Things break. It’s a fact of life and of building and maintaining technology systems. And when things do break, organizations need an incident response process for development teams that helps get services back online faster, mitigates customer impact, and promotes learning. An incident response process (or incident response plan) walks through each step of an incident and describes who does what.
5 steps in an incident response process
Individual organizations will tailor their incident response process to their unique IT needs. Yet they’re likely to complete these 5 steps at some point in every incident. Let’s take a look at each.
1. Detect
The first step is detection. You’ve got a problem. Maybe you found out through your monitoring, observability, or alerting tool. Maybe another team has pinged you to let you know they’re experiencing a problem with your service. Or maybe customers have been filing tickets with customer support who then tells you. Whatever the case, you know there’s an issue and you begin to figure out how big of a deal this is.
2. Mobilize
This next step is where a responder begins to assemble a team. For a lower priority incident, sometimes a secondary on-call responder suffices. For higher priority incidents, you may need to escalate. This could mean adding an incident commander, communications team, and more subject matter experts. We’ll cover more on what each role does later. Each team member will then begin to complete their role-specific tasks.
3. Diagnose
During diagnosis, subject matter experts delve into the who, what, where, and why of the incident. This might involve adding other teams to the incident to help consult. Common teams brought in at this point include networking or security. By the end of this stage, the team will have at least one if not several possible paths towards resolution. This is usually the longest stage of the incident response process.
4. Resolve
Here, the team applies the hypotheses developed during the investigation phase. One or more hypotheses will result in the affected service returning to normal. The incident is usually considered “over” when customer impact ends.
5. Learn
It’s important to ensure that whatever caused a major incident doesn’t happen again. Learnings from an incident can show opportunities in both the technology and processes. Sometimes this means learning that there’s some legacy code in dire need of refactoring. Sometimes this can also mean discovering that a key runbook needs updating. This is the chance to address those challenges and improve.
Key roles in an incident response team
For smaller incidents, a single on-call responder can complete all five of the above steps. For more complicated incidents, it can become overwhelming for a single person to do it all. This is especially true if the incident crosses teams or requires company-wide communication. That’s why it’s important to dictate roles during major incidents. This helps share the load and ensures that nothing falls through the cracks.
Traditional DevOps incident response roles fit into three categories. First are command roles, which include the incident commander, the deputy, and the scribe. These are the people who are overseeing the entire incident and to whom everyone will report. Next are the liaison roles including an internal liaison and a customer liaison. The people in these roles keep everyone in the loop and ensure that communication flows between key stakeholders and the response team. Last but not least are the operations roles, also known as subject matter experts.
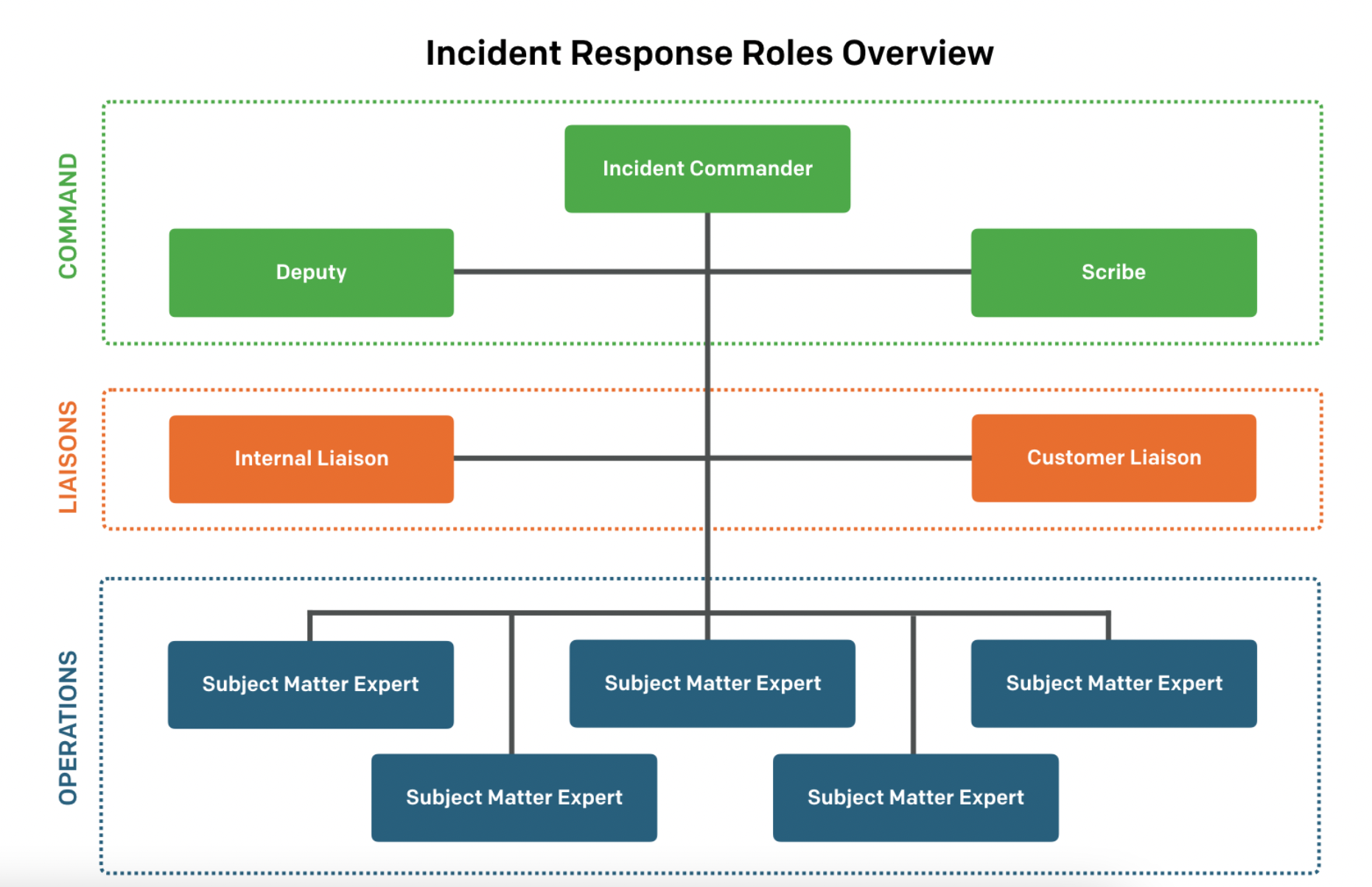
Let’s break down what these roles are actually responsible for during a major incident.
Incident commander
The incident commander oversees the entire incident from the moment the on-call responder loops them in until the postmortem is complete. This role ensures that the incident results in as little customer impact as possible. When there are any key decisions to make, this is the person who makes them. Note that this person isn’t the resolver in major incidents. They’re not the one looking through alerts or sifting through change events. Instead, they’re supervising the process to make sure that everyone is on track.
Deputy
The deputy reports to the incident commander and is their immediate support person. They are in charge of any tasks that the commander delegates to them. They also ensure other responders are giving timely updates to the incident commander. What’s considered timely depends on the organization. A common interval is every 15-30 minutes. The deputy keeps the commander focused on the task at hand and picks up any loose ends that need attending to.
Scribe
While the incident commander and the deputy are overseeing the incident, someone else needs to be responsible for documenting. Documentation ensures that the same path during incident response isn’t traversed twice. It also serves as the foundation of the postmortem or retrospective. It’s crucial to understand the order of events to finetune the incident response process. The scribe is the person recording all major events during the incident. This can involve taking notes, capturing recordings or screenshots, and crafting a rudimentary timeline. Depending on the incident severity, sometimes the deputy subsumes these duties.
Internal liaison
An internal liaison communicates incident progress to key stakeholders. Executives want to know about high-severity incidents. Sales may need to hold off on demos. Customer service might need to expect an influx of customer tickets. Legal may need to understand any impending SLA breaches. The command roles are often too to craft communications for these people. And communications become muddled when many incident participants send updates to the company. An internal liaison works with the incident response team to share necessary information. This streamlines communication and avoids confusion among stakeholders.
Customer liaison
Customers want to know why a tool or service they use isn’t working. Communicating and proactively with customers preserves trust. This also helps prevent churn associated with major incidents. But you can’t give too much or too little information in your customer communications. A customer liaison’s job is to craft meaningful communications with their users. These communications should reassure customers that the organization is looking into the issue. They should also set the stage for how customers can expect updates moving forward. If an organization promises hourly updates, that’s what a customer liaison should provide.
Subject matter expert
Subject matter experts are responsible for actually resolving the incident. These people are often on-call engineers for the service or services impacted. They’re close to the code and best know what to look for. They take direction from the incident commander and report to them or the deputy. Major incidents often have many subject matter experts working towards a resolution simultaneously.
Every role is crucial to the success of the incident response team. Teams working together can resolve incidents faster. Leadership makes the response seamless and provides structure. Thorough documentation provides a better starting point for post-incident learnings. Designated communication leads ensure that customers and stakeholders are more satisfied. And subject matter experts learn from each failure, getting better with every incident.
How PagerDuty enhances the incident response process
PagerDuty helps teams orchestrate the right response for every incident. With PagerDuty, organizations can protect revenue and improve customer experiences by resolving critical incidents faster and preventing future occurrences. Try PagerDuty for free for 14 days.