
- PagerDuty /
- Der Blog /
- Automatisierung /
- Debuggen von Kubernetes mit automatisierten Runbooks und flüchtigen Containern
Der Blog
Debuggen von Kubernetes mit automatisierten Runbooks und flüchtigen Containern
von Jake Cohen
2. Mai 2023 | 5 Minuten Lesezeit
In unserem vorheriger Blog Wir haben die Schwierigkeit diskutiert, alle relevanten Diagnosedaten eines Vorfalls zu erfassen, bevor eine Notlösung angewendet wird. Das häufigste konkrete Beispiel hierfür ist eine Anwendung, die in einem Container läuft und der Container neu bereitgestellt wird – möglicherweise auf eine frühere oder die gleiche Version –, nur um das unmittelbare Problem zu lösen. Für Unternehmen, in denen jede Millisekunde Leistung und jede Sekunde Betriebszeit erhebliche Auswirkungen auf das Kundenerlebnis hat, sind solche kurzfristigen Lösungen unerlässlich. Die Kosten für das Unternehmen werden jedoch erheblich, wenn Ingenieure mit der Entwicklung der langfristig Lösung für diese Vorfälle. Sowohl bei größeren als auch bei (wiederkehrenden) kleineren Vorfällen müssen die Ingenieure übermäßig viel Zeit damit verbringen, Beweise für den Zustand der Anwendung und Umgebung zum Zeitpunkt des Vorfalls zu sammeln.
Während ein Großteil dieser Diagnosedaten in Überwachungstools gespeichert ist und daher dauerhaft verfügbar ist, ist es manchmal notwendig, eine Shell in einem Container zu installieren, um Informationen abzurufen, die nur für die Lebensdauer des Containers verfügbar sind. In Kubernetes geschieht dies mithilfe des kubectl exec Befehl. Mit den richtigen Parametern können Benutzer eine Live-Shell in ihrem laufenden Container erhalten und Befehle ausführen, um Diagnosen abzurufen. Sobald ein Benutzer beispielsweise eine Shell in einem Java-Container hat, kann er Folgendes aufrufen: jstack um einen Thread-Dump ihrer Anwendung zu erhalten.
Doch viele Operationsteams lassen nicht zu, irgendjemand exec in Produktions-Pods (wo kritische Vorfälle passieren) oder die Anzahl der Personen, die dazu in der Lage sind, ist sehr gering – sowohl aus Sicherheitsgründen als auch aufgrund der begrenzten Anzahl von Personen, die mit der Bedienung von Kubernetes vertraut sind. Um während eines Vorfalls Diagnosedaten abzurufen, müssen daher regelmäßig Personen mit Kubernetes-Zugriff und -Expertise hinzugezogen werden. Dieser Prozess treibt die Kosten von Vorfällen in die Höhe, da er die MTTR erhöht und die Anzahl der einzubeziehenden Personen erhöht.

Aus diesen Gründen ist es am besten, Automatisierung zu verwenden, die es den Benutzern überflüssig macht, exec in laufende Pods. Bei dieser Automatisierungsarchitektur wird beim Auftreten eines Problems ein automatisiertes Runbook aufgerufen, das die Debug-Daten abruft, an einen persistenten Speicherort (S3, Blob Storage, SFTP-Server usw.) sendet und die Techniker dann darüber informiert, wo sie die Debug-Daten finden und verwenden können.
PagerDuty Process Automation bietet ein vorgefertigtes, vorlagenbasiertes Runbook für genau diesen Anwendungsfall: Wenn eine Warnung einen Vorfall innerhalb von PagerDuty verursacht, kann dies automatisch (oder per Mausklick) das Runbook dazu veranlassen, Befehle im Pod auszuführen, die Ausgabe an einen dauerhaften Speicherort zu senden und Details zum Speicherort dieser Daten im Vorfall bereitzustellen.
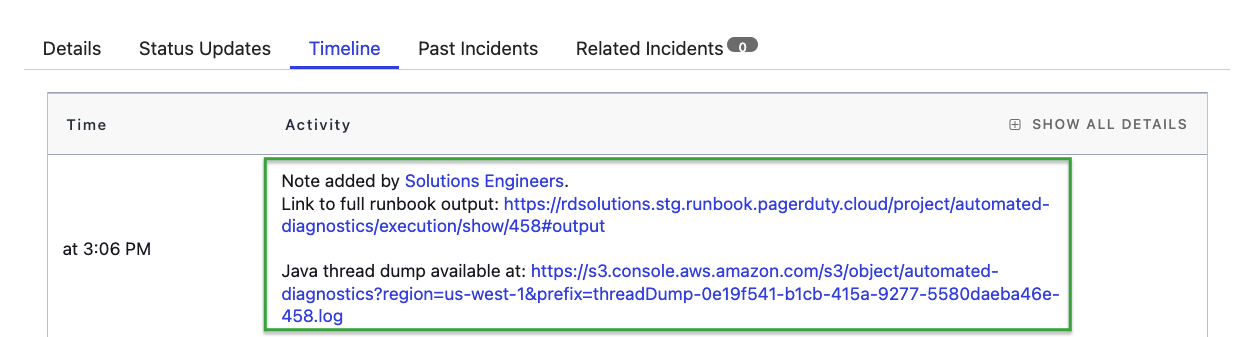
Den Technikern wird während und nach dem Vorfall ein Link zu den Debug-Daten bereitgestellt
Benutzer unserer kommerziellen Automatisierungsprodukte ( Prozessautomatisierung und Runbook-Automatisierung ) und Open Source Rundeck den Anweisungen folgen können Hier um das automatisierte Runbook herunterzuladen und damit zu beginnen.
Dieses automatisierte Runbook ist ideal, wenn das Container-Image bereits über die zum Debuggen erforderlichen Befehlszeilenprogramme (Binärdateien) verfügt. Beispielsweise werden viele containerisierte Java-Apps mit dem jstack Dienstprogramm im Container-Image; was passiert jedoch, wenn die Debugging-Dienstprogramme nicht als Teil des Container-Images ausgeliefert werden? Oder, was immer häufiger vorkommt, was passiert, wenn der Container „distro-los“ ist und daher nicht einmal eine Shell bereitstellt?

Hier ist Kurzlebige Kubernetes-Container ins Spiel – es bietet Benutzern einen Mechanismus, um einen Container (mit einem beliebigen Image) an einen laufenden Pod anzuhängen, ohne die Pod-Definition ändern oder den Pod erneut bereitstellen zu müssen.
Durch die gemeinsame Nutzung des Prozess-Namespaces kann der temporäre Container seine Debugging-Dienstprogramme für einen anderen Container im Pod verwenden – selbst wenn der ursprüngliche Container abgestürzt ist. Hier ist ein Blog von Ivan Velichko, der sehr detailliert auf die gemeinsame Nutzung von Prozess-Namespaces mit flüchtigen Containern eingeht:
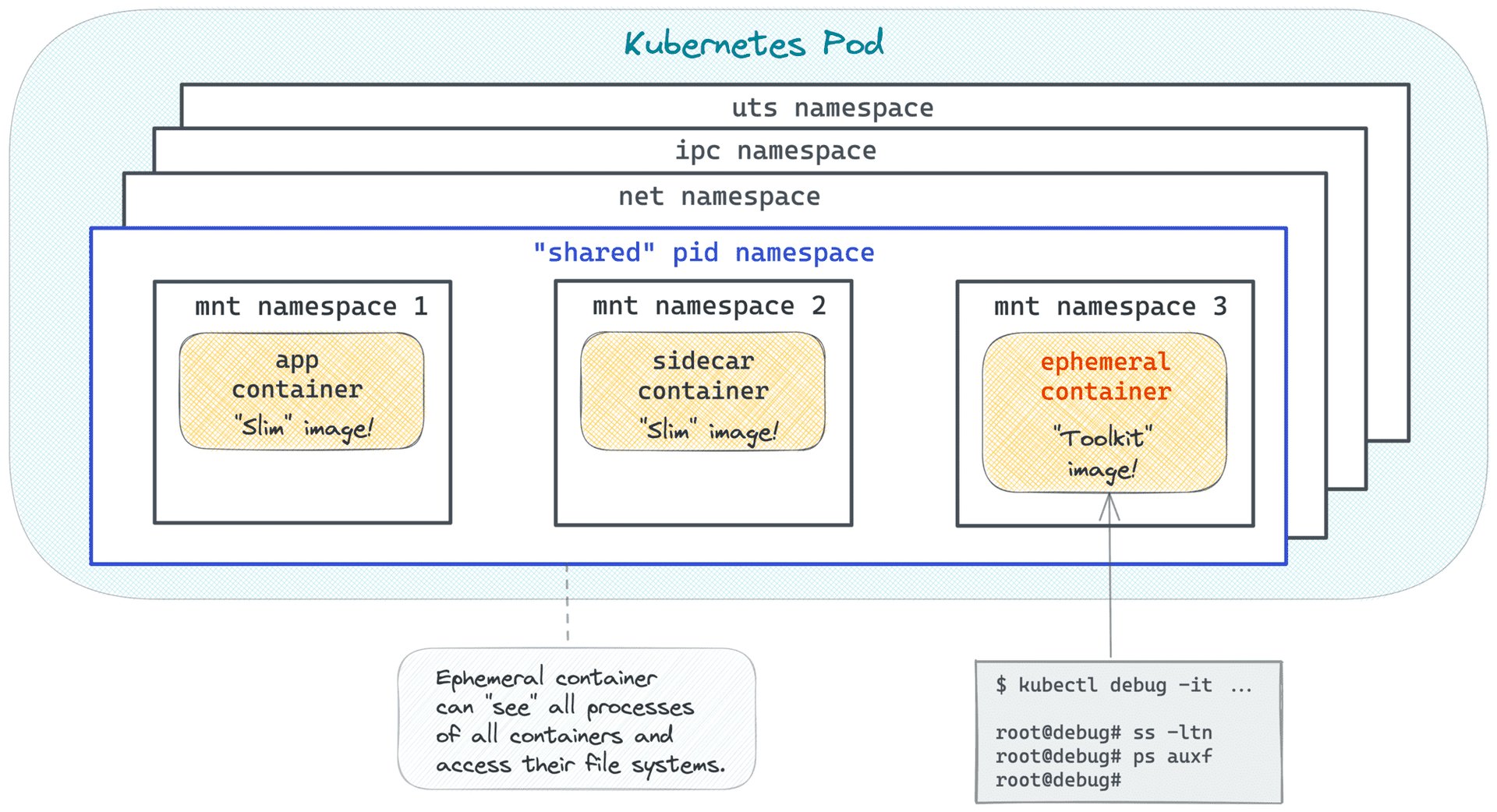
Quelle: https://iximiuz.com/en/posts/kubernetes-ephemeral-containers/
Ähnlich wie bei der Verwendung kubectl exec , erfordert die ordnungsgemäße Nutzung flüchtiger Container immer noch Zugriff auf die Ausführung kubectl Befehle im Kubernetes-Cluster – der für externe Operationen selten verfügbar ist. Und wie zuvor erfordert das Wissen, wie man den Befehl richtig erstellt, ein hohes Maß an Kubernetes-Vertrautheit:
kubectl debug -it -n ${namespace} -c debugger --image=busybox --share-processes ${pod_name}
(Beispielbefehl zur Verwendung von Kubernetes Ephemeral Containers)
Um Benutzern entgegenzukommen, die Container ohne Debugging-Dienstprogramme oder Container ohne Distribution haben, haben wir ein neues Kubernetes-Plugin das die Funktionalität flüchtiger Container nutzt:
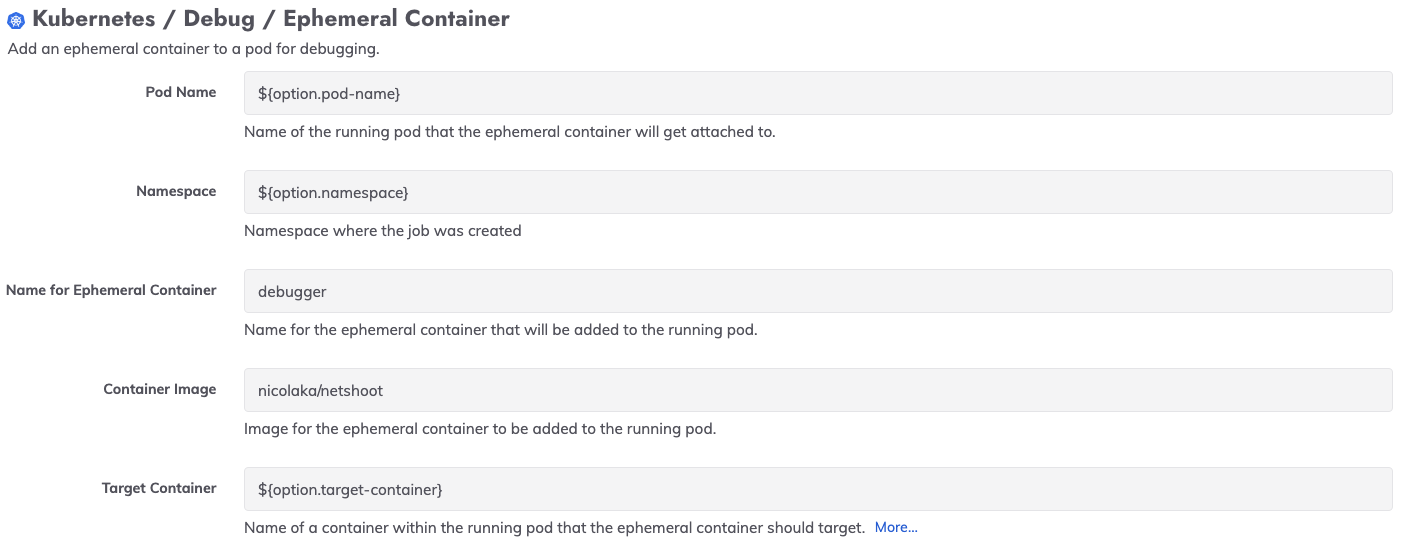
Wir haben dieses Plugin in einer Vorlage für ein automatisiertes Runbook verwendet, das auch Diagnoseausgaben erfasst und an einen persistenten Speicherort sendet. Benutzer von Process Automation und Runbook Automation können mit diesem Vorlagenjob beginnen, indem sie ihn als Teil des Automated Diagnostics Project herunterladen. Hier .
Wenn Sie noch kein Process Automation- oder Runbook Automation-Konto haben, klicken Sie auf Hier um mit den Automatisierungsprodukten von PagerDuty zu beginnen.

