
- PagerDuty /
- Der Blog /
- Vorfallmanagement und -reaktion /
- Failure Friday: So stellen wir sicher, dass PagerDuty immer zuverlässig ist
Der Blog
Failure Friday: So stellen wir sicher, dass PagerDuty immer zuverlässig ist
von Kenneth Rose
20. November 2013 | 7 Minuten Lesezeit
Fragen Sie jeden PagerDutonianer nach der wichtigsten Anforderung an unseren Service, und Sie erhalten immer die gleiche Antwort: Zuverlässigkeit. Unsere Kunden verlassen sich darauf, dass wir sie bei Systemproblemen pünktlich und jederzeit benachrichtigen, egal ob Tag oder Nacht.
Unser Code wird in drei Rechenzentren und bei zwei Cloud-Anbietern eingesetzt, um die Zustellung aller Telefon-, SMS-, Push- und E-Mail-Benachrichtigungen sicherzustellen. Kritische Pfade in unserem Code verfügen über Backups; und unser Code verfügt über Backups für die Backups. Diese dreifache Redundanz stellt sicher, dass niemand eine Benachrichtigung verschläft, eine SMS verpasst oder eine E-Mail verpasst.
Wir brauchen mehr als fehlertolerantes Design
Ein fehlertolerantes Design ist zwar großartig, doch manchmal gibt es Implementierungsprobleme, die dazu führen, dass diese Designs nicht wie vorgesehen funktionieren. Beispielsweise können Backups, die nur bei Störungen greifen, Fehler verbergen oder Code, der in einer Testumgebung einwandfrei funktioniert, unter Produktionslast jedoch versagt. Cloud-Hosting erfordert, dass wir für den Fall eines Infrastrukturausfalls planen.
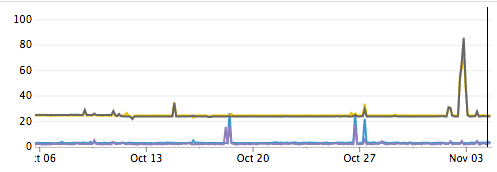
Auch das Internet selbst ist eine Fehlerquelle. Wir beobachten regelmäßig dramatische Anstiege der Latenz und Paketverluste zwischen Rechenzentren. Einige dieser Ereignisse lassen sich auf bekannte Probleme wie DDoS-Angriffe zurückführen, andere sind unbekannt. In beiden Fällen können wir nichts dagegen tun, außer sie technisch zu umgehen.
Rechenzentrumsübergreifende Latenz in Millisekunden
Netflix hat dieses Problem mit seiner Simian Army gelöst: einer Reihe automatisierter Tools, die Anwendungen auf Ausfallsicherheit testen. Chaos Monkey fährt Instanzen herunter, die über Auto-Scaling-Gruppen neu gestartet werden. Latency Monkey führt künstliche Latenz in Netzwerkaufrufe ein. Chaos Gorilla fährt eine ganze Verfügbarkeitszone herunter. Obwohl einige dieser Tools kostenlos verfügbar sind, gehen sie davon aus, dass Ihre Anwendung ausschließlich in AWS mithilfe von Auto-Scaling-Gruppen bereitgestellt wird, während unsere Anwendung über mehrere Anbieter verteilt ist.
Da wir uns nicht mit der Entwicklung eigener Tools aufhalten wollten, haben wir uns für eine unkomplizierte Methode entschieden. Vereinbaren Sie einfach einen Termin und führen Sie die Tests manuell durch. Wir verwenden für alle unsere Tests gängige Linux-Befehle, was den Einstieg erleichtert.
PagerDuty Failure Friday-Vorteile
Wir führen den Failure Friday seit einigen Monaten hier bei PagerDuty durch. Wir haben bereits eine Reihe von Vorteilen festgestellt:
- Deckt Implementierungsprobleme auf die unsere Widerstandsfähigkeit verringern.
- Entdeckt proaktiv Mängel um zu vermeiden, dass diese Diskrepanzen zur Ursache eines zukünftigen Ausfalls werden.
- Baut eine starke Teamkultur auf Indem wir uns einmal pro Woche als Team treffen, um Wissen auszutauschen. Die Betriebsabteilung kann lernen, wie die Entwicklungsteams Produktionsprobleme in ihren Systemen beheben. Die Entwickler erhalten ein besseres Verständnis für die Bereitstellung ihrer Software. Und es ist ein nettes Extra, neue Mitarbeiter freitags um 11 Uhr im Umgang mit Ausfällen zu schulen, anstatt samstags um 3 Uhr morgens.
- Erinnert uns daran, dass es zu Fehlern kommen wird. Ein Ausfall wird nicht länger als ein Zufall betrachtet, der ignoriert oder wegdiskutiert werden kann. Der gesamte Code, den die Entwicklungsteams schreiben, wird nun auf seine Überlebenschancen am Failure Friday getestet.
Vorbereitung unseres Teams auf den Misserfolg am Freitag
Bevor der Failure Friday beginnt, ist es wichtig, dass wir eine Agenda mit allen Fehlern erstellen, die wir vorstellen möchten. Wir planen ein einstündiges Meeting und arbeiten an so vielen Themen wie möglich.
Das Einschleusen von Fehlern kann schwerwiegendere Folgen haben als gewünscht. Daher ist es wichtig, dass alle Teammitglieder mit der Idee einverstanden sind, Fehler in Ihr System einzuführen. Um das Risiko zu minimieren, stellen wir sicher, dass alle Teammitglieder informiert und miteinbezogen werden.
Zur Vorbereitung des ersten Angriffs deaktivieren wir alle Cron-Jobs, die während der Stunde laufen sollen. Das Team, dessen Dienst wir angreifen, wird mit Dashboards ausgestattet, um seine Systeme während der Einschleusung des Fehlers zu überwachen.
Kommunikation ist am Failure Friday unerlässlich. Bei PagerDuty nutzen wir einen dedizierten HipChat-Raum und eine Telefonkonferenz, um Informationen schnell auszutauschen. Der Chatroom ist besonders nützlich, da er uns ein zeitgestempeltes Protokoll der durchgeführten Aktionen liefert, das wir mit den erfassten Kennzahlen korrelieren können.
Wir lassen auch unsere PagerDuty Warnmeldungen aktiviert, um zu bestätigen, dass wir Warnungen erhalten, und um zu sehen, wie schnell sie im Verhältnis zum aufgetretenen Fehler eintreffen.
Einführung von Fehlern in unser System
Jeder Angriff auf unseren Dienst dauert fünf Minuten. Zwischen den Angriffen bringen wir den Dienst stets wieder in einen voll funktionsfähigen Zustand und prüfen, ob alles ordnungsgemäß funktioniert, bevor wir mit dem nächsten Angriff fortfahren.
Während des Angriffs überprüfen wir unsere Dashboards, um zu verstehen, welche Kennzahlen auf das Problem hinweisen und wie sich dieses auf andere Systeme auswirkt. Außerdem notieren wir in unserem Chatroom, wann wir angepiept wurden und wie hilfreich die Anpiepung war.
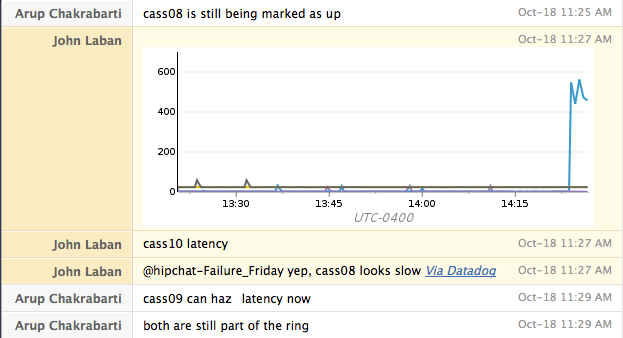
Bei jedem Angriff beginnen wir zunächst mit einem einzelnen Host. Verhält sich dieser wie erwartet, wiederholen wir den Test mit einem gesamten Rechenzentrum. Bei ausschließlich auf AWS gehosteten Diensten testen wir, ob ein Dienst den Verlust einer gesamten Verfügbarkeitszone überlebt.
Angriff Nr. 1: Prozessfehler
Unser erster Angriff ist recht einfach: Wir stoppen den Dienst für 5 Minuten. Dies ist normalerweise genauso einfach wie „sudo service cassandra stop“. Wir gehen davon aus, dass der Dienst trotz Kapazitätsverlust weiterhin Datenverkehr verarbeitet. Oftmals werden wir feststellen, ob unsere Alarme den Dienst korrekt als nicht verfügbar identifizieren. Um ihn wieder zu starten, führen wir „sudo service cassandra start“ aus.
Angriff Nr. 2: Hosts neu starten
Nachdem wir erfolgreich bestätigt haben, dass wir den Verlust eines einzelnen Knotens und eines gesamten Rechenzentrums überleben können, starten wir die Maschinen neu. Dieser Angriff bestätigt, dass die Maschine nach dem Neustart alle erforderlichen Dienste korrekt startet. Er hilft uns auch, Fälle zu erkennen, in denen unsere Überwachung an die Maschine gebunden ist, auf der der Dienst ausgeführt wird, sodass wir während des Herunterfahrens keine Benachrichtigung erhalten.
Angriff Nr. 3: Netzwerkisolation
Bei den beiden vorherigen Angriffen wurden die Dienste ordnungsgemäß beendet und die Rechner anschließend neu gestartet. Der nächste Angriff prüft unsere Widerstandsfähigkeit gegenüber unerwarteten Ausfällen. Wir blockieren die Netzwerkverbindung über iptables. Wir verwerfen sowohl eingehende als auch ausgehende Pakete. Dieser Test prüft, ob Clients angemessene Timeouts konfiguriert haben und nicht auf ordnungsgemäße Dienstabschaltungen angewiesen sind.
| sudo iptables -I INPUT 1 -p tcp –dport $PORT_NUM -j DROP |
| sudo iptables -I OUTPUT 1 -p tcp –sport $PORT_NUM -j DROP |
Um die Firewall nach Abschluss zurückzusetzen, laden wir sie einfach von der Festplatte neu:
| sudo rebuild-iptables |
Angriff Nr. 4: Langsamkeit des Netzwerks
Unser letzter Angriff testet, wie der Dienst mit Langsamkeit umgeht. Wir simulieren einen langsamen Dienst auf Netzwerkebene mit tc.
| sudo tc qdisc add dev eth0 root netem Verzögerung 500 ms 100 ms Verlust 5 % |
Dieser Befehl verzögert den gesamten Netzwerkverkehr um 400–600 Millisekunden. Zusätzlich kommt es zu einem Paketverlust von 5 %. Bei diesem Fehler ist in der Regel mit Leistungseinbußen zu rechnen. Idealerweise können Clients die Verzögerung umgehen. Ein Cassandra-Client könnte beispielsweise mit den schnelleren Knoten kommunizieren und den Datenverkehr an den beeinträchtigten Knoten vermeiden. Dieser Angriff testet, wie gut unsere Dashboards den langsamen Knoten identifizieren. Beachten Sie, dass dies auch Auswirkungen auf Live-SSH-Sitzungen hat.
Die Verzögerung kann problemlos rückgängig gemacht werden.
| sudo tc qdisc del dev eth0 root netem |
Zusammenfassung
Sobald wir mit dem Failure Friday fertig sind, veröffentlichen wir eine Entwarnung und aktivieren unsere Cron-Jobs wieder. Im letzten Schritt erfassen wir alle umsetzbaren Erkenntnisse und weisen sie einem unserer Teammitglieder in JIRA zu.
Mit Failure Friday können wir Probleme nicht nur beheben, sondern auch verhindern, dass sie überhaupt auftreten. Die Zuverlässigkeit von PagerDuty ist uns äußerst wichtig, und durch die Teilnahme unseres Teams am Failure Friday gewährleisten wir sie.
Möchten Sie mehr erfahren? Schauen Sie sich Doug Barths Vortrag über Failure Friday an, der hier im PagerDuty -Hauptquartier gefilmt wurde!
4 Jahre später
Schauen Sie sich unbedingt unseren nächsten Blogbeitrag an: „ Failure Fridays: 4 Jahre danach „, um zu sehen, wie sich unser Prozess im Laufe der Jahre entwickelt hat.
Das könnte Ihnen auch gefallen ...

