Surviving a Datacenter Outage
by Amanda Folson
January 20, 2015
| 3 min read
PagerDuty was built around one simple idea: waking up the right people when things break. When an event is triggered, PagerDuty makes magic to notify the right person or team that something is wrong.

However, ensuring that the message makes it out of our pipeline to you isn’t so simple. Because we’re providing notifications when your systems are down, there’s a pretty big constraint on us to be up. If you can’t trust us, who can you trust?
We rely on a few distributed technologies in our alerting pipeline because they offer us the redundancy we need to ensure alerts make it to users. We’ve spent a lot of time architecting our infrastructure to be as fault-tolerant as possible in order to provide durable and consistent read/write operations in our critical alerting pipeline.
This pipeline starts with an event endpoint — either HTTP or email. From there, each event from a customer’s monitoring tool goes through a pipeline of separate services (such as incident management and notification management services) and ultimately ends up at the messaging service that actually reaches out to people. Many of these services are built on Scala and supported by Cassandra on the back end for data storage. We also make use of other technologies such as Zookeeper for coordination. This pipeline must always be up and healthy so we can ensure notifications are reaching people.
Cassandra at PagerDuty
We’ve had Cassandra in production for about two and a half years. Unlike some companies that are using Cassandra to support their “big data” efforts, our data set is relatively small — in the order of 10s of GB at any given moment. Since we’re using it to usher events through our pipeline, once the event reaches the end the data about it can be purged from the pipeline. We aim to keep our dataset as slim as possible.

Cluster Configuration
We typically create clusters of 5 Cassandra nodes, with a replication factor of 5. These nodes are split across three datacenters; two nodes in one, two nodes in another, and one node in yet another facility. We make use of Cassandra’s quorum consistency level in order to provide us with the durability we need in the pipeline. This means that every write must be written to a majority of the cluster i.e. at least 3 of the 5 nodes.
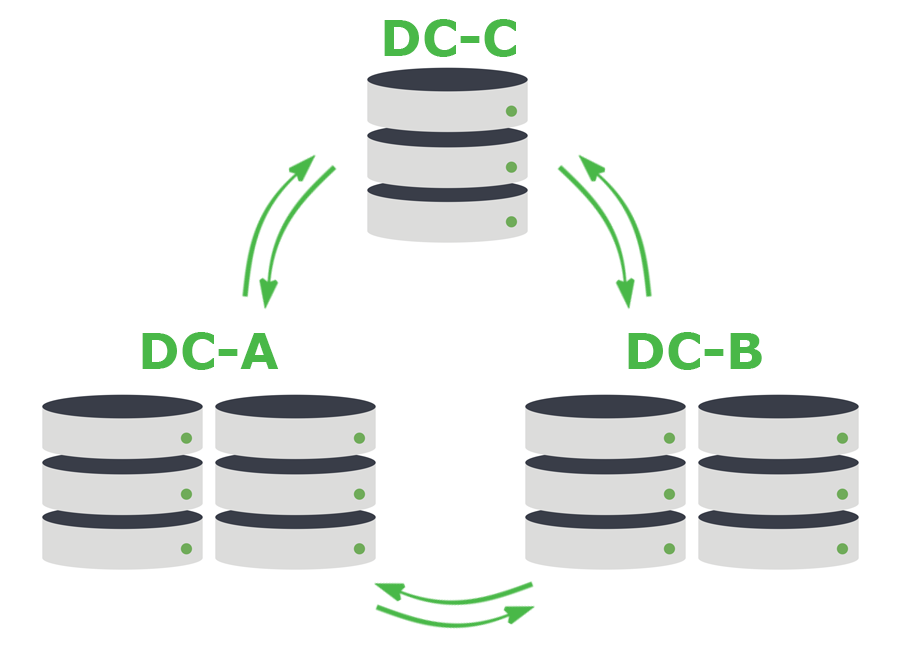
This pattern isn’t without its flaws. Every operation is across the WAN and takes an inter-DC latency hit. In some ways, this runs counter to typical recommendations for database clusters. However, since this latency hit is not exposed to humans, we’re willing to live with this tradeoff given the benefits: events aren’t lost, messages aren’t repeated, and we get durability and availability in the event that we lose an entire datacenter. With this 3 of 5 pattern, everything is written to at least two datacenters.
How do we know this works?
We intentionally introduce failures into our infrastructure to make sure that everything continues to run smoothly in the event of an outage. This includes thoroughly testing Cassandra nodes in degraded and non-functional states. For more about this, see our Failure Friday post.
At PagerDuty, we like to solve interesting technical problems. If you’re interested in making our cluster more robust, we’re currently hiring for positions in San Francisco and Toronto.

