
- PagerDuty /
- Der Blog /
- Unkategorisiert /
- Wer überwacht die Wächter?
Der Blog
Wer überwacht die Wächter?
von Julie Arsenault
30. Oktober 2014 | 4 Minuten Lesezeit
Wie wir unseren eigenen Champagner trinken (und bei PagerDuty überwachen)
Wir versenden monatlich über 4 Millionen Warnmeldungen, und Unternehmen verlassen sich darauf, dass wir sie über Ausfälle informieren. Wer überwacht also die Wächter? Arup Chakrabarti, technischer Leiter von PagerDuty, sprach darüber, wie wir unsere eigenen Systeme überwachen bei den DevOps Days Chicago Anfang des Monats. Hier sind einige Highlights aus seinem Vortrag über die Überwachungstools und -philosophien, die wir hier bei PagerDuty verwenden.
Verwenden Sie das richtige Werkzeug
New Relic ist eines unserer Tools, da es zahlreiche Diagramme und Berichte liefert. Tools für das Application Performance Management liefern Ihnen viele Informationen, was hilfreich ist, wenn Sie Ihre kritischen Kennzahlen nicht genau kennen. Allerdings sind sie oft schwer anzupassen, und all diese Informationen können zu einer „Analyse-Lähmung“ führen.
PagerDuty nutzt außerdem StatsD und DataDog zur Überwachung wichtiger Kennzahlen, da diese einfach zu bedienen und flexibel anpassbar sind. Es kann jedoch etwas dauern (wir haben eine halbtägige Schulung mit unseren Ingenieuren durchgeführt), bis die Teams mit den Kennzahlen vertraut sind. SumoLogic analysiert kritische App-Protokolle, und die PagerDuty Ingenieure richten Warnmeldungen für Muster in den Protokollen ein. Wormly und Monitis bieten externes Monitoring, wobei das Team jedoch eine intelligentere Health-Check-Seite entwickeln musste, die bei unerwarteten Werten warnt. Und schließlich nutzt PagerDuty PagerDuty , um Warnmeldungen aus all diesen Überwachungssystemen zu konsolidieren und uns zu benachrichtigen, wenn etwas schiefgeht.
Vermeiden Sie die Einzelhostüberwachung für verteilte Systeme
„Alles, was auf einer einzelnen Box läuft, ist anfällig und geht im ungünstigsten Moment kaputt“, sagt Chakrabarti. Stattdessen richtet PagerDuty Warnmeldungen auf Cluster-Ebene ein, beispielsweise auf Basis der Gesamtzahl von 500 Fehlern (nicht der Anzahl in einer einzelnen Protokolldatei) und der Gesamtlatenz (nicht der Latenz einer einzelnen Box). Aus diesem Grund versucht PagerDuty , alle Systeme durch das Überwachungssystem zu leiten, anstatt Daten direkt von den Servern oder Diensten in PagerDuty einzuspeisen.
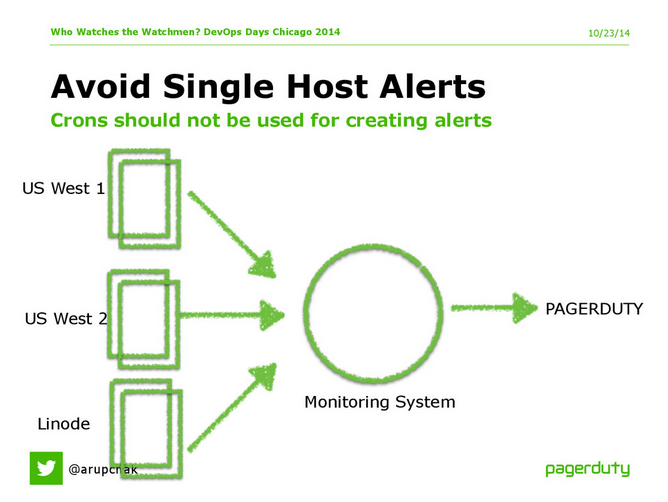
Wir leiten Server- und Servicewarnungen durch ein hochverfügbares Überwachungssystem, sodass wir über die Gesamtauswirkungen und nicht über Probleme einzelner Boxen informieren.
Chakrabarti erörtert auch die Überwachung von Abhängigkeiten oder die Überwachung der Leistung von SaaS-Systemen, die man nicht kontrolliert. Für dieses Problem gibt es noch keine allgemeingültige Lösung. Wir kombinieren manuelle Prüfungen und automatisierte Pings. Als Beispiel erzählt er die Geschichte eines Anrufs von einem Kunden, der seine SMS nicht erhielt. Nachforschungen ergaben, dass unser SMS-Anbieter die Nachrichten zwar verschickte, der Mobilfunkanbieter sie aber aus irgendeinem Grund blockierte. Daraufhin entwickelten wir ein Test-Framework, „auch bekannt als: Wie man unbegrenzte Messaging-Tarife missbraucht“. Jede Minute senden wir eine SMS-Benachrichtigung an alle großen Anbieter und messen die Antwortzeiten.

Wir senden jede Minute SMS-Nachrichten an die großen Mobilfunkanbieter und messen die Antwortzeiten, um sicherzustellen, dass wir wissen, ob bei den Anbietern Probleme auftreten, die die Zustellbarkeit unserer SMS-Benachrichtigungen beeinträchtigen könnten.
Benachrichtigungen zu den Themen, die Kunden wichtig sind
Viele machen den Fehler, bei jedem Fehler im Protokoll eine Warnung auszugeben, sagt Chakrabarti. „Wenn der Kunde es nicht bemerkt, ist vielleicht auch keine Warnung nötig.“ Er warnt jedoch, dass das Wort „Kunde“ innerhalb derselben Organisation verschiedene Bedeutungen haben kann. „Wenn Sie an Endbenutzer-Dingen arbeiten, sollten Sie die Latenz überwachen. Wenn Sie sich mehr um interne Abläufe kümmern, sollten Sie sich um die CPU in Ihrem Cassandra-Cluster kümmern, weil Sie wissen, dass dies Ihre anderen Entwicklungsteams beeinflusst.“ Wir haben eine großartige Blogbeitrag darüber, worauf Sie aufmerksam gemacht werden sollen, wenn Sie mehr erfahren möchten.
Überprüfen Sie, ob die Warnungen funktionieren
Das vielleicht beste Beispiel für die Überwachung der Beobachter ist die Tatsache, dass man „hin und wieder manuell prüfen muss, ob die Alarme noch funktionieren“, sagt Chakrabarti. „Wir haben bei PagerDuty etwas, das wir Misserfolg am Freitag , während wir im Grunde unsere eigenen Dienste angreifen.“ Das Team lässt alle Warnungen aktiv und fährt mit der Unterbrechung von Prozessen, dem Netzwerk und den Rechenzentren fort, um die Warnungen zu bestätigen.
Was hat das Team aus Failure Friday gelernt? „Die Prozessüberwachung war mit der Prozessausführung verknüpft“, erklärt Chakrabarti. „Wenn der Dienst ausfällt, fällt auch die Überwachung des Dienstes aus, und man erfährt davon erst, wenn er auf jeder einzelnen Maschine ausfällt.“ Und das ist, kurz gesagt, der Grund für die externe Überwachung.
Das könnte Ihnen auch gefallen ...

