

- PagerDuty /
- Engineering Blog /
- PagerDuty + Arize: Building End-to-End Observability for AI Agents in Production
Engineering Blog
PagerDuty + Arize: Building End-to-End Observability for AI Agents in Production
by PagerDuty
August 13, 2025
| 12 min read
When PagerDuty was founded over 15 years ago, we had an ambitious mission: ensure that critical incidents never go unnoticed, and that teams can respond quickly to minimize downtime and impact on their customers.
In this article, we will discuss how we partnered with Arize to roll out the observability tooling which gives us visibility into our AI Agents, throughout their development lifecycle. We’ll also highlight some of our learnings from that process, key data points and metrics we’re actively monitoring, the interesting ways in which we’ve been able to couple PagerDuty and Arize, and how this exploration led us to once again expand the scope of what we consider to be an “incident.”
Over the course of our journey at PD, we’ve seen the needs of our customers evolve, the software landscape go through significant changes, and new types of infrastructure being envisioned, adopted and replaced. And throughout those transformations, our product continued to adapt and support these emerging technologies and use cases.
At the core of many of our internal “philosophical” discussions is the concept of an incident, which at a high level we define as:
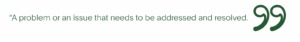 This definition is purposefully broad because our users need that flexibility and value having the ability to contextualize PagerDuty to their unique problems and response strategies. That said, many types of “problems” that result in an “incident” are shared pain points. No matter who you are, if a network outage takes down your public services, you are going to want that problem flagged and resolved as quickly as possible.
This definition is purposefully broad because our users need that flexibility and value having the ability to contextualize PagerDuty to their unique problems and response strategies. That said, many types of “problems” that result in an “incident” are shared pain points. No matter who you are, if a network outage takes down your public services, you are going to want that problem flagged and resolved as quickly as possible.
In the last two years or so (time is so hard to track nowadays), we entered another one of these major transformations: Artificial Intelligence. Virtually all of our customers are currently leveraging AI for tasks ranging from simple internal use cases like automating status updates and document reviews, to highly complex applications that support their main business products. We are no different. PagerDuty has been using AI to help reduce alert noise and accelerate incident resolution for years, and we’re also extremely proud of the Generative/Agentic AI capabilities we’ve been rolling out as part of PagerDuty Advance.
This new wave of modern AI capabilities is offering teams an incredible opportunity, but with all of that power comes great responsibility. When your server catches fire, the smoke is typically an obvious sign that you need to raise an incident. But how does that all work in the age of AI Agents, and how can you ensure you have the right mechanisms to detect and respond to the new (and sometimes very subtle) AI-specific problems that can negatively impact your customers?
“AI Incidents” Are Real Incidents
Just because an issue was caused by artificial intelligence doesn’t mean it doesn’t have real world impact. In fact, alongside the surge in AI applications, we’re also witnessing new real-world risks materialize with significant business impact. From chatbots hallucinating refund policies to ongoing copyright disputes, successful AI product rollouts must deliver tangible user benefits while maintaining safety, transparency, and observability.
With this imperative in mind, we developed our approach to releasing AI features at PagerDuty.
Monitoring and Keeping AI Agents Safe
Though our Agentic AI journey only started a few months ago, we’ve already rolled out several agents that are becoming core to our platform experience, and customers that signed up for early access have begun experiencing some of the “magic” delivered by our Insights, Shift and SRE Agents. However, as anyone who’s built with AI knows, the real challenge isn’t just launching these agents, it’s making sure they actually work, and keep working, in the real world.
“Golden dataset” testing
Let’s start with the Insights Agent—a chat-based assistant that helps users analyze their operations. It handles questions like “How many incidents did we have last month?”, “Have my teams improved their acknowledgement rate this year?”, “How are sleep hour interruptions trending this month?”, or “How does July’s MTTR compare to the first half of 2025?” Providing this level of visibility to an organization is extremely useful, but only if the agent’s answers are accurate! Validating that is something we quickly realized would be an interesting technical challenge as determining correctness in this context is a lot more nuanced than the equivalent task in traditional ML workflows.
We started by compiling a comprehensive list of questions with known answers and began manually testing the agent. However, these tests proved time-consuming, leading us to run them less frequently than ideal. And since we’re constantly improving our agents, with multiple teams often making simultaneous updates to our code base, ensuring these changes don’t introduce new issues or degrade performance becomes critical.
So we did what any good engineering team does and automated this testing framework. To accomplish that, we built a script that could be triggered on demand to fire off the “golden test questions” to the agent one at a time, collecting the agent’s output and using human provided “ground truth” to evaluate performance. For questions where the answer changes over time (e.g. “how many SEV-1 incidents did we have last week?”), the ground truth data collection process was also automated to be able to dynamically evaluate the agent’s responses. But we didn’t stop there – we added an LLM-as-a-judge to the pipeline, replacing human verification with automated evaluation. This allowed us to scale testing massively (by removing the “human in the loop”) and made it much easier for teams to assess whether new changes improved or degraded their agent’s performance.
At this point, it was clear we were onto something. Rather than reinventing the wheel for every new agent, we decided to standardize our approach. We built a general framework for AI agent testing leveraging both Arize tracing and the Arize experimentation features, simplifying how teams define their “golden questions”, the corresponding reference data, and how they could plug those into our automated evaluation pipeline.
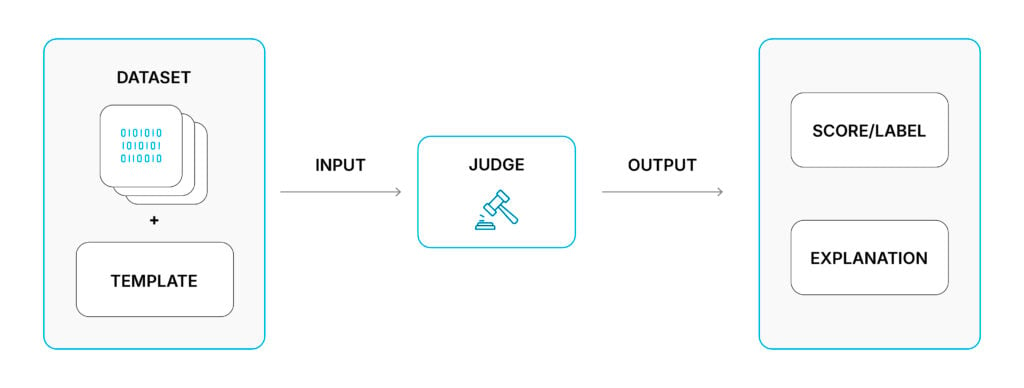
Agent output data and an evaluation template are provided to an LLM (Judge) which produces a label (e.g. “correct”/”incorrect”) and an explanation of why it produced that label.
Arize tracing is a core component of our agent observability toolkit. For our golden dataset testing, agent requests are traced in Arize, and we use trace-level evaluations to log LLM-as-a-judge evaluations for each interaction. By filtering on the evaluation results, we can easily identify problematic interactions that require attention.
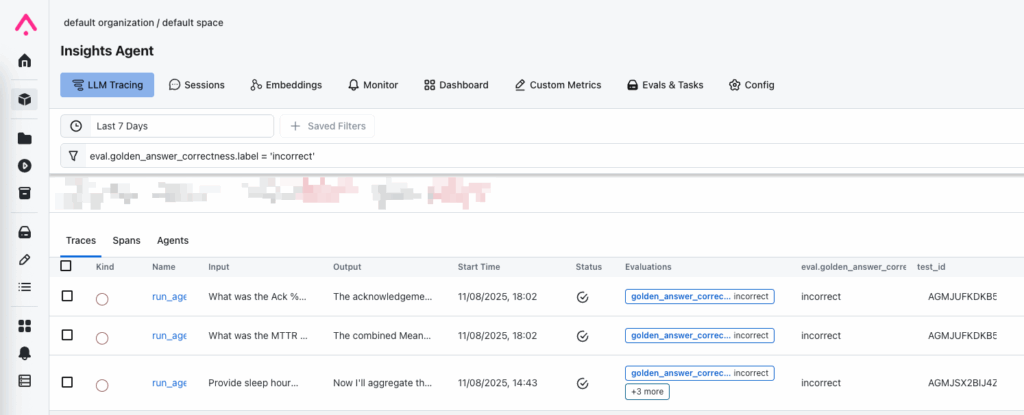
Arize spans filtering allows easily identifying inputs that require attention.
Our golden datasets are maintained as Arize datasets, which allows logging tests as experiments. This provides us a different view than the trace-level evaluations, where we can compare outputs on the same inputs across experiments. It also allows us to run golden dataset tests from a local or secondary branch without “polluting” the main trace feed with experimental tests.
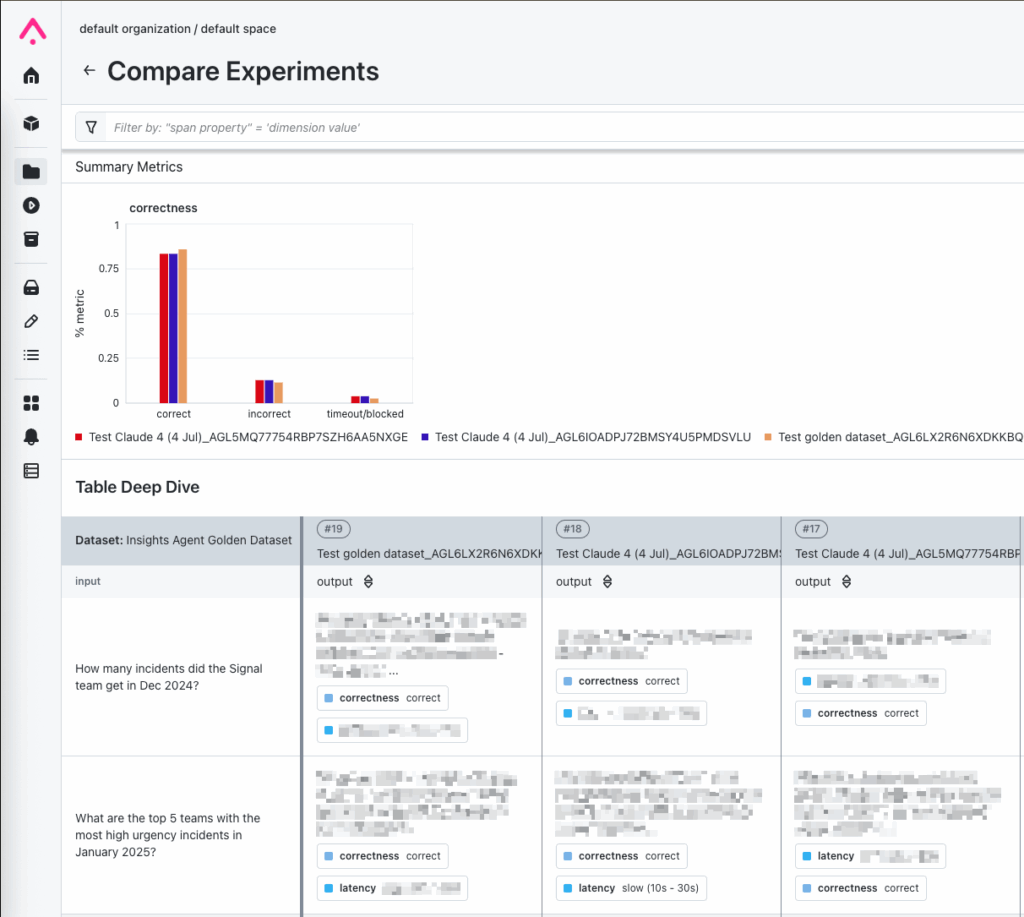
Arize experiments can be used to compare results of different runs side-by-side.
In software engineering terms, this was our version of “regression tests”, but for AI agents.
To ensure the agentic AI features we roll out to customers maintain a high performance standard across all critical user journeys, teams must now tie their development process to this framework and (1) specify test questions that broadly cover their agent’s functionality – i.e., the golden dataset, and (2) tag each question with expected answers. The framework handles the rest – calling the agent, running the LLM judge, and reporting results. This made it much easier for teams to keep track of these performance metrics while their members can focus on shipping new features and improvements instead.
Testing without ground-truth data
Moving beyond the above setup, we also needed to know how well our agents perform during real-world usage in production, and in particular when customers take new and unique journeys within our agent that we had not explicitly anticipated. Being able to do this effectively would help us improve the agent itself and our test coverage. But how do you evaluate an AI agent without ground-truth data? You can focus on other quality dimensions: groundedness, relevance, and tool selection.
Here’s how we break that down. Imagine the agent’s workflow as the flowchart below with three nodes: the user’s question, the tools the agent calls (and their outputs), and the agent’s final response. For the agent to perform well, all three need to make sense together. And to measure that, we evaluate the links between each pair of nodes.
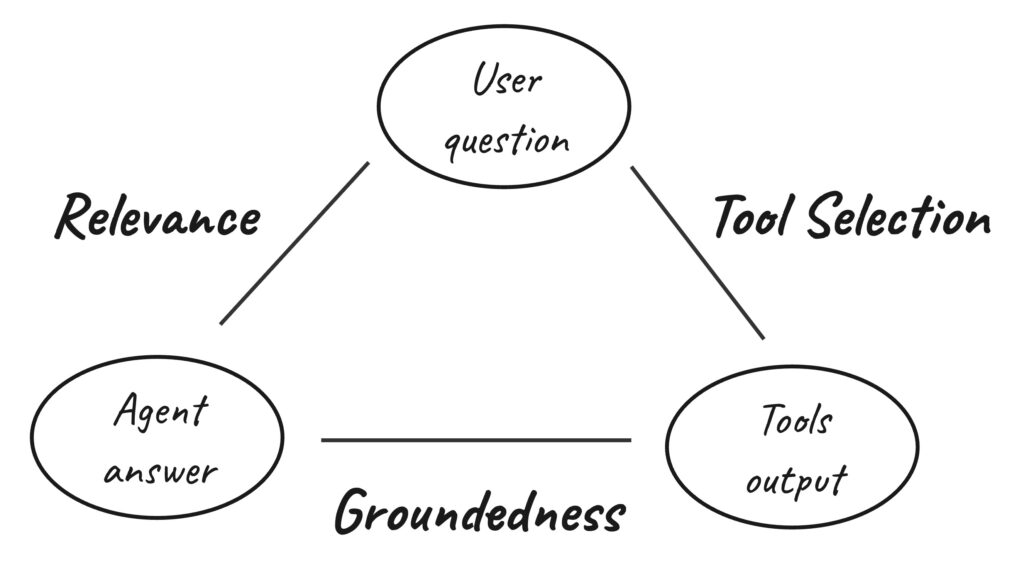
Evaluating agent answers and tool calling with relevance, groundedness and tool selection checks.
First we look at relevance (does the agent’s answer actually address the question?) Next, groundedness (is the answer based on the facts provided by the tools?). And finally, tool selection (did the agent call the right tools given the user’s request?) Together, these evaluations provide comprehensive insight into agent performance without requiring ground-truth answers
We implemented these evaluations for the Insights Agent using traces from Arize. For each trace, we extracted the user input, agent response, and tool calls (with their definitions), then, based on the Arize’s evaluator templates we constructed three specialized prompts, and created the LLM judges for relevance, groundedness and tool selection. This approach works for any real usage trace, not just pre-defined test cases. By measuring relevance, groundedness and tool selection on golden answers we are able to validate that these evaluations correlate strongly with ground-truth-based correctness evaluations.
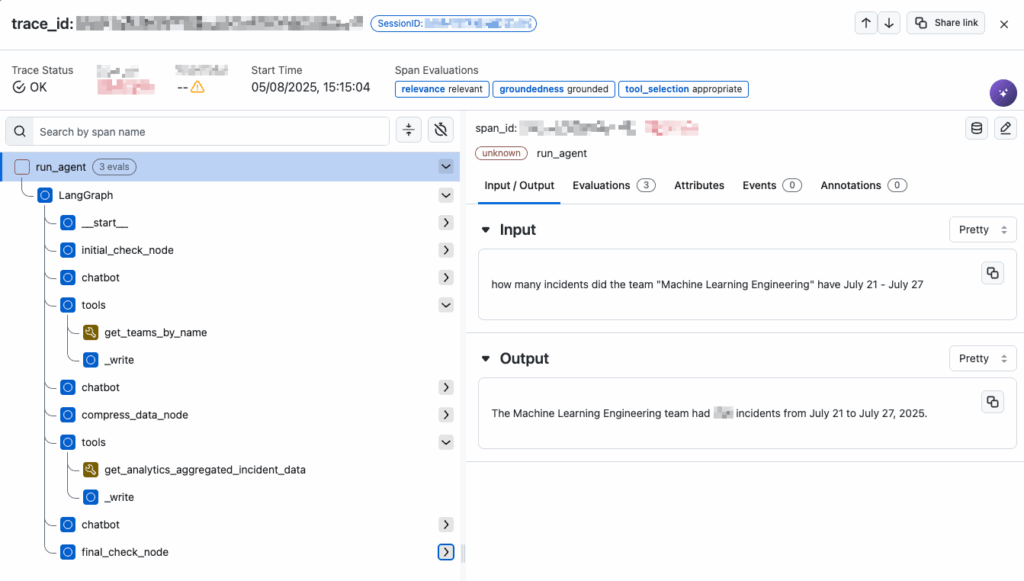
Arize tracing allows extracting the required data for evaluations in a standardized manner.
For agent requests that are traced, we create custom metrics that feed Arize dashboards, allowing different teams to monitor the same KPIs over time. These dashboards provide the required visibility not only to engineering teams but also to product managers reviewing how these quality and performance metrics change overtime.
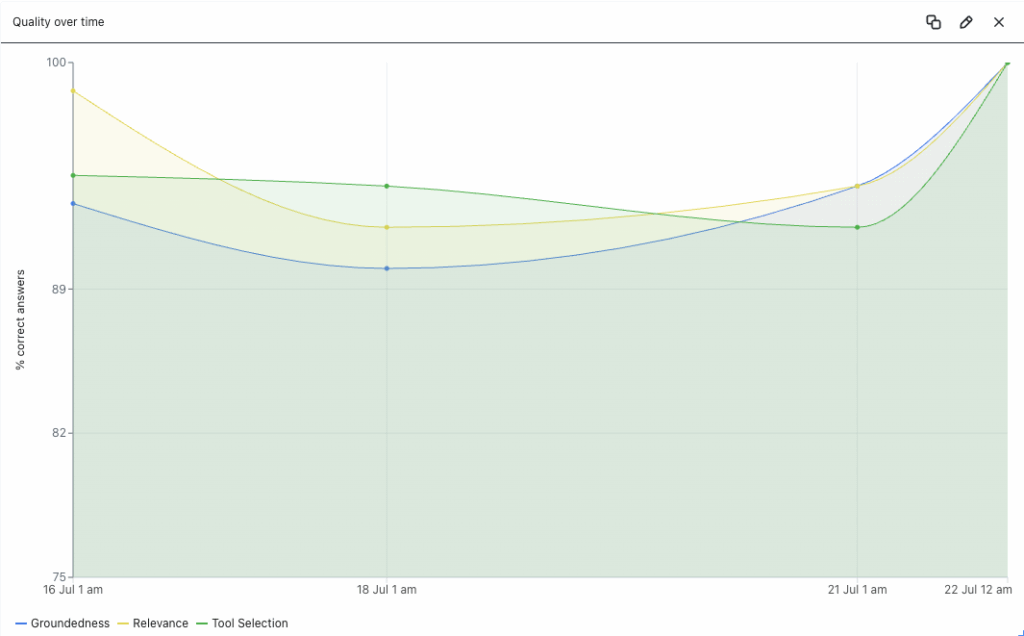
Arize dashboards are created from custom metrics that read trace evaluation data.
This was a game-changer. We could now evaluate agents not just with offline tests, but during their actual, real-world usage. And because we didn’t need ground-truth data, it was easy to extend the framework to other agents.
In practice, this meant we now had a flexible, scalable way to monitor and improve our AI agents, no matter how they’re used or what kind of data they handle. Teams still use golden tests where it makes sense, but they can also rely on relevance, groundedness, and tool selection evaluations for everything else.
With automated evaluations in place, we needed one final piece: an alert mechanism to notify us when agents go off track. And hey… that’s our expertise here at PagerDuty! Next, we’ll cover how the PagerDuty integration built into Arize helped us streamline this part of the process.
PagerDuty for AI agent operations management
It won’t surprise you to know that PagerDuty is the backbone of our operations management. We use it to centralize signals from different sources, provide event-based automation and to standardize incident management. Integrating agent evaluations and monitors into PagerDuty is crucial to close the operational loop for our agentic AI offerings. Using Arize monitors with custom metrics we are able to bring alerting into PagerDuty services when thresholds are breached.
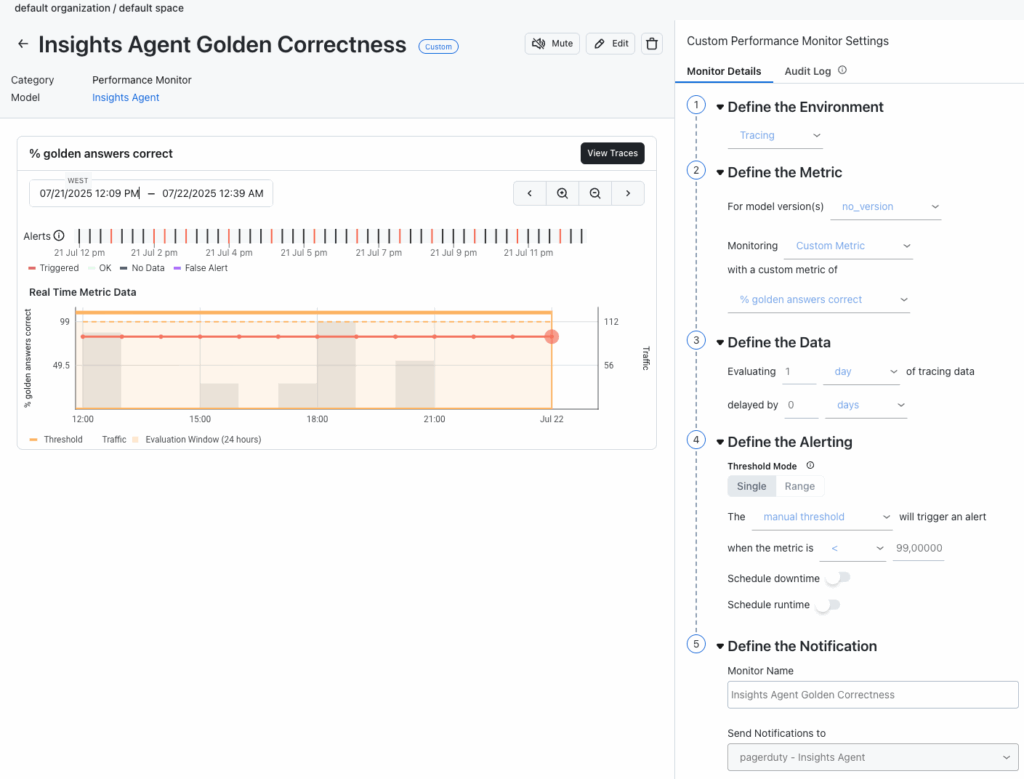
Arize monitors are configured based on custom metrics to send notifications to PagerDuty when a threshold is breached.
Once the alert creates an incident in PagerDuty, an incident workflow sets it to a custom incident type so it can be easily differentiated from other types of alerts and teams can apply tailored responses and log specific data accordingly.
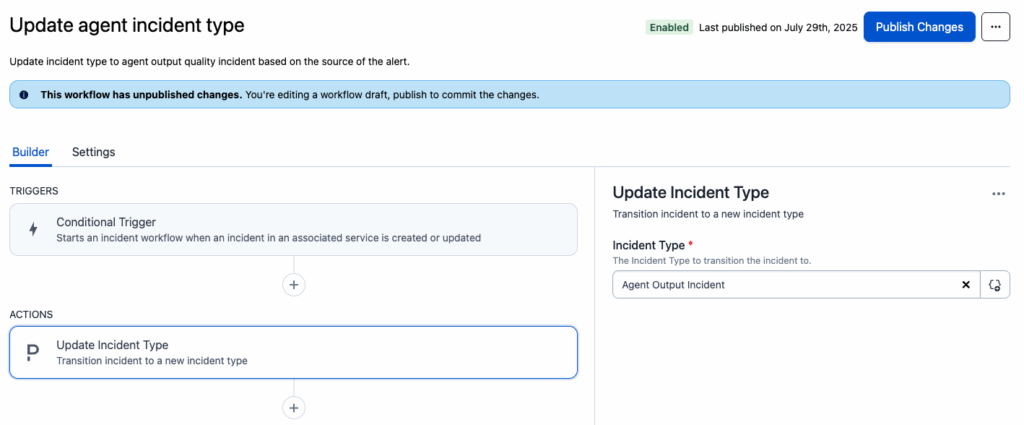
PagerDuty incident workflows are used to set an “Agent Output Incident” type for alerts coming from Arize monitors.
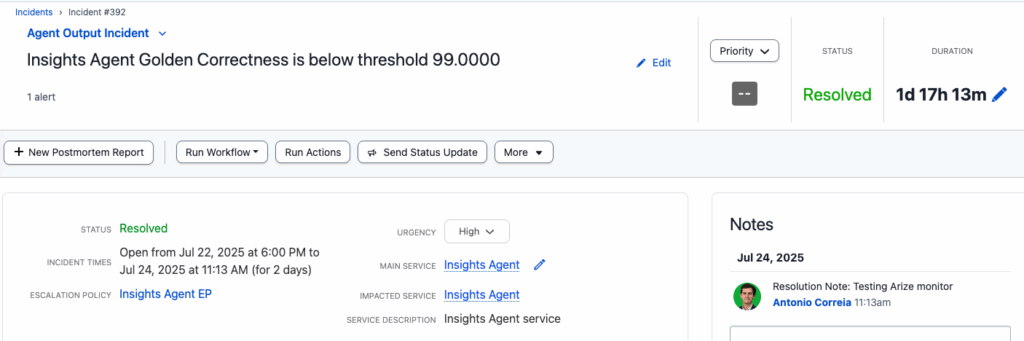
An “Agent Output Incident” is created when the Arize monitor threshold is breached.
When a threshold is breached for one of our output quality monitors, the on-call engineer on the agent team gets paged with a low-urgency notification, and another incident workflow creates a Jira ticket on the agent team’s board, thereby guaranteeing ownership and visibility into the issue. And as an extra layer of validation, we intend to extend this workflow to automatically trigger a run of our “offline” golden dataset test, which will help responders ensure they are not dealing with transient “false positives”.
Final Thoughts
Building reliable AI agents requires rethinking traditional monitoring approaches, and we’ve learned that the combination of automated evaluation, real-time observability, and incident response creates a powerful foundation for AI operations. By sharing our journey with PagerDuty and Arize, we hope to help other teams accelerate their own AI initiatives. The tools and frameworks we’ve developed aren’t just solving our immediate needs, they’re establishing patterns that will serve us as AI agents become even more sophisticated and business-critical. After all, in the age of AI agents, the question isn’t whether incidents will happen, but whether you’ll detect and resolve them before your customers do.
About the authors:

 Everaldo Aguiar is a Senior Engineering Manager, Applied AI at PagerDuty, where he leads the Data Science Core and Machine Learning Engineering teams. With a background in predictive analytics and AI, his work focuses on deploying machine learning and Generative AI to enhance automation, noise reduction, and operational efficiency. Everaldo holds a PhD in Computer Science from the University of Notre Dame, where he specialized in education data.
Everaldo Aguiar is a Senior Engineering Manager, Applied AI at PagerDuty, where he leads the Data Science Core and Machine Learning Engineering teams. With a background in predictive analytics and AI, his work focuses on deploying machine learning and Generative AI to enhance automation, noise reduction, and operational efficiency. Everaldo holds a PhD in Computer Science from the University of Notre Dame, where he specialized in education data.


