
- PagerDuty /
- Der Blog /
- Best Practices und Einblicke /
- Von der Ticket-Zeit zur Echtzeit: Den Status Quo der Betriebsarbeit ändern
Der Blog
Von der Ticket-Zeit zur Echtzeit: Den Status Quo der Betriebsarbeit ändern
von PagerDuty
15. Juni 2021 | 7 Minuten Lesezeit
Dieser Blog war zuvor veröffentlicht am 27. Mai 2021.
2020 war… hart
Ein digitales Unternehmen am Laufen zu halten, war noch nie eine leichte Aufgabe, insbesondere im letzten Jahr. 2020 zwang viele Unternehmen dazu, ihre Initiativen zur digitalen Transformation beschleunigen schneller als irgendjemand es sich vorgestellt hat! Kunden fordern mehr Kapazität und Zuverlässigkeit, Unternehmen bringen mehr neue Dienste auf den Markt – schneller als je zuvor, und Unternehmen lernen, neue Remote-Arbeitsmodelle zu nutzen, was Systeme und Mitarbeiter belastet.
Komplexität ist die neue Normalität
Im operativen Bereich gab es schon immer eine Mischung aus veralteten und neuen Anwendungen. Doch mit dem Aufkommen von Public Cloud, Containern und Microservices hat die Systemkomplexität zugenommen. Selbst für mittelständische SaaS-Unternehmen.
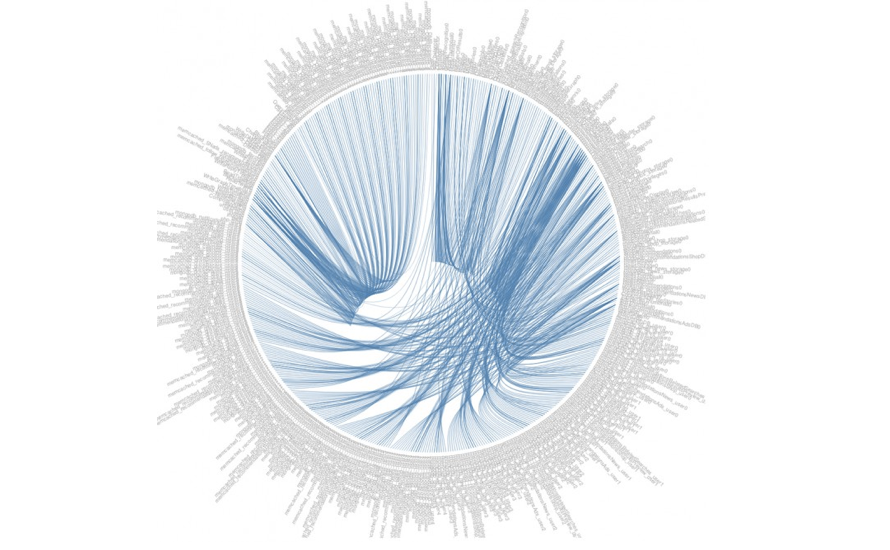
Visuelle Darstellung von Diensten für ein mittelgroßes SaaS-Unternehmen
Betriebsteams sind es gewohnt, mit Ausfällen umzugehen. Mit dem zunehmenden Umfang und der Komplexität heutiger Dienste treten Probleme und Ausfälle jedoch häufiger auf und können deutlich schwieriger zu beheben sein. Hinzu kommt der Druck, die Prozesse zu öffnen, damit das Unternehmen schneller agieren kann, gleichzeitig aber auch die Prozesse abzusichern und die Compliance zu gewährleisten.
Es ist natürlich keine leichte Aufgabe, die Nase vorn zu behalten. Wie kann ein Unternehmen schneller vorankommen und gleichzeitig Risiken vermeiden? Das Konzept des Echtzeitbetriebs kommt hier zum Einsatz.
Warum Echtzeitoperationen?
Geschwindigkeit ist ein Wettbewerbsvorteil, da sind sich alle einig. Wie kann ein Unternehmen also schneller agieren? Das ist nahezu unmöglich, wenn der Betrieb reaktiv ist. Leider ist dies heute bei vielen Unternehmen der Fall. Wir nennen diesen reaktiven Zustand Ticket-Time-Operationen.
Der Alltag im operativen Geschäft war schon immer eine Mischung aus geplanter und ungeplanter Arbeit. Operationsteams werden häufig von jemandem unterbrochen, der etwas von ihnen verlangt, oder sie unterbrechen jemanden mit einer Anfrage.
Es gibt einen endlosen Strom von Anfragen in Form von Tickets – oft mit der wiederholten Anforderung, dieselbe Aufgabe zu erledigen. Beispielsweise benötigen die Entwicklungsteams möglicherweise bei jeder neuen Version vom Netzwerkteam eine Änderung an einer Firewall-Regel. Das Netzwerkteam muss seine Arbeit unterbrechen, um die Änderung vorzunehmen. Diese Änderung muss jedoch auch vom Sicherheitsteam genehmigt werden, bevor sie live geht. Nun unterbricht das Netzwerkteam das Sicherheitsteam und wartet auf dessen Hilfe. Währenddessen jongliert jeder mit seiner eigenen Arbeit.
Die Branche hat sich an diese Arbeitsweise gewöhnt, doch die Ergebnisse sind nicht gerade berauschend. Ingenieure sind frustriert, überlastet und unterfordert, und Unternehmer haben das Gefühl, dass alles zu lange dauert, zu teuer ist und zu oft kaputtgeht.
So stehen wir heute da. Die Anforderungen an den IT-Betrieb treiben die IT bis an die Grenzen ihrer Belastbarkeit. Ein langsames, reibungsintensives und kostenintensives Ticket-Time-Betriebsmodell ist nicht länger tragbar. Stattdessen muss der Betrieb auf Echtzeitbetrieb umgestellt werden.
Was meinen wir mit „Echtzeit“? Echtzeit bedeutet, Entscheidungen zu treffen und im Einklang mit der Geschwindigkeit des Geschäftsbetriebs zu handeln. Es bedeutet sofortige Kommunikation und Entscheidungsfindung. Anstatt Informationen und Kontrolle in Silos zu speichern, wird die Kontrolle auf die gesamte Organisation verteilt, sodass alle in ihrem eigenen Tempo arbeiten und die gesamte Kontrolle behalten.
Drei Möglichkeiten zur Ermöglichung von Echtzeitvorgängen
1. Überwachung, Beobachtbarkeit und AIOps
Überwachung ist eine uralte Praxis, die traditionell in den Zuständigkeitsbereich der operativen Abteilung fällt. Dabei geht es darum, nach Mustern oder Ereignissen zu suchen, die den zuvor beobachteten ähneln, und die zuständigen Personen zu benachrichtigen, wenn diese Bedingungen eintreten.
Der „neueste“ Trend ist die Observability. Sie misst, wie gut man die internen Zustände eines Systems anhand seiner externen Ausgaben verstehen kann. Observability-Tools und -Methoden helfen uns, unsere Dienste zu analysieren und herauszufinden, was wirklich vor sich geht.
Es basiert auf:
- Veranstaltungen: Handelt es sich bei diesem einzelnen Ereignis um etwas, das schon einmal passiert ist?
- Metriken : Betrachten Sie diese Ereignisse und fragen Sie sich: Werden die Dinge besser oder schlechter?
- Verteilte Ablaufverfolgung: Schauen Sie sich die neuen verteilten Infrastrukturen an und verstehen Sie, wie diese Ereignisse die einzelnen Komponenten durchlaufen.
Obwohl das Monitoring traditionell in der operativen Abteilung angesiedelt ist, sehen wir, dass Observability auch von Entwicklern vorangetrieben wird. Monitoring und Observability ermöglichen Echtzeit-Operationen, indem sie eine bessere Transparenz zwischen den Teams schaffen und uns helfen, die tägliche Funktionsweise der Systeme zu verstehen.
Und nicht zuletzt gibt es AIOps. AIOps kombiniert Tool-Funktionen, um das Geschehen in Echtzeit zu verstehen. AIOps bietet ähnliche Lösungen wie bestehende Event-Management-Lösungen, beinhaltet aber zusätzliche Funktionen, die für die komplexen, modernen Umgebungen von heute erforderlich sind, wie maschinelles Lernen, Automatisierung, flexible Datenerfassung und -aufnahme, leistungsstarke Visualisierungen und mehr. Es geht darum, alle Informationen und Signale der gesamten Infrastruktur zu nutzen, Metriken zu aggregieren, Störungen zu reduzieren, Korrelation und Verständnis zu verbessern und Muster zu erkennen. Erfahren Sie, wie Sie AIOps für ein besseres Incident Management nutzen.
2. Service-Eigentümerschaft
In einer zunehmend komplexen digitalen Welt wird der Begriff des Serviceeigentums immer wichtiger.
Organisationen müssen wissen:
- Was passiert, wenn etwas schief geht?
- Was sind die Abhängigkeiten?
- Und wer ist der Verantwortliche?
Mithilfe der Service Ownership-Praxis lässt sich eine Karte erstellen, die diese Fragen beantwortet und Unternehmen dabei hilft, die Interaktion zwischen den Teams und technischen Systemen, mit denen sie interagieren, zu verstehen.
Dienste werden ausfallen; das ist eine Tatsache. Wie ein Unternehmen auf einen Ausfall reagiert, kann entscheidend dafür sein, ob es Kunden behält oder verliert.
Die vollständige Serviceverantwortung trägt zur Optimierung des Incident-Response-Lebenszyklus bei, indem sie Ingenieuren die Verantwortung für ihre Services in der Produktion überträgt. Dies reduziert die Anzahl der Übergaben und kann die mittlere Reaktionszeit (MTTR) bei Incidents deutlich verkürzen. Fachexperten mit direktem Wissen über die von ihnen betreuten Systeme als Ersthelfer tragen dazu bei, das unvermeidliche Chaos und die Panik, die durch Unsicherheit entstehen, zu verringern.
3. Self-Service-Betrieb
Für Unternehmen, die von einem reaktiven, ticketgesteuerten Ansatz zu einem proaktiven Ansatz wechseln möchten, ist das Self-Service-Betriebsmodell ein wichtiger Faktor für den Echtzeitbetrieb.
Was bedeutet „Echtzeit“ im Zusammenhang mit Self-Service? Anstatt Informationen und Kontrolle in funktionalen Silos zu speichern, delegiert Self-Service die Kontrolle an die richtigen Personen im Unternehmen.
Ein Teil des Self-Service besteht in der Informationsübermittlung, beispielsweise in der Weitergabe von Systemkontext, Transparenz, Serviceverantwortung, den richtigen Runbooks und Entscheidungsunterstützung. Ein weiterer Teil besteht darin, Fachexperten die Möglichkeit zu geben, sich auf geschäftswertschöpfende Aufgaben zu konzentrieren – anstatt ständig durch Anfragen unterbrochen zu werden.
Im Incident-Management-Szenario bedeutet dies, dass Ersthelfer über die notwendigen Informationen und die Kontrolle verfügen, um Maßnahmen ergreifen zu können oder KI in ihrem Namen handeln zu lassen. Dies führt zu einer schnelleren Lösung und weniger störenden Eskalationen!
Self-Service mit Runbook-Automatisierung
Mit der Runbook-Automatisierung können Sie Self-Service erstellen. Runbook-Automatisierung ermöglicht es den Fachexperten, Arbeitsabläufe zu definieren, die verschiedene Tools, Skripte, APIs, Berechtigungen, Anmeldeinformationen und Befehlszeilenprozeduren umfassen, und diesen Prozess an die Personen zu delegieren, die ihn benötigen.
Durch die Runbook-Automatisierung können die richtigen Mitarbeiter Aufgaben sicher erledigen, die bisher nur Fachexperten vorbehalten waren. Außerdem können Ihre Fachexperten ihre Best Practices in allgemein anwendbare Vorgehensweisen umwandeln.
Die Runbook-Automatisierung kann über den gesamten Lebenszyklus hinweg eingesetzt werden. Bei der Reaktion auf Vorfälle können Mitarbeiter Probleme diagnostizieren und automatisierte Aktionen ausführen, die sie normalerweise an Experten weiterleiten müssten. Dies funktioniert auch bei alltäglichen Serviceanfragen. Bei Bereitstellungs-, Änderungs- und Wartungsaufgaben können Mitarbeiter dank der Runbook-Automatisierung Aufgaben selbst erledigen, anstatt ständig auf jemanden zu warten. Erfahren Sie mehr über Self-Service-Operationen.
Unsere Chance, die operative Arbeit zu transformieren, erstreckt sich über den gesamten Lebenszyklus. Die Anwendung des Echtzeit-Betriebsfokus auf diese anderen Ops-Arbeitsaufgaben kann die Geschäftsgeschwindigkeit deutlich steigern! Erfahren Sie, wie PagerDuty Ihnen helfen kann. Melden Sie sich für eine kostenlose 14-tägige Testversion an Heute.
Das könnte Ihnen auch gefallen ...

