanden hat, übergeben wir ihn an ein anderes Teammitglied zur Überprüfung, bevor er freigegeben wird. Wir führen eine manuelle Code-Überprüfung durch, um eine zweite Meinung einzuholen und sicherzustellen, dass keine Fehler in die Produktionsumgebung gelangen. Die Code-Review durch das Team trägt dazu bei, dass keine Anforderungen übersehen wurden und der Code den Designstandards entspricht.
Nachdem der Code alle Tests bestanden hat, übergeben wir ihn an ein anderes Teammitglied zur Überprüfung, bevor er freigegeben wird. Wir führen eine manuelle Code-Überprüfung durch, um eine zweite Meinung einzuholen und sicherzustellen, dass keine Fehler in die Produktionsumgebung gelangen. Die Code-Review durch das Team trägt dazu bei, dass keine Anforderungen übersehen wurden und der Code den Designstandards entspricht.
Wir verwenden einen halbautomatischen Deployment-Prozess, bei dem CI-Systeme Tests und projektspezifische Tools (wie Capistrano und Chef) unterstützen und den Deployment-Prozess begleiten. Der eigentliche Deployment-Vorgang wird jedoch manuell angestoßen. Das Deployment-Tool benachrichtigt alle Teilnehmer im PagerDuty HipChat-Raum, sobald ein Deployment ansteht. Anschließend werden sowohl Vor- als auch Nachbereitungsbenachrichtigungen (als Sperr- und Entsperr-Servicemeldungen) versendet. Dies hilft uns, den Deployment-Vorgang zu verstehen und gleichzeitige Deployments zu vermeiden.
Mit Continuous Integration schaffen wir eine grundlegende Softwarequalität, die eingehalten und aufrechterhalten werden muss, wodurch das Risiko bei unseren Releases verringert wird.
Diese könnten Ihnen auch gefallen...

