
- PagerDuty /
- Der Blog /
- Best Practices und Einblicke /
- Service-Monitoring und Sie
Der Blog
Service-Monitoring und Sie
von Lilia Gutnik
24. Oktober 2019 | 7 Minuten Lesezeit
Der Autor möchte darauf hinweisen, dass dieser Blog definitiv nicht mehrfach durch die Mitwirkenden Dave Bresci und Arup Chakrabarti verzögert wurde.
Überwachung ist eine Kunstform. Das klingt kitschig und faul, aber die richtige Art der Überwachung ist stark kontextabhängig und funktioniert selten bei mehreren Softwareprogrammen oder Personen.
Dies wird noch schwieriger, wenn man an moderne Softwarearchitekturen denkt. Microservices? Container-Scheduler? Autoscaling-Gruppen? Serverlos? ${Neue Technologie, die alle meine Probleme lösen wird, aber wahrscheinlich andere Probleme schafft}?
Darüber hinaus hängt die Definition eines „Dienstes“ davon ab, mit wem Sie sprechen.
Für einen Softwareentwickler ist ein Dienst ein isolierter Funktionsblock, der auf den zuvor genannten Technologien basiert. Für einen Kunden ist ein Dienst ein Produkt, für das er bezahlt. Für einen CEO ist ein Dienst etwas, das ausfällt, damit er seinen SVP of Engineering anschreien kann.
In diesem Beitrag erläutern wir, wie wir, PagerDuty, unsere Dienste in unserer eigenen PagerDuty-Instanz einrichten und überwachen. Sie erhalten einige Tipps, wie Sie die vollständige Serviceverantwortung übernehmen, ohne (viel) Schlaf zu verlieren, und wie Sie Ihre Kunden und Geschäftspartner zufriedenstellen.
Ermitteln Sie den Dienst und die Komponenten
Ein Dienst besteht typischerweise aus mehreren Komponenten. Die meisten gut aufgestellten Teams verfügen über 5–10 Dienste in der Produktion, mit jeweils 3–5 Komponenten pro Dienst. Idealerweise gehört ein Dienst einem einzigen Team, das die volle Kontrolle über die Komponenten hat. Ist dies nicht der Fall, sollten die Komponenten als erstes mit der Aufteilung der Zuständigkeiten befasst werden.
Werfen wir einen Blick auf einen typischen dreistufigen Webdienst.
- Sie verfügen über Ihren Load Balancer für die Anforderungsweiterleitung
- Auf Ihren Anwendungsservern wird die Geschäftslogik ausgeführt (oft ist dies der einzige Teil, der als Teil des „Dienstes“ betrachtet wird).
- Ihre Datenbank dient der tatsächlichen Speicherung der Daten Ihrer Kunden.
In diesem Szenario haben wir drei Komponenten als Teil eines Dienstes.

Beginnen wir nun mit der Skalierung dieses Webdienstes. Sie werden wahrscheinlich eine Caching-Ebene hinzufügen, um Ihre Datenbank zu schonen, einige CDN-Knoten hinzufügen, um die Leistung zu steigern, und einen gehosteten Dienst nutzen, um selbst einige Aufgaben auszulagern.
Sie verfügen nun über einen einzigen Dienst, der aus sechs unterschiedlichen Komponenten besteht. Jede Komponente benötigt ein gewisses Maß an Telemetrie und Transparenz. Das bedeutet jedoch nicht, dass Sie jede Komponente überwachen und Warnmeldungen ausgeben müssen. Andernfalls konzentrieren Sie sich auf die Integrität der Komponenten, obwohl Sie sich stattdessen auf die Gesamtintegrität des Dienstes konzentrieren sollten.
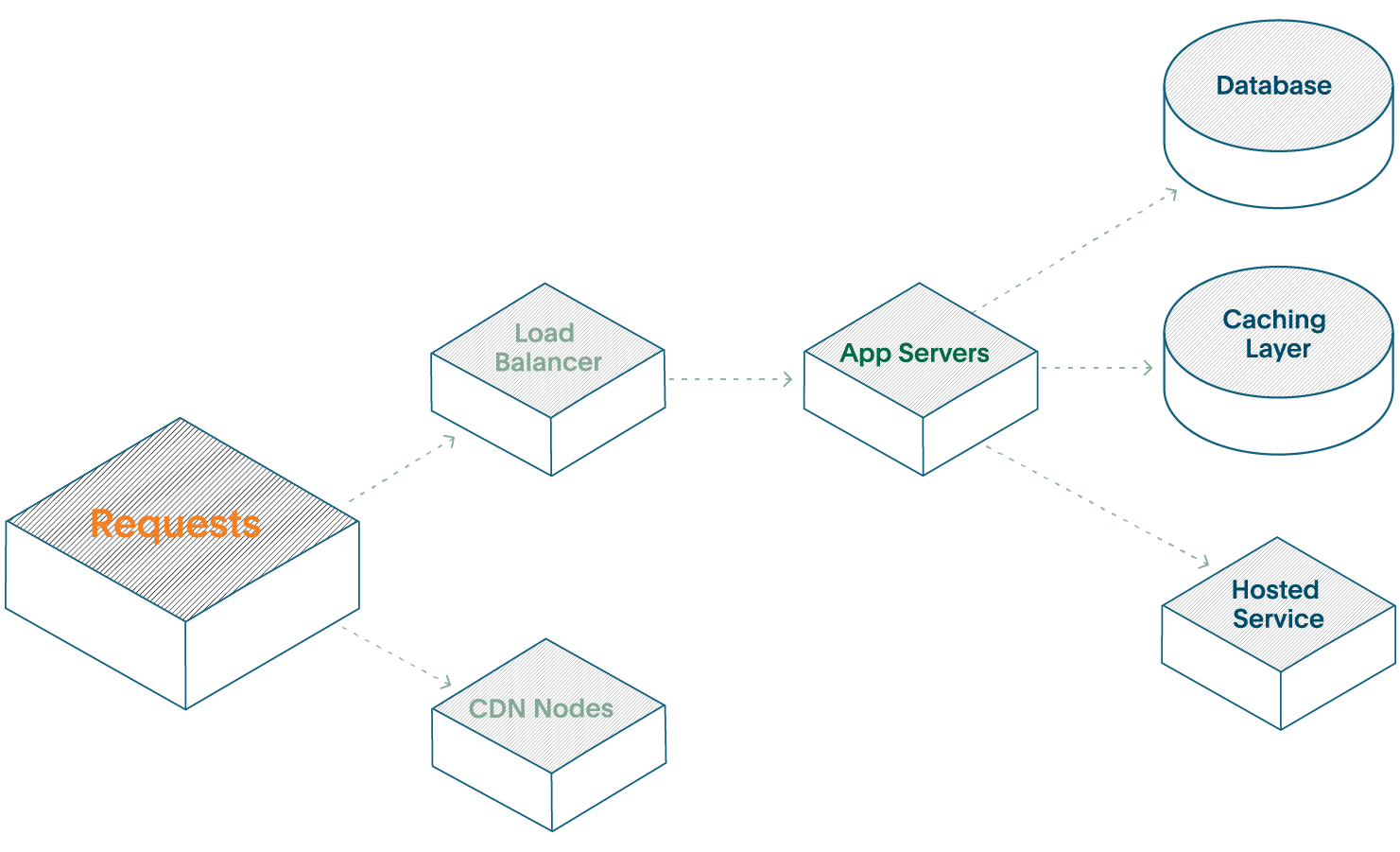
Es gibt verschiedene Möglichkeiten, sogar einen „einzelnen“ Dienst wie diesen zu modellieren. Manche Organisationen betrachten gemeinsame Infrastrukturebenen, wie etwa Netzwerkebenen oder Datenbanken, als einen separaten, von den kundenorientierten Diensten getrennten Dienst.
Fokus auf kundenrelevante Warnmeldungen
Konzentrieren Sie sich zunächst auf die einfachsten Warnmeldungen für die Verhaltensweisen, die Ihren Kunden wichtig sind. Denken Sie daran, dass Kunden sowohl interne Teams als auch externe Personen sein können, die für Ihr Produkt bezahlen. Dies beginnt in der Regel mit einfachen Ping-Monitoren (Ist es aktiv?) und entwickelt sich zu komplexeren Fragen (Ist es schnell genug?).
Das Schwierige daran ist, dass es sehr schwierig ist, jede einzelne Art und Weise vorherzusehen, wie Ihre Kunden Ihren Service nutzen werden. Daher ist es durchaus in Ordnung, einige Probleme zu spät zu erkennen und sich später damit zu befassen, wie Sie sie überwachen und zukünftige Probleme vermeiden können. Wenn Sie versuchen, jedes Problem vorherzusehen, erzeugen Sie am Ende Hunderte von Warnungen, die sich in ein Rauschen verwandeln. Denken Sie zunächst an allgemeine Kategorien wie Verfügbarkeit und Leistung und gehen Sie im Laufe der Iteration immer detaillierter vor.
Bei der Verfügbarkeit können Sie beispielsweise mit dem Prozentsatz der erfolgreich bearbeiteten HTTP-Anfragen beginnen und dann zu Fehleraufschlüsselungen, Aufschlüsselungen nach Komponenten usw. übergehen. Bei der Leistung können Sie mit der Gesamtladezeit der Seite beginnen und dann zu einzelnen Seitenkomponenten, Inhalten von Drittanbietern, mehrseitigen Transaktionen usw. übergehen. Bedenken Sie die Gefahren von Durchschnittswerten und nutzen Sie Perzentilen. Mehr dazu erfahren Sie hier: https://www.dynatrace.com/news/blog/why-averages-suck-and-percentiles-are-great/ und hier: https://medium.com/@djsmith42/how-to-metric-edafaf959fc7
Das Hinzufügen von Warnungen ist einfach, das Löschen ist schwierig
Verlassen Sie sich nicht auf alte Warnmeldungen. Was sinnvoll war, als Ihr Service zehn Kunden und drei Komponenten hatte, ist sinnlos, wenn Sie Tausende von Kunden und ein Dutzend Komponenten haben.
Wenn Sie eine der folgenden Fragen mit „Ja“ beantworten, ist dies ein Zeichen dafür, dass Sie eine Warnung entfernen sollten:
- Ignorieren die Leute diese Warnung?
- Schalten Sie diesen Alarm die meiste Zeit aus und warten Sie auf einen anderen Alarm, der relevanter oder wichtiger ist?
- Spiegelt der Wortlaut der Warnung eine alte Denkweise oder etwas wider, das nicht mehr existiert?
Wir haben über die Bedeutung von Betriebsprüfungen Ein wichtiger Aspekt dabei ist das Verständnis, welche Warnungen Sie entfernen können. Als allgemeine Regel gilt: Wenn eine Warnung in drei aufeinanderfolgenden Überprüfungszyklen keine Aktion hervorrief, entfernen Sie sie oder wandeln Sie sie in eine unterdrücktes Ereignis die Sie später ansehen können. Es kann sich herausstellen, dass Sie Optimieren Sie Ihre Servicekonfiguration in PagerDuty .
Das Definieren von SLIs, SLOs und SLAs ist wirklich schwierig
Nachfolgend finden Sie die Definitionen, die wir intern bei PagerDuty verwenden. Wenn Sie mit der Terminologie nicht vertraut sind, empfehlen wir Ihnen dringend, Folgendes zu lesen: Googles Bücher zum Thema.
Kurz gesagt, stellen Sie sich SLAs, SLOs und SLIs wie folgt vor.
SLA (Service Level Agreement). Was Sie Ihren Kunden als Versprechen geben. Jeder Dienst sollte genau ein SLA haben. Beispiel: 99,9 % Verfügbarkeit.
SLO (Service Level Objective). Ihr internes Ziel für Ihr SLA. Normalerweise handelt es sich dabei um eine konservativere Version Ihres SLA. Beispiel: 99,99 % Betriebszeit.
SLI (Service Level Indicator) . Objektive Fakten zum aktuellen Status Ihres Dienstes, die Ihnen bei der Beantwortung der Frage helfen, ob Sie Ihr SLO oder SLA erreichen. Beispielsweise der Prozentsatz der Anfragen, die in weniger als 300 ms eine HTTP 200-Antwort erhalten haben.
Wie bei den meisten Diensten, die Sie einführen, können Ihre SLAs, SLOs und SLIs beim ersten Versuch falsch sein – und das ist in Ordnung. Wichtiger ist, dass Sie etwas Definiertes haben, damit Sie es im Laufe der Zeit verfeinern können, wenn Sie mehr über Ihren Dienst und Ihr Unternehmen erfahren.
Eine gute Entwicklung könnte so aussehen:
- Prozentsatz der Anfragen, die nicht zu einer 5XX-Antwort geführt haben.
- Prozentsatz der Anfragen, die keine 5XX-Antwort erhielten und in weniger als 300 ms abgeschlossen wurden.
- Prozentsatz der Anfragen, die keine 5XX-Antwort erhielten und in weniger als 150 ms abgeschlossen wurden.
Bei PagerDuty haben wir Jahre gebraucht, um herauszufinden, wie wir die Interessen unserer Kunden präzise messen können. Was ihnen wichtig ist, hat sich im Laufe der Zeit dramatisch verändert. Unsere Definitionen unserer internen SLAs, SLOs und SLIs sind zwar nicht perfekt, aber wir haben etwas, das sich mit der Zeit verfeinern lässt, wenn unsere Teams mehr darüber lernen, was den Kunden wichtig ist. Weitere Informationen dazu, wie SLOs ein effektives Service-Monitoring fördern und Geschäftsentscheidungen beeinflussen können, finden Sie unter Liz Fong-Jones' QCon-Gespräch, Förderung hervorragender Produktion.
Es lohnt sich
All diese Arbeit ist nicht einfach und wird nie fertig oder perfekt sein. Aber es lohnt sich.
Ihr Team hat einen klareren Überblick über die Vorgänge und gerät nicht in Panik, wenn etwas schiefgeht. Es kann sich auf das Problem konzentrieren und erhält ein klares Zeichen, wann es fertig ist.
Mitarbeiter können nicht auf alles reagieren, als wäre es ein Notfall. Durch die Kenntnis und Veröffentlichung Ihrer SLAs wissen die Mitarbeiter, wann und wie sie mit einem Fehlerbudget arbeiten können. Durch die Optimierung Ihrer Warnmeldungen können sich die Mitarbeiter auf die wirklichen Probleme konzentrieren, anstatt sich von der Alarmflut abstumpfen zu lassen.
Und vor allem: Tun Sie dies, weil Ihnen Ihre Kunden am Herzen liegen. Wenn Sie das Monitoring Ihrer Dienste nicht optimieren und iterieren, geben Sie die Probleme direkt an sie weiter. Weitere Informationen zur Optimierung Ihrer Servicekonfigurationen in PagerDuty finden Sie hier: https://support.pagerduty.com/docs/best-practices-service-configuration
Teilen Sie uns Ihre Meinung zum Service-Monitoring mit. Wir würden gerne hören wie andere Menschen diesen Prozess durchlaufen.

