
- PagerDuty /
- Blog /
- Automation /
- Automated Diagnostics & Triage: The Fastest Way to Cut Incident Time
Blog
Automated Diagnostics & Triage: The Fastest Way to Cut Incident Time
by Madeline Zemer
August 14, 2025
| 7 min read
Too many incidents waste valuable engineering time on the basics: collecting logs, pulling system data, and tracking down the right person to fix the issue. Meanwhile, customers experience delays, SLAs are breached, and critical work gets pushed aside. The real kicker? Those L3 and L4 severity incidents that could actually prevent future fires get labeled as “nice to have” and collect dust in your backlog.
Automated diagnostics and triage eliminates these bottlenecks. PagerDuty Automation delivers the right data at the right time, reducing noise, accelerating triage, and driving faster resolutions without the manual overhead.
The real cost of slow triage
Incident cost isn’t just about downtime, it’s about people hours. PagerDuty data shows that up to 50% of incident time is spent diagnosing the problem and determining who should resolve it.
Manual triage delays innovation, reduces responsiveness, and increases the risk of burnout. Automating diagnostics compresses this window by providing enriched context and probable cause insights instantly, helping teams move from detection to resolution faster. =
Beyond raw incident duration, the human cost of triage is often overlooked. Every incident that demands involvement from multiple responders—whether for root cause analysis, troubleshooting, or even just validating an alert—pulls engineers away from planned work. This leads to cascading delays on key initiatives, after-hours work, and long-term team burnout. PagerDuty’s escalation policies and service ownership models ensure that incidents are routed to the right teams, reducing noise and unnecessary handoffs. And automation further minimizes these people costs by limiting escalations and reducing repetitive, low-value tasks.
How automated diagnostics and triage work
PagerDuty Automation reduces operational overhead and cognitive load by automating diagnostics at every stage of incident response:
Before paging:
Customers using PagerDuty AIOps can run proactive diagnostics and enrich alerts before responders are engaged. This includes collecting logs, performance metrics, and system health data to validate the issue and surface probable causes.
This reduces alert noise by ensuring that only actionable incidents reach human responders. Diagnostic data extends beyond typical monitoring alerts, providing responders with process-level context (e.g., top CPU-consuming processes, failing services, database connection errors) rather than just high-level anomaly signals.
During incidents:
Human-triggered diagnostics–through one-click runbooks–let first responders run targeted investigations without waiting on specialists. This eliminates the need to manually query systems, pull logs, or access tribal knowledge. Diagnostics automatically gather:
- Logs and memory usage
- Network performance data
- Cloud resource status
- Key service health checks
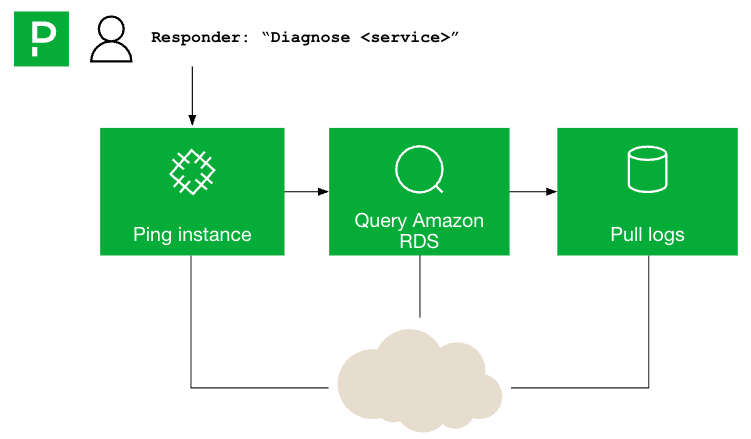
Responders can now perform comprehensive diagnostic evaluations with a single click
By surfacing probable causes early, teams can resolve incidents faster and reduce escalations to scarce experts. PagerDuty customers leverage automated runbooks that can be triggered as part of a coordinated response, ensuring that diagnostics, notifications, and stakeholder updates all happen seamlessly and automatically.
Smarter triage, fewer escalations:
Automated diagnostics reduce Mean Time to Triage (MTTI)—the often-overlooked contributor to overall MTTR—by removing the manual data collection and investigation steps that traditionally consume 50% of responder time.
This also helps distribute subject matter expertise across teams by embedding expert knowledge in runbooks, accelerating onboarding for junior engineers and minimizing reliance on niche specialists during high-pressure moments. Standardizing and automating these best practices means every responder benefits from built-in expertise and consistent processes.
What do we mean by diagnostic data?
Diagnostic data refers to the on-demand, system-specific information responders use to validate and triage incidents—beyond what traditional monitoring tools provide. For example, where monitoring alerts teams to a CPU spike, diagnostic data identifies which processes are consuming the most resources. Where uptime monitoring shows a service outage, diagnostics pinpoint the failing component, network path, or downstream dependency.
Automating the retrieval of this data reduces manual querying, shortens MTTI, and ensures responders engage with clear, actionable insights.
Beyond MTTR: Why mean time to triage matters
While organizations often track mean time to resolve (MTTR), the most significant delays typically occur earlier in the lifecycle. Across thousands of incidents, mean time to triage (MTTI) consistently emerges as a hidden bottleneck.
By automating diagnostics, organizations significantly reduce MTTI, shortening incident duration, reducing costs, and improving team efficiency. Faster triage means less time spent investigating and more time resolving.
MTTR has long been a standard for incident performance, but it only tells part of the story. Mean Time to Triage (MTTI) and Mean Time to Triage Transfer (MTTT) can also be hidden sources of delay. These metrics capture the time between detection and effective investigation—where manual diagnostics and team coordination consume the most cycles.
PagerDuty Automation targets this stage directly: reducing MTTI by providing instant, enriched diagnostic data, and minimizing MTTT by ensuring responders know who should resolve the incident without lengthy escalation chains. With automated service ownership mapping and dynamic responder assignment, the right people are always engaged at the right time.
For organizations looking to take automation even further, PagerDuty’s incident workflows feature allows the orchestration of complex, multi-step responses—automating not just diagnostics, but also communications, escalations, and stakeholder updates. This ensures a consistent, reliable response to every incident, especially at scale.
Customer outcome: From 40 minutes to 2
At ResultsCX, network failovers previously required 40 minutes to resolve–including 30 minutes to identify and engage the right specialist.
With PagerDuty, automated diagnostics and triage reduced this time to 2 minutes, improving uptime, exceeding SLAs, and reducing stress on engineers by minimizing after-hours escalations.

Common diagnostics in Action
Through PagerDuty’s ecosystem of 700+ integrations, customers automate diagnostics across multiple layers of the stack. Some examples include:
- General diagnostics: Collect logs, memory, disk space, and run system health checks
- Network diagnostics: Capture network performance, routine status, and bandwidth utilization
- Cloud provider diagnostics: Monitor cloud infrastructure metrics, service health, and resource allocations
- Health checks: Verify the status of complex system components to isolate root causes faster
- Pre-triage enrichment: Add diagnostic data and probable cause context to alerts before responders are engaged
Find other automated diagnostic examples and best practices here.
Why it matters
- Faster response: Teams respond with immediate context, not guesswork
- Less stress: Standardized runbooks eliminate repetitive tasks
- Better decisions: Enriched data enables faster, more accurate resolution paths
- Lower costs: Reduce responder involvement and manual investigation
- Consistent process: Automated diagnostics ensure repeatable, reliable triage workflows
- Reduced cognitive load: Free responders from manual data collection
- Fewer escalations: Minimize reliance on in demand specialists
- Shared knowledge: Make expert insights available to every responder
- Secure execution: Run diagnostics safely behind firewalls and in VPCs environments
- Faster onboarding: Help new engineers triage incidents confidently from day one
Automation that scales with your business
Automated diagnostics and triage aren’t just about faster incident response—they’re about enabling sustainable, scalable operations. By reducing escalations, shortening time to resolution, and easing the onboarding of new team members, organizations can see long-term gains in:
- Engineering velocity, by protecting time for innovation
- Team wellbeing, by limiting out-of-hours incidents
- Incident consistency, by eliminating guesswork and tribal knowledge bottlenecks
The payoff goes beyond fixing incidents faster. It’s a more stable, efficient, and sustainable way to operate.
Reclaim engineering time with automation
Every minute spent on manual triage is time taken away from high-value work. PagerDuty Automation reduces incident duration, improves operational consistency, and enables faster, more accurate responses without increasing the burden on your team. By embedding PagerDuty Automation and Incident Workflows into your incident response and on-call processes, PagerDuty empowers your teams to focus on what matters most: delivering value and innovation.

