
- PagerDuty /
- Engineering Blog /
- Production AI Agents: Closing the Gaps Between Idea and Reality
Engineering Blog
Production AI Agents: Closing the Gaps Between Idea and Reality
by João Freitas
June 11, 2026
| 16 min read
This article explores the complexities of transitioning AI agents from successful prototypes to reliable, production-ready systems in high-reliability environments like PagerDuty. It outlines key architectural challenges—such as non-determinism, context fatigue, and security vulnerabilities—and offers a framework for building robust, scalable agentic systems. Ultimately, it emphasizes the importance of investment in observability, evaluation pipelines, guardrails, and thoughtful UX design to bridge the gap between initial development and enterprise-grade performance.
Context
The advances in coding assistants allow anyone to build a working application. Going from an idea to a prototype today takes hours or minutes. However, making it reliable and production-ready requires additional work, especially in high-reliability environments. For AI agents, the same applies. You build an agent in minutes. It works on your machine. Demos go well. Then you ship it to production, and the AI agent fails, or the quality of the end-user experience falls short of expectations. This article addresses how to fix the gap between a working prototype and an AI agent ready for production.
Over the past year at PagerDuty, we launched a multi-agent system into production. Here is what we learned from that experience.
Challenges
Today’s large language models (LLMs) are based on non-deterministic generative systems that may provide different answers to the same question. Even when you set the temperature to zero (the setting meant to reduce variation in model outputs), the same input can produce different outputs, and you may still see hallucinations. Unless instructed otherwise and you constrain the output, the LLM will fill the gaps in the generated text. Additionally, because the LLMs function by statistically predicting the next most likely token rather than evaluating abstract rules, they can mimic logical-sounding structures but are highly prone to reasoning failures, arithmetic errors, and errors in complex logic operations or deductive tasks; for example, they cannot yet reliably identify or reason about security vulnerabilities (Ullah et al., 2024). Common approaches to address these limitations in complex deductive tasks include pairing LLMs with neuro-symbolic approaches (Colelough & Regli, 2025), the use of retrieval-augmented generation, strict constraints (Raspanti et al., 2025), deterministic executions (Yao et al., 2023), stepwise verifications (Lightman et al., 2024; Khalifa et al., 2025), and several other approaches can be found in the literature.
If you use coding assistants, you have probably noticed what happens on longer tasks. The early parts of your prompt start losing probabilistic weight as more tokens accumulate, and the model forgets constraints you set up front. We call this context fatigue. It shows up in any agent that runs long enough.
The other recurring failure mode is that small reasoning errors compound across multi-step workflows. Each part of an agent (the LLM, the tools and APIs it calls, the retrieval layer, the memory store, sometimes other agents) has its own reliability characteristics. When you chain them together, the errors multiply rather than average out. Multi-agent systems, where you have agents communicating with agents, intensify this directly. As discoverability and integration of agents become easier with protocols like DNS-AID (AI agent discovery via DNS) and A2A (Agent-to-Agent), we will see more multi-agent systems emerge. In these situations, edge cases are almost infinite.
This makes it harder to have good coverage of the interaction patterns and use cases in our test set. We build test sets that we think cover the important use cases. Then, real users arrive, prompt the system in natural language, and find unexpected combinations. Additionally, deterministic software tests do not work well with natural language systems, where there is no single correct output.
Unlike a chatbot that only produces text, an agent acts in the world: it calls tools, queries systems, and can trigger real workflows. That capability is the whole point of an agent, but it also turns the agent into an attack surface. The numbers are sobering: the majority of agents built today are susceptible to prompt injection, with reported rates in the 80-90% range (Chang et al., 2026), and many guardrails can be bypassed simply by phrasing the prompt in a low-resource language (Yong et al., 2023; Shen et al., 2024; Marx & Dunaiski, 2026). Because none of this is fully resolved and new vulnerabilities keep surfacing, monitoring and a kill switch need to be in place from day one.
The last challenge is data quality. Agents depend heavily on it, and real enterprise data is usually siloed, inconsistent, incomplete, and poorly structured. Feed that into an agent, and it will make bad decisions. Combined with the long-context behavior we just discussed, it also produces what we call context poisoning (when the agent’s working memory gets filled with corrupted or contradictory data that then carries forward to other systems and agents). The companies that get the most value from agents tend to already have a strong data strategy in place.
Five pillars of a successful system
Andrej Karpathy named the process of increasing the reliability of your system as the “March of 9s”. The idea is that during the prototype or demo stage, your reliability is about 90% (one 9), and then for the subsequent 9s, you need to consider redundant system layers, extensive validation pipelines, complex fallback logic, runtime error containment, etc. When it comes to AI agents, the challenges go beyond reliability and can be grouped into the following pillars:
- Reliability, meaning predictable outcomes from a non-deterministic system.
- Control, meaning guardrails and permissions.
- Visibility, meaning observability and evaluation.
- Integration, meaning real workflow embedding.
- Economics, meaning scalable cost and latency.
By missing one of these, you increase your production risk and chance of hitting a production failure. However, it is not a black or white decision. Depending on the system and the audience, you can make trade-offs. For example, if the groundedness (i.e., whether the agent’s output reflects the source data) of the response is more important than latency, you may have a verification agent that fact-checks the answer with a cleaner context. Given a sequential flow, this would result in a latency increase at the cost of more reliable answers.
The architecture we ended up with
The minimum reference architecture for an agent system has multiple parts: a gateway for authentication, authorization, rate limits, policies, and routing; a tools and memory layer (APIs, databases, vector stores, key-value stores); and observability covering traces, logs, and metrics. The knobs you have to constrain the non-deterministic side include temperature, tool constraints, and what you pass as input, including system prompts.
Observability is what makes this tractable in practice. When something goes wrong, you need to understand what the model saw, what it reasoned about, why it chose the action it did, and which tool or sub-agent responses influenced it. We collect traces and spans, but if instrumentation is incomplete, you lose information, lose traceability, and lose the ability to reproduce a failure. When reproducibility is hard, it slows things down because developers cannot debug effectively.
The pattern we started with was a single agent that called a set of tools. That single agent picked up enough responsibilities quickly to feel like an orchestrator, so we factored out a supervisor who routed to specialized sub-agents. Over time, we moved to a hierarchical pattern, with a supervisor on top and domain-focused agents below, each with their own tools and prompts. Network and peer-to-peer patterns also exist. As we build more agents and sub-agents and our use cases evolve, we will continue to assess if our architecture should evolve along with and move to other shapes. However, the complexity of testing and changing a network or peer-to-peer system is substantially higher than that of a hierarchical one. We recommend earning that complexity by first hitting the limits of the simpler pattern.
We chose to group agents by domain, so each one stayed focused and manageable. When an agent gets too large, it becomes difficult to evaluate, debug, and understand.
A transparent user experience
The patterns for AI-driven systems are still being established and will evolve as the ecosystem matures. An interesting pattern is that users are more open to waiting if they can see the agent working or reasoning. A silent spinner frustrates them. Showing the agent’s plans, steps, and reasoning as it runs is one of the simplest and most effective UX improvements, and an area we are still actively improving.
The following example made this concrete for us: At the early stages of our development, we built a prototype that showed everything the agent was doing in real time. The production version, by contrast, only showed the final answer. When a product manager saw the prototype, they said they loved seeing the agent’s process and asked us to add that transparency to production. That feedback stayed with us. Even if not every user needs to see every step, giving them visibility builds trust. In enterprise and regulated settings, trust is what makes the product usable.
Planning is important as well. When the agent plans before it acts, users feel more in control of what will happen next.
Additionally, we looked at how AI players with very large user bases handle this and borrowed from their approach where it made sense. When creating the agentic experience in collaborative interfaces such as Slack and Microsoft Teams, we had to adapt the agentic experience since those surfaces do not let you do everything a web app can and have specific interaction rules and expectations.
Sharing memory between agents
When multiple agents work on the same problem, they need shared context. Not just message passing, but actual situational awareness, similar to what humans do when they get on a call to solve something together.
Here is an example that made this concrete for us: during an incident investigation, one agent posts that it thinks the database is the problem. A second agent starts working from that hypothesis. Ten minutes later, a third agent or a human discovers the database itself is fine. The real cause is a dependency service returning bad responses, which made the database look slow. What happens to the original “fact”? It has been invalidated. Everything built on top of it needs to be revisited.
This is where basic RAG (Retrieval-Augmented Generation) starts falling short. You need time and invalidation awareness in your memory. You need to navigate connections between facts. This is why knowledge graphs (structures that store entities and their relationships) are interesting in this space. They let you do semantic search across multiple hops, and they let you express relationships that vector similarity cannot. The honest caveat is that the tooling here is still immature. Several companies are working on it, but most do not yet have the scalability, reliability, or security for enterprise use.
Testing and evaluation
As in most software, you can follow the pattern of starting with identifying critical user journeys and the most impactful paths to understand what to test. For AI agents, you will need to define what your success indicators are and key metrics.
However, to effectively build and scale production-grade AI agents, teams must implement a rigorous, automated approach to evaluation, starting with golden datasets. Curating these high-quality, diverse collections is essential to accurately gauge how the system performs. This process requires defining what topics are asked to capture the breadth and depth of subjects the agent must handle, how they are asked by documenting the variety of phrasing and user intent, and who is asking to reflect the diverse roles and expertise of the user base.
Once a robust dataset is established, the next step is to automate the testing framework. In our workflows and as depicted below, the golden test questions are fed simultaneously into the AI agent under test and an expected responder generator (via code, API, or queries). An “LLM-as-a-judge” is then used to compare the agent’s actual output against the expected output. The outcome of this automated scoring is piped directly into a monitoring and observability platform, generating historical results and evaluation dashboards for the team to review.
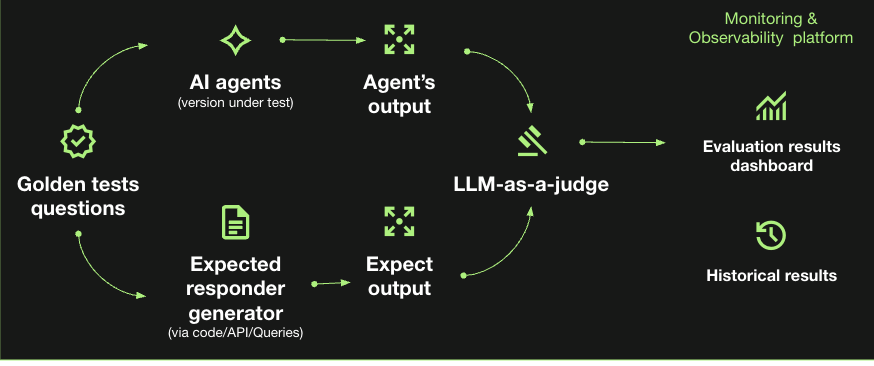
This automated pipeline forms the core of a comprehensive testing and evaluation strategy. A complete strategy builds upon the initial questions (what, how, and who) and incorporates several layers of testing. These layers include the baseline golden set tests using stubbed tools and seeds, scenario tests that introduce multi-turn interactions, noisy inputs, and tool failures, as well as adversarial suites designed to catch prompt injections, tool confusion, and hallucination traps. Finally, all of these evaluations are integrated into CI gates, allowing teams to run continuous offline re-evaluations whenever a model, prompt, or tool changes. For a deeper walkthrough of how we built this evaluation and observability setup, see Building end-to-end observability for AI agents in production.
Our initial golden sets (the curated input-and-expected-output pairs we use to test the system) cover roughly 95% of cases. Then, we rely on feedback loops to continuously update the test sets. Each iteration builds on the last, failures shrink, the test suite grows, and the system compounds its own improvement.
Cost and latency
Not all agent tasks require the use of an LLM. When we looked at how our initial versions of the agents were built, two things stood out. First, we were using a very large model to solve relatively simple problems. Second, we were using LLMs for tasks that did not require them at all. Some basic deterministic code could be used to solve those tasks. The deterministic option is usually faster and cheaper, and not everything inside an agent needs to be probabilistic.
The tradeoffs depend on the situation. Our approach is to build first, then optimize, taking into account the model trends. Models are getting faster, and token costs are dropping with efficient use. While deeper reasoning models can slow things down, the overall market trends are encouraging.
Metrics, evals, and guardrails
From a practical perspective, to sum up the above, here is what we have found useful to track.
- Task success rate (exact or graded). Did the agent actually complete the task?
- Groundedness rate, meaning whether the agent’s output reflects the source data rather than being made up.
- Tool success, timeout, and error rates. How often do the underlying tool calls work, time out, or fail?
- Loop and retry rate. How often does the agent get stuck repeating itself or retrying?
- Plan length and step efficiency. How many reasoning steps or tool calls does it take to get to an answer?
- p95 latency (the time below which 95% of requests complete).
- Cost per successful task.
- Safety violation rate.
- Human escalation rate. How often does the agent need to hand off to a person?
For monitoring, we use an observability platform with LLMOps and AgentOps capabilities. Although we collect user feedback as well, the goal is to catch problems before users do. Deployment gates enforce that.
Permissions matter as much as evaluation. We invested heavily in defining what actions an agent can take and which teams can use which agents. A common example: if there is a security incident and someone who is not on the security team asks the agent about it, the agent should not respond. These notions need to be in place to properly address enterprise scenarios.
Guardrails deserve special attention, because they were one of the areas we invested in most heavily. Treating safety as a first-class part of the system, rather than a layer bolted on at the end, is a large part of what made our agents safe enough to put in front of enterprise customers. Concretely, we do not allow our agents to operate in low-resource languages, since that was one of the most common bypass paths we observed. We enforce this at two layers, which gives us some defense-in-depth. Every guardrail check costs latency, though. You can run checks synchronously, which blocks the response until the check passes, or asynchronously, where the response is sent first and the check fires after. Non-critical checks can run async to avoid the latency penalty, but you only catch problems after the response has gone out. It is a tradeoff worth being deliberate about.
What did we learn?
Here are a few lessons we keep coming back to:
- Don’t underestimate the “March of 9s”.
- Engineer the boundaries up front. Decide what tools the agent has, what state it manages, and what it is and is not allowed to do, before you have code.
- Bring designers in from day one. The UX patterns for agentic systems are new, and the team needs to learn them together.
- AI-driven products aren’t just a chatbot with extra steps.
- Invest in traces, evals, and guardrails before you actually need them. If the system keeps breaking and you cannot detect it, you will find out through customer tickets instead. Keep everything traceable.
- Use staged rollouts, canaries, and feature flags. Some of the traditional DevOps playbook still applies in an agent world.
- Scale with AI on AI.
That sums up what we learned over the past year. The real work of shipping an agent begins after the prototype demos are done. Plan for that.
References
- Chang, H., Bao, E., Luo, X., & Yu, T. (2026). Overcoming the retrieval barrier: Indirect prompt injection in the wild for LLM systems. arXiv. https://arxiv.org/abs/2601.07072
- Colelough, B. C., & Regli, W. (2025). Neuro-symbolic AI in 2024: A systematic review. arXiv. https://arxiv.org/abs/2501.05435
- Khalifa, M., Agarwal, R., Logeswaran, L., Kim, J., Peng, H., Lee, M., Lee, H., & Wang, L. (2025). Process reward models that think. arXiv. https://arxiv.org/abs/2504.16828
- Lightman, H., Kosaraju, V., Burda, Y., Harrison, H., Cobbe, K., & Klimov, O. (2024). Let’s verify step by step. International Conference on Learning Representations (ICLR).
- Marx, D., & Dunaiski, M. (2026). Multilingual jailbreaking of LLMs using low-resource languages. arXiv. https://arxiv.org/abs/2605.18239
- Raspanti, F., Özçelebi, T., & Holenderski, M. J. (2025). Grammar-constrained decoding makes large language models better logical parsers. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) (pp. 485–499).
- Shen, L., Tan, W., Chen, S., Chen, Y., Zhang, J., Xu, H., Zheng, B., Koehn, P., & Khashabi, D. (2024). The language barrier: Dissecting safety challenges of LLMs in multilingual contexts. In Findings of the Association for Computational Linguistics: ACL 2024 (pp. 2668–2680).
- Ullah, S., Han, M., Pujar, S., Pearce, H., Coskun, A. K., & Stringhini, G. (2024). LLMs cannot reliably identify and reason about security vulnerabilities (yet?): A comprehensive evaluation, framework, and benchmarks. In 2024 IEEE Symposium on Security and Privacy (SP) (pp. 862–880). IEEE. https://doi.org/10.1109/SP54263.2024.00210
- Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). ReAct: Synergizing reasoning and acting in language models. International Conference on Learning Representations (ICLR).
- Yong, Z.-X., Menghini, C., & Bach, S. H. (2023). Low-resource languages jailbreak GPT-4. arXiv. https://arxiv.org/abs/2310.02446

