In a nutshell, ITIL event management is everything between an event and the human response. But first, let’s define what constitutes an event.
At its core, an event is simply a state of change to an IT service. The goal of ITIL event management is to detect and log these changes in order to gain full visibility into the IT service. For example, a user login, information about a recent deploy, or the completion of a server maintenance are changes that technical teams need to keep track of. While such changes don’t inherently imply service degradation, they can be indicative of simmering issues that may be customer-impacting. Thus, events must be collected, prioritized, and acted upon as necessary.
As infrastructure complexity has grown, so has the scale of events that IT operations teams must manage. But while the scale of events has grown exponentially, the number of people managing them has not. Many organizations now experience thousands or even millions of events taking place across their systems every day, and with limited bandwidth and resources, it’s nearly impossible to effectively prioritize and separate signals from the noise.
This is the key problem that ITIL event management solutions aim to solve. Solutions are oriented around integrating processes and tooling to detect and collect events, filtering out the noise, and orchestrating the appropriate action (usually done by forwarding events to an incident management or notification tool). As the stakes grow increasingly higher for IT service delivery, it’s more crucial than ever to integrate event management and incident management to ensure no time is lost between signal and action.
ITIL Event Management Definitions
To lay the foundation for the rest of this article, let’s establish a few definitions for typical objects within the operational data model: events, alerts, incidents, and notifications.
An event is simply a fact at a moment in time—it is neither good or bad. It consists of a single or group of correlated conditions that has been monitored and classified into an actionable state.
An alert, on the other hand, exists in a monitoring (or other) tool that tracks a monitor being in a failed state. In and of themselves, events and alerts (for example: disk at 60%) do not need to directly page out to responders because they aren’t inherently customer-impacting.
An incident is an issue that impacts the business or customers. An incident has one or multiple alerts and events associated with it. Using the previous example, several related alerts (disk 60%, disk 80%, disk full, etc.) should be grouped into an incident since that strongly indicates a degradation in service quality, which is customer-impacting. An event might not be an incident because it might not have any actual customer impact, but all incidents are events because events provide the raw context for what’s happening. The incident should act as the data hub for responder activity, remediation activities, and postmortems, and also should be what organizations report on.
Finally, a notification is a message—typically a phone call, push notification, text message, or email—to a user that informs them about an issue.
ITIL Event management is most effective when it is tightly integrated with incident response in a human-centered way. Teams shouldn’t have to manually scan a crowded email inbox or get bombarded with tens or hundreds of redundant phone calls in order to prioritize and diagnose problems. Bringing event management and incident management into a single platform ensures that data is actionable while providing centralized, truly holistic system and response context that accelerates triage.
Typical ITIL Event Management Stages
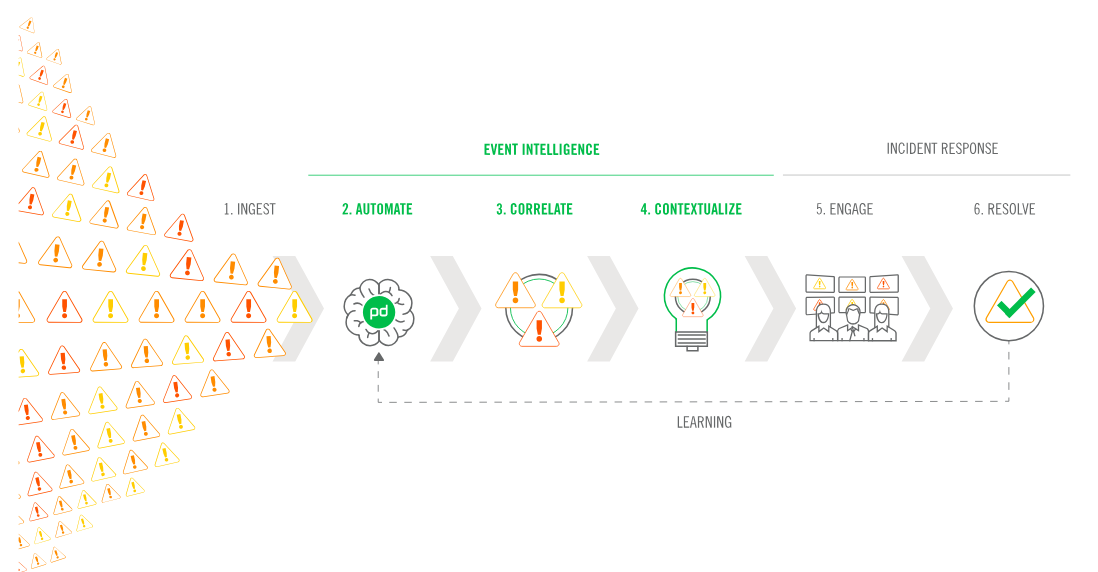
1. Monitoring Detection
An event notification gets generated and detected by a specific monitoring tool.
2. Event Filtering
The event notification is either recorded as a log file or communicated to an event or systems management solution.
3. Event Automation
With event automation, you can send all your events from various monitoring tools to a single endpoint and programmatically manage event behavior.
a) Routing
Determine which teams/services alerts are sent to, based on event payloads.
b) Deduplication
Using a system that easily and automatically deduplicates redundant alerts and incidents is crucial in mitigating unnecessary responder noise.
c)Suppression
Non-actionable events (such as informational messages) should not notify responders, but should still be retained for forensic analysis.
d)Enrichment
Notes, runbooks, links, and/or other details should be automatically appended to incidents to help responders resolve faster.
e) Correlation
Adaptive machine learning and rules-based approaches should be harnessed to group related events and alerts into actionable incidents with all the right context. This is also crucial to reduce responder noise as well as streamline the resolution process.
4. Response
Once the incident is in a format that makes it as easy as possible for people to take action with the right context, responders should be engaged. Ideally, organizations can define how they want issues to dynamically notify and/or escalate based on severity. Even better, they should be empowered to predefine the desired response actions (such as cross-functional responder mobilization, notifications to executives and other stakeholders, etc.) for different types of incident scenarios in peacetime. This way, they can easily and automatically execute them during wartime.
5. Resolution
Once the event or incident is resolved and closed, it and all subsequent actions should be recorded in the central event management or system management solution to ensure accurate reporting. Metrics such as reduction in noise, reduction in incidents and notifications, and reduction in mean time to identify and resolve issues should be tracked in order to understand how your ITIL event management processes are improving.
Why ITIL Event Management Matters
It’s no longer humanly possible to manually eyeball and parse through every event that takes place across your systems or program rules for every possible event scenario under the sun. At the same time, the stakes around taking the right actions on events (and in real time, no less!) are higher than ever before. That’s why automation in the form of event management is absolutely essential in managing event behavior at scale.
ITIL Event management helps organizations define what it looks like to detect and catalyze the exact right response to any event that has an impact on service management and performance. For instance, in PagerDuty, alerts can be generated with a severity field (either directly provided from the triggering monitoring tool or defined using PagerDuty event rules). Based on the payloads as defined below, the incident generated from the alert will dynamically select the right notification behavior.
| Alert Severity | Description | Default Incident Urgency |
| Critical | A failure in the system’s primary application. | High |
| Error | Any error that is fatal to the operation, but not the service or application. | High |
| Warning | May indicate that an error will occur if action is not taken. | Low |
| Info | Normal operational messages that require no action. | Low (if appended to an incident or suppressed) |
Best Practice ITIL Event Management
To stay afloat as complexity rapidly grows, teams must automate repetitive manual tasks to focus their time on higher-leverage activities. Rules should be easy to author, handle many different event types, and allow customizable enrichment, deduplication, alert suppression, and notification to manage complex enterprise needs.
Focus on where the configuration lives as you implement automation. When you have a centralized operations team trying to program a specific rule for every possible event scenario (or at least the ones they can think of), it creates a heavyweight system with a lot of siloing. In this case, operations analysts configuring the system have no idea what’s actually happening at the responder or application level, and the responders are missing key information when they get notified about issues. You need a solution that reduces configuration overhead and empowers both central and distributed teams to easily work from the same system without tripping each other up, in addition to having full context when issues arise.
How to Get the Most Out of ITIL Event Management
Traditional approaches to event management cut noise effectively but are often incredibly costly and time-consuming to set up and maintain, don’t integrate relevant human context and past remediation information with system data, and also don’t cope well with constantly changing infrastructure.
PagerDuty AIOps is the only solution for event management and automation that integrates your systems data with human response patterns, providing the fastest path from signal to action. Try it out now for yourself with a 14-day free trial. Or, take a tour to see it in action.