Reducing your Incident Resolution Time
by Julie Arsenault
November 12, 2014
| 4 min read
A little while back, we blogged on key performance metrics that top Operations teams track. Mean time to resolution (MTTR) was one of those metrics. It’s the time between failure & recovery from failure, and it’s directly linked to your uptime. MTTR is a great metric to track; however, it’s also important to avoid a myopic focus.
Putting MTTR into perspective
Your overall downtime is a function of the number of outages as well as the length of each. Dan Slimmon does a great job discussing these two factors and how you may want to think about prioritizing them. Depending on your situation, it may be more important to minimize noisy alerts that resolve quickly (meaning your MTTR may actually increase when you do this). But if you’ve identified MTTR as an area for improvement, here are some strategies that may help.
Working faster won’t solve the problem
It’d be nice if we could fix outages faster simply by working faster, but we all know this isn’t true. To make sustainable, measurable improvements to your MTTR, you need to do a deep investigation into what happens during an outage. True – there will always be variability in your resolution time due to the complexity of incidents. But taking a look at your processes is a good place to start – often the key to shaving minutes lies in how your people and systems work together.
Check out your RESPONSE time
The “MTTR” clock starts ticking as soon as an incident is triggered, and with adjustments to your notification processes, you may be able to achieve some quick wins.
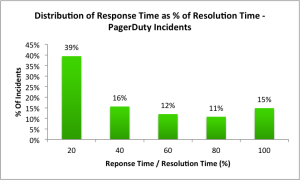
Curious to know how your response time stacks up? We looked at a month of PagerDuty data to understand acknowledgement (response) and resolution times, and how they are are related. The median ack time was 2.82 minutes, and 56% of incidents were acknowledged within 4 minutes. The median resolution time was 28 minutes. For 40% of incidents, the acknowledgement time is between 0-20% of the resolution time.
Median Response Time: 2.82 minutes
Median Resolution Time: 28 minutes
If your response time is on the longer side, you may want to look at how the team is getting alerted. Do alerts reliably reach the right person? If the first person notified does not respond, can the alerts automatically be escalated, and how much time do you really need to wait before moving on? Setting the right expectations and goals around response time can help ensure that all team members are responding to their alerts as quickly as possible.
Establish a process for outages
An outage is a stressful time, and it’s not when you want to be figuring out how you respond to incidents. Establish a process (even if it’s not perfect at first) so everyone knows what to do. Make sure you have the following elements in place:
- Establish a communication protocol – If the incident is something more than one person needs to work on, make sure everyone understands where they need to be. Conference calls or Google Hangouts are a good idea, or a single room in Hipchat.
- Establish a leader – this is the person who’ll be directing the work of the team in resolving the outage. They’ll be taking notes and giving orders. If the rest of the team disagrees, the leader can be voted out, but another leader should be established immediately.
- Take great notes – about everything that’s happening during the outage. These notes will be a helpful reference when you look back during the post mortem. At PagerDuty, some of our call leaders like using a paper notebook beside their laptop as a visual reminder that they should be recording everything.
- Practice makes perfect – if you’re not having frequent outages practice your incident response plan monthly to make sure the team is well-versed. Also, don’t forget to train new-hires on the process.
To learn more, check out Blake Gentry’s talk about incident management at Heroku.
Find and fix the problem
Finding out what’s actually going wrong is often the lion’s share of your resolution time. It’s critical to have instrumentation and analytics for each of your services, and make sure that information helps you identify what’s going wrong. For problems that are somewhat common and well understood, you may be able to implement automated fixes. We’ll dive into each of these areas in later posts.

