4 neue Möglichkeiten zur Verbesserung des Vorfallmanagements mit Event Orchestration
von Hannah Culver
11. September 2024 | 5 Minuten Lesezeit
In einer Zeit, in der Effizienz und intelligente Technologieintegration entscheidend sind, 71 % der technischen Führungskräfte berichten, dass ihre Unternehmen in diesem Jahr ihre Investitionen in künstliche Intelligenz (KI) und maschinelles Lernen (ML) ausweiten. Angesichts der enormen Datenmenge, die in Unternehmen eingeht, und der Notwendigkeit einer zeitnahen Reaktion ist die Überwachung aller eingehenden Warnmeldungen rund um die Uhr unpraktisch, und menschliche Wachsamkeit allein ist zu ungenau. Stattdessen können datenbasierte Vorhersagen, die auf der historischen Funktionsweise Ihres Systems basieren, einen effektiveren Ansatz für die Bewältigung und Reaktion auf Vorfälle bieten. Hier kommt die Event Orchestration von PagerDuty ins Spiel.
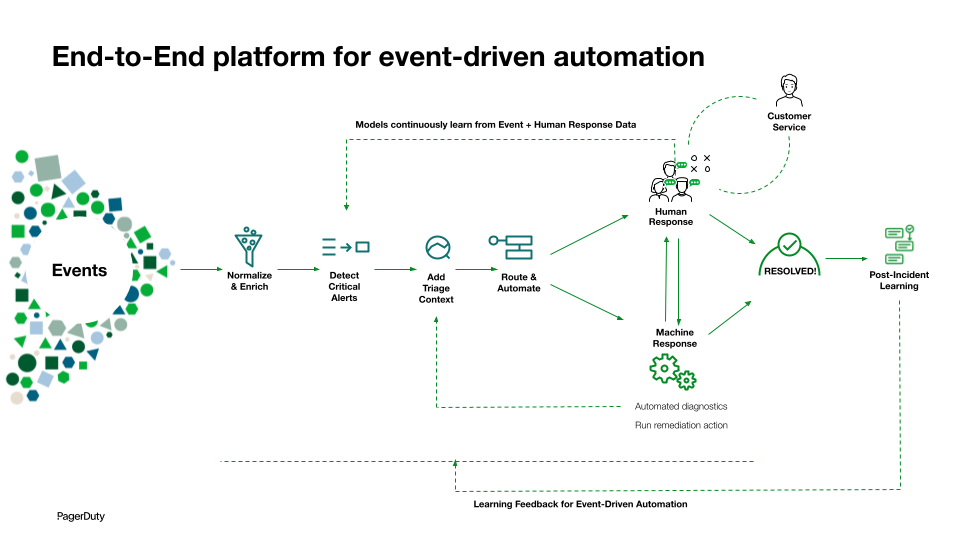
Event Orchestration unterstützt Unternehmen dabei durch die Schaffung einer durchgängigen ereignisgesteuerten Automatisierung. Diese Funktion verbessert die Erkennung von Vorfällen, die schnellere Korrelation von Ursachen und die Skalierung Betriebsreife über technische Teams hinweg, damit diese kohärenter und effektiver arbeiten können.
Mit Event Orchestration-Variablen Teams können intelligente Automatisierungen entwickeln, die sich nahtlos in andere Tools und Prozesse integrieren lassen. So wird eine gezieltere und unternehmensweit standardisierte Reaktion auf Vorfälle ermöglicht. Die neue Event Orchestration-Funktion hilft Ihnen, aus vergangenen Vorfällen zu lernen und deren Wiederholung zu verhindern. Das Ergebnis ist eine proaktivere Betriebsführung mit skalierbaren und wiederholbaren Ergebnissen, die dem gesamten Technologie-Ökosystem zugutekommen.
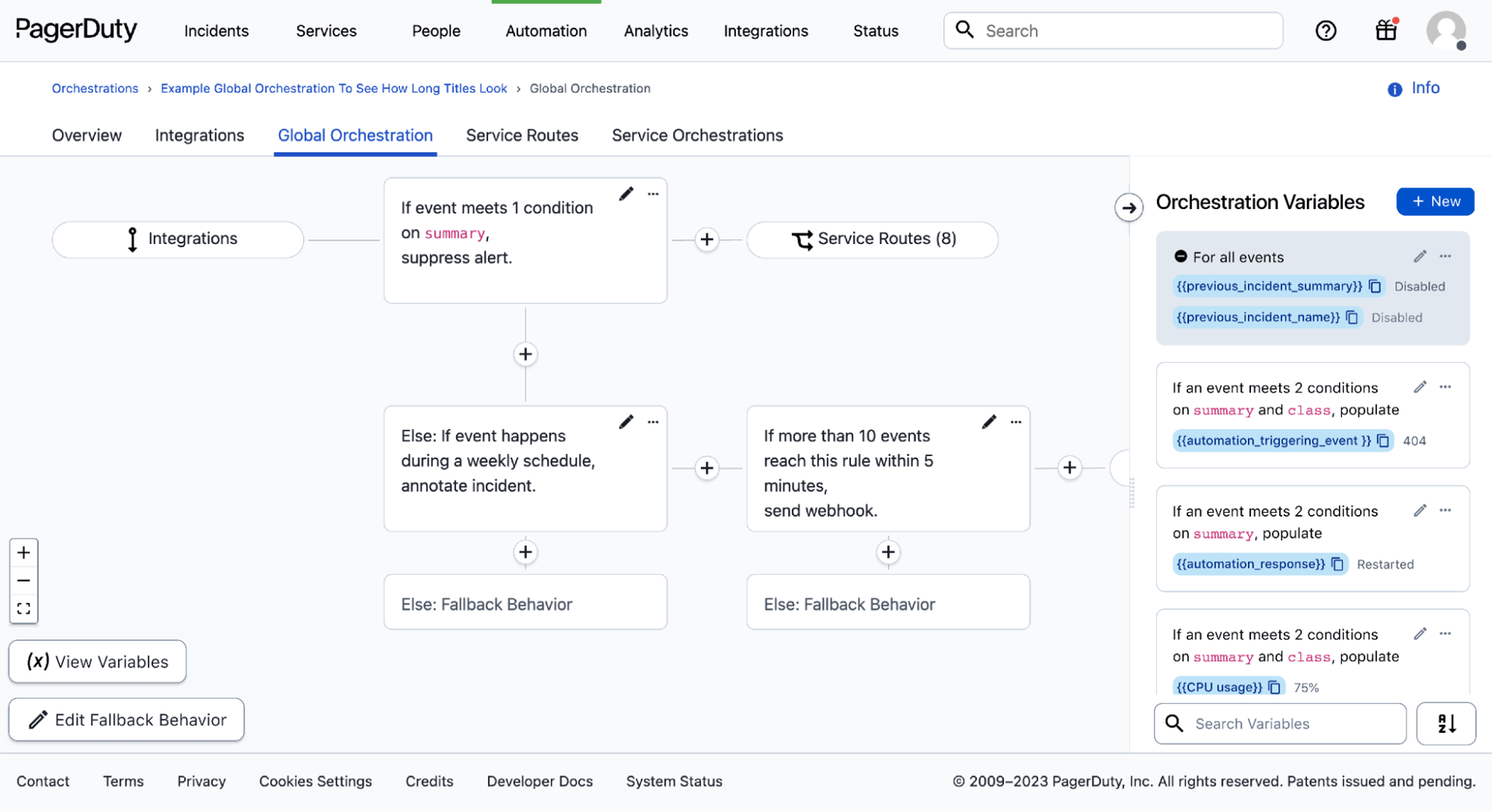
Lassen Sie uns vier Möglichkeiten betrachten, wie Sie diese neue Funktion heute nutzen können.
1. Automatisierung des Major Incident Managements
Die meisten Organisationen behandeln schwerwiegende Vorfälle anders als Vorfälle mit niedrigerer Priorität. Ein schwerwiegender Vorfall kann andere Eskalationspfade, Arbeitsabläufe und interne Prozesse erfordern. Daher ist die Automatisierung bei schwerwiegenden Vorfällen oft individueller.
Mithilfe von Event Orchestration-Variablen können Teams nun schwerwiegende Vorfälle vorhersagen und die automatisierte Bearbeitung der Vorfälle steuern. Sie können beispielsweise einen Schwellenwert für Ereignisse definieren, der die richtigen Prozesse für schwerwiegende Vorfälle auslöst, wenn die Ereigniskriterien Ihren bekannten Kriterien entsprechen. Event Orchestration behandelt nicht jedes Ereignis als einzelne, separate Instanz. Stattdessen nutzt es Ereignisse als historische Grundlage, um fundierte Entscheidungen über den Systemzustand im Zeitverlauf zu treffen.
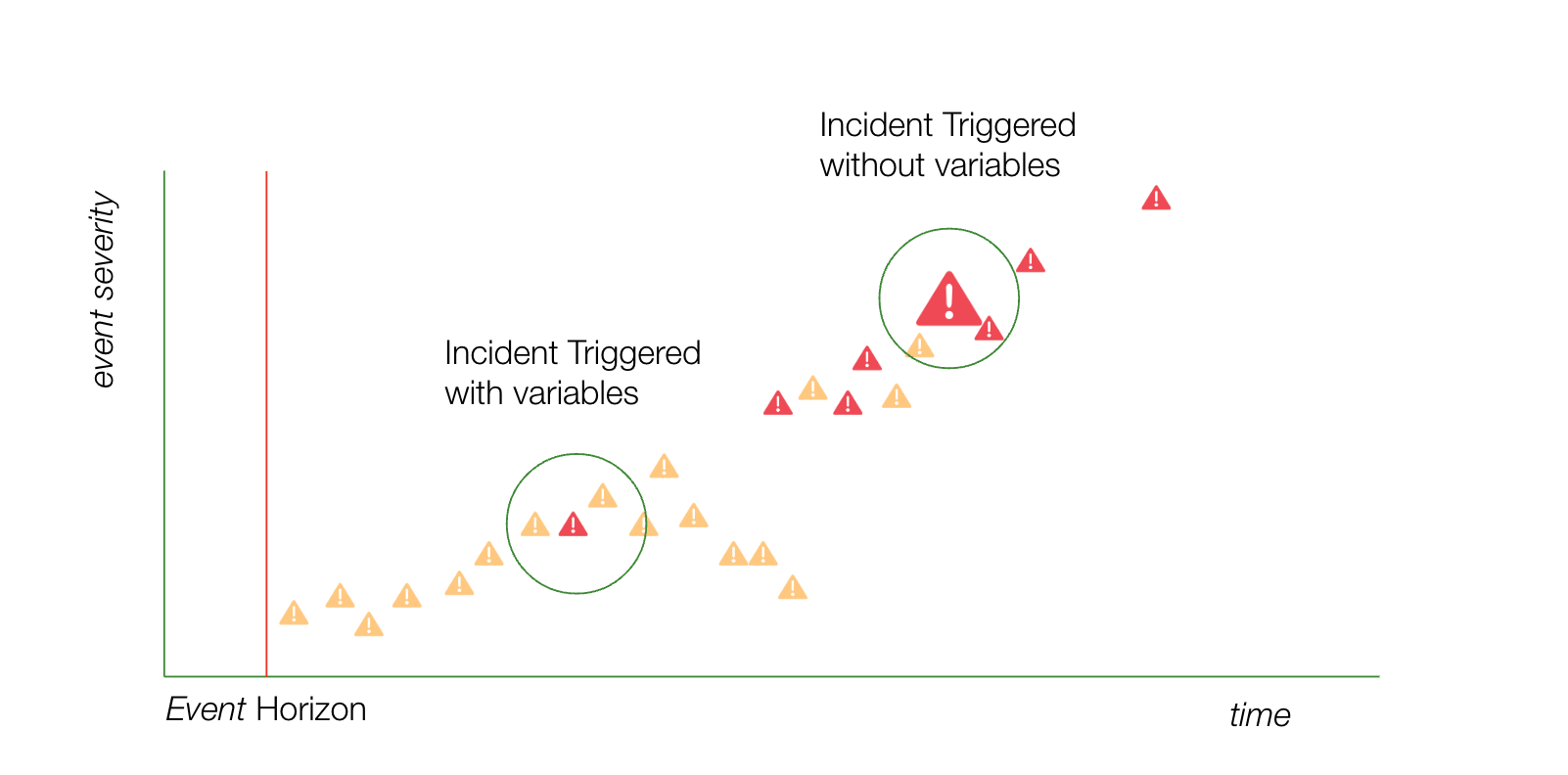
Dieser neue Ansatz unterscheidet sich von herkömmlichen Ansätzen, bei denen schwerwiegende Vorfälle automatisiert ausgelöst werden. Anstatt ein einzelnes Ereignis als Indikator für einen schwerwiegenden Vorfall zu betrachten, können Sie Ihren Systemzustand präziser bewerten, indem Sie wissen, was kürzlich passiert ist und wie genau die Umstände mit früheren schwerwiegenden Vorfällen übereinstimmen.
2. Reaktive Automatisierung
Viele Organisationen setzen auf automatisierte Diagnose oder automatische Fehlerbehebung, um den Reaktionskräften einen Vorsprung zu verschaffen. Die Automatisierung ist jedoch nicht selbsterklärend. Sie weiß nicht, welche anderen Ereignisse, die kürzlich im System eingegangen sind, bereits ausgeführt wurden. Daher versucht die Automatisierung oft, ähnliche Ereignisse mehrfach auszuführen, ohne tatsächlich Erkenntnisse oder eine Lösung des Problems zu liefern.
Sie können jetzt eine Automatisierung erstellen, die nachverfolgt, ob Diagnosen ausgeführt wurden, und Automatisierungspfade basierend auf der Antwort anpassen. Wenn beispielsweise kürzlich eine Diagnose für eine Ereignisorchestrierung ausgeführt wurde, erkennt die Automatisierung, dass sie die Diagnose nicht erneut ausführen muss. Außerdem wird eine zusätzliche Automatisierungssequenz wie die automatische Behebung gestartet.
Diese reaktive Automatisierung (oder Automatisierung, die auf intelligente Weise weitere Automatisierung auslöst) gibt Unternehmen mehr Flexibilität und Kontrolle darüber, wann die Automatisierung erfolgt und was mit dem Feedback aus diesen Sequenzen geschehen soll.
3. Dynamische Automatisierung
Unternehmen möchten die Automatisierung fundiert durchführen und gezielt die ausgefallene Anwendung oder Infrastruktur ansprechen. Wenn Sie jedoch nur auf ein einzelnes Ereignis zugreifen können, ist es schwierig zu wissen, welcher Teil Ihres Stacks ausgefallen ist, und die Automatisierung entsprechend auszuführen.
Mithilfe der Event Orchestration können Sie Informationen darüber extrahieren und speichern, in welchen Teilen Ihres Stacks Probleme aufgetreten sind. So können Sie diese Informationen für eine präzisere Ausrichtung in zukünftige Automatisierungen einfließen lassen.
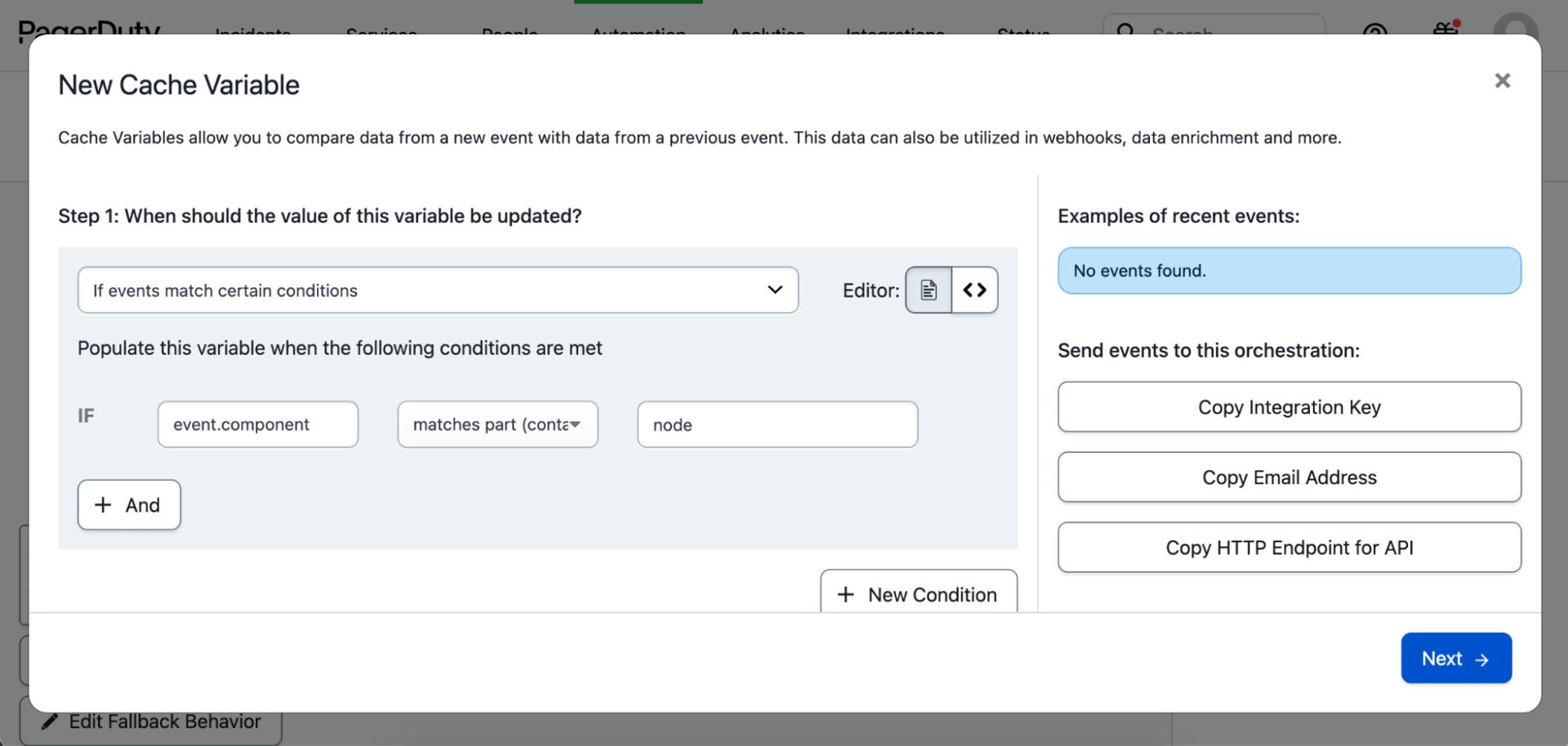
Sie können beispielsweise eine Variable festlegen, die Daten aus einer Nutzlast extrahiert. Wenn die Ereignisnutzlast einem bestimmten Umstand entspricht, z. B. einem Kubernetes-Ereignis, können Sie die Knoteninformationen füllen. Anschließend können Sie eine Automatisierungssequenz erstellen, um genau diesen ausgefallenen Knoten zu identifizieren und dynamisch neu zu starten.
4. Selbstkonfigurierende Automatisierung
Wenn etwas schiefgeht, reicht eine grobe Schätzung des Problems nicht aus. Die Einsatzkräfte müssen sofort über die richtigen Triage-Informationen verfügen, um die Grundursache zu ermitteln und die Problemlösung schnellstmöglich in die Wege zu leiten.
In diesen Fällen können Variablen Unternehmen dabei helfen, sofort die richtigen Triage-Informationen zu erhalten und Fehler in einem System mit Automatisierung zu lokalisieren, das sich während des gesamten Reaktionsprozesses selbst konfiguriert. Wenn beispielsweise ein Ereignis mit einem Teil der Infrastruktur zusammenhängt, bei dem aktuell ein Problem auftritt, konfiguriert die Automatisierung die Regel und fügt wichtigen Kontext wie Notizen hinzu.
Diese neue Funktion macht die Automatisierung innerhalb von PagerDuty skalierbarer und sorgt dafür, dass Informationen schnellstmöglich an die Oberfläche gelangen. Sie reduziert nicht nur den Zeitaufwand für die Behebung von Vorfällen, sondern auch für die Erstellung und Bereitstellung von Automatisierungen in einem komplexen technischen Ökosystem.
Wenn Sie bereits PagerDuty AIOps-Kunde sind und an einer solchen Automatisierung interessiert sind, sehen Sie sich Folgendes an kurze Anleitung oder Twitch-Demo von Principal Product Manager Frank Emery .
Sie sind noch kein PagerDuty AIOps-Kunde? Probieren Sie es noch heute aus und erstellen Sie eine ereignisgesteuerte Automatisierung, die Ihnen hilft, den Arbeitsaufwand zu reduzieren und die Effizienz im gesamten Unternehmen zu verbessern.
Das könnte Ihnen auch gefallen ...