In its simplest form, data aggregation is the process of compiling typically [large] amounts of information from a given database and organizing it into a more consumable and comprehensive medium. Data aggregation can be applied at any scale, from pivot tables to data lakes, in order to summarize information and make conclusions based on data-rich findings. Because of the growing accessibility to information and importance of personalization metrics across the enterprise, the application of data aggregation has become extremely relevant. The use case is industry-agnostic and is often critical to the success and continuous improvement of organizational operations across the world.
Why is Data Aggregation Important?
In our technologically advanced world, data is constantly evolving, expanding, and becoming more convoluted with each actioned input and output. Data is one of the most valuable currencies of our time, but data without organization, segmentation, and understanding is essentially useless.
What makes data valuable is the extraction of insights that point to key trends, results, and give a better understanding of the information at hand. A process in which data is searched, gathered, and presented in a summarized, report-based form, data aggregation helps organizations to achieve specific business objectives or conduct process/human analysis at almost any scale.
Examples of Data Aggregation
Data aggregation has been widely used throughout society for countless years; but with advances in computing and technology like AI and Machine Learning, the scale and capacity of data aggregation has grown exponentially.. Examples of data aggregation can be as simple as collecting the amount of steps you took this week on your commute to work, and as complex as using a ride-sharing app to hail a car to your exact location within minutes. While the second option may sound simpler from an end-user perspective, the amount of data that needs to be computed and aggregated in order to make that ride accessible for you is astounding. The importance of data aggregation will continue to grow as technology becomes more and more embedded into our lifestyles, both at home and in the workplace.
Data Aggregation in Action
In the perspective of PagerDuty, data aggregation plays an important role in the scheme of real-time operations across the digital enterprise. Just last year, PagerDuty ingested more than three billion disparate signals for customers of all use cases. While this number is staggering, the information delivered to customers after ingestion is comprised in a way that is much more actionable and easy to consume. This is large-scale data aggregation at work.
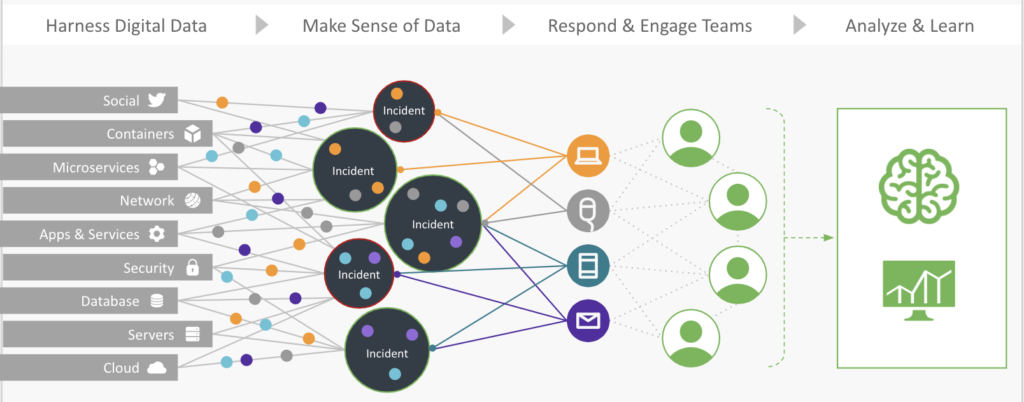
As you can see in the above photo of how the PagerDuty platform processes information from various applications, signals are ingested via the platform and aggregated via common variables and signal makeup. In this case, the platform is grouping signals that are interrelated within a given incidents’ makeup. They are then aggregated into subsets in order to make the abundance of signal information easier to understand. By doing this, PagerDuty users are able to derive actionable insights from the platform and make decisions based on the data correlations that make up the aggregate to take the right action at the right time.
PagerDuty’s data aggregation capabilities allow teams to bidirectionally integrate over 350+ integrations with the platform in order to analyze and deliver data from one, centralized view, giving customers full visibility into the overall health of their infrastructure. To learn more about how PagerDuty can help aggregate and reduce operational noise—and so much more—for your team, try PagerDuty today.