
- PagerDuty /
- Engineering Blog /
- Inside PagerDuty’s SRE Agent: How We Built Deep Incident Investigation
Engineering Blog
Inside PagerDuty’s SRE Agent: How We Built Deep Incident Investigation
by PagerDuty Engineering
June 24, 2026
| 28 min read
It’s 2 am. You’re paged for a complex incident. Multiple services degraded, no obvious cause. You pull up the SRE Agent and see what it is working on – no need to wait for its report five minutes later, instead you see its thinking in real time: “Investigating Service A Logs… ruling it out… moving to the deployment.” You start working together, suggesting places to investigate, and you pass information back and forth. Minutes pass. It’s still going, chasing hypotheses through logs, metrics, and recent deploys, and adjusting to your inputs. Together, you converge on an answer. Incident resolved. Back to bed.
That’s the agent we set out to build — one that runs as long as the investigation demands, works with you through a live incident, and keeps you in the loop the whole time. This set of desired properties: real-time updates, ability to course correct the investigation mid-run, and the ability to sustain a long-running investigation are constraints that shape the entire architecture. They compile into engineering requirements, and the requirements are where the difficulty lives.
Building AI-native products is fundamentally different from building AI-assisted ones. In AI-assisted software, the AI is a feature — a layer on top of an existing system. In AI-native products, the AI is the system, which means the failure modes, the reliability requirements, and the engineering trade-offs are all different. João Freitas covers it well in Production AI Agents: Closing the Gaps Between Idea and Reality. The SRE Agent’s investigation engine is a good case study in what that difference looks like in practice.
This post tells that story. We’ll walk through what broke in the single-agent design, the architecture decisions we made to fix it, the patterns that worked, the traps we hit, and the layers of infrastructure needed to make the SRE Agent’s deep investigation reliable in production.
Why did a single agent stop working
The first version of the SRE Agent was a single agent with a large context window and a set of tools, such as query logs, check metrics, and look at recent deploys. It worked and returned useful output. But as we pushed it toward more autonomous, deeper investigation, the kind of investigation a senior SRE would actually run during a live incident, a few specific problems started compounding on each other.
Context Rot
The Incident Context document we fed the agent was large: JSON blobs of alerts, past incidents, related incidents, change events, runbook content, and notes. As we added more sources — service topology, dependency graphs, historical patterns, remediation options — we hit a real phenomenon that’s been documented in LLM research: context rot (Liu et al., 2023). Beyond a certain threshold, model performance degrades as the context grows, not because the information isn’t there but because the model struggles to weight it correctly. More data, worse decisions. It’s worth noting that newer models are steadily improving at handling larger contexts, but there are still impacts upon cost and latency we want to avoid. This created a hard ceiling on how much context we could give a single agent before it started making worse calls, which took longer and cost more.
Instruction Overload
Every new feature meant more instructions. New tools, new guardrails, expanded system prompts. Research suggests there’s an inverse relationship between instruction volume and output quality (Jaroslawicz et al., 2025): as the prompt gets longer, the model’s ability to follow any given instruction decreases. In a monolithic agent, adding a new capability competes with every existing capability for the model’s attention. We could feel this in practice: agents that worked well at a certain feature set started degrading as we added to it.
Sequential Synchronous execution
Our agent ran synchronously in a sequential execution. Log searches and past incident recall combined take a considerable amount of time. A single root cause analysis: formulate a hypothesis, search for evidence, evaluate – chain these together, and it could take several minutes. Sequential hypothesis testing multiplied that. A moderately complex incident with three or four candidate causes could take 10+ minutes to diagnose.
No interactivity during execution
Users couldn’t ask questions or add context while the agent was working. If the on-call engineer knew the service had been deployed 10 minutes before the alert, they couldn’t inject that. They had to wait for the agent to finish, then restart with the new context included. For a live incident, this wasn’t just inconvenient — it meant the agent was operating without information the human already had.
These weren’t individual bugs to fix. They were structural consequences of running everything through a single agent with a single context and a synchronous execution model. The single-agent SRE Agent had served us well for initial triage. It couldn’t take us where we needed to go.
The evolution toward multiple agents
If a single agent struggles with a large context, the answer is to split the context into multiple agents and give each agent a focused subset of the context it actually needs. A coordinator that understands the full incident can delegate to sub-agents that each receive only the context relevant to their specific tasks. Smaller context per agent, better reasoning per agent, and the sub-agents run in parallel.
That was the idea. The question was how to actually build it.
What we were trying to do
The specific capability we were building looked like this. An on-call engineer gets paged. The SRE Agent picks up the incident context, decides this needs deeper investigation, formulates a few candidate root causes — say, DNS resolution failure, a bad deploy, a downstream dependency timeout — and spawns a sub-agent for each one. Each sub-agent goes off, queries logs, looks at metrics, and reports back with evidence either supporting or disproving its hypothesis. The SRE Agent synthesizes across all the findings and surfaces the strongest root cause candidate to the engineer.
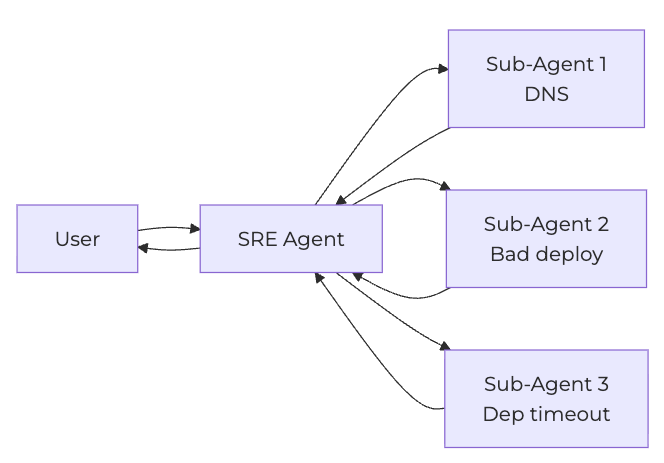
The non-trivial part is letting on-call engineers watch all this happen in real time. They want to see hypotheses arrive as they’re being investigated, not five minutes later as a single block. During a live incident, they might want to interrupt and say, “Skip hypothesis 3, I already checked the database,” or “Actually, also check the deployment logs from this morning.” If something goes wrong, they want to cancel the investigation to stop burning tokens in the background.
That set of requirements: real-time visibility, mid-run injection, and user cancellation, is at the core of decisions that shaped our multi-agent architecture, and getting to the end goal for us required experimentation. This blog is about how that experimentation went.
Three ways to run sub-agents
Before getting into what we built, it’s worth grounding why we built it the way we did. There are three obvious ways to run N sub-agents and combine their results, and each has a different cost.
Sequential

Run one sub-agent. Wait for it. Run the next. Wait. Repeat. Total time is the sum of every sub-agent’s duration. Simple to implement. No concurrency primitives, no partial state. The cost is latency. A slow hypothesis in the middle blocks everything behind it. If sub-agent 2 takes ten minutes, sub-agent 3 doesn’t even start until minute ten.
Parallel, wait for all

Dispatch every sub-agent at once synchronously. Block until the slowest one finishes. Synthesize everything together. Total time drops to the duration of the slowest sub-agent, which is much better. But the main agent is completely idle during execution. It can’t react to early results, it can’t tell the user what’s happening, and if a user wants to inject a new hypothesis mid-run, the graph is locked inside the parallel call until everything resolves. If one sub-agent hangs, synthesis is blocked indefinitely.
Parallel fan-out and concurrent fan-in

Dispatch all sub-agents at once (concurrently) as an asynchronous batch. Then, each time any one of them completes, the main agent processes the results asynchronously. Those results could be used to update the user, maybe even spawn a new sub-agent in response. Additionally, this opens possibilities for more dynamic interactions, such as user input being treated as a first-class event alongside sub-agent results, so new information can arrive mid-run and join the batch without restart.
Parallel fan-out and concurrent fan-in are what we wanted. The main agent is never idle. The user always has visibility. New work can be injected at any point. The hidden cost is implementation complexity. You need an interrupt-and-resume execution model, a buffer for concurrent arrivals, and a way to prioritize user events over sub-agent results. The rest of this post is essentially the learning of what it took to build that.
First Attempt: LangChain Deep Agents – subagents
The natural first step is to reach for an orchestration framework. LangChain’s Deep Agents give you an orchestrator/planner pattern out of the box — sub-agents are exposed as tools, and the orchestrator decides which tools to call and when. The framework handled dispatch, parallelism, and result aggregation.
We specifically tried the sub-agents feature. At the time, there was no async-subagents feature in the package — that has since been added and bundled in. We considered whether async sub-agents would have solved our problem, too; more on that later.
In sequential mode, the orchestrator waits for each tool to return before invoking the next. That’s the first execution model from above with additive latency and slow hypothesis blocking everything.
In parallel mode, the orchestrator dispatches all tools at once and blocks until every tool returns. That’s the second execution model where the main agent is idle the whole time, and there’s no hook between individual tool completions.
Within this framework-managed orchestration, there is no way to say “do something each time a single tool finishes, before the others have.” This isn’t really a missing feature — it’s a consequence of the execution model underneath. LangGraph, on which Deep Agents is built, executes with a Bulk Synchronous Parallel (BSP) model: it advances in supersteps, running a batch of work and then stopping at a synchronization barrier before the next batch begins. A parallel tool call is one superstep, so control only returns to the orchestrator once every tool in that batch has resolved. Which means:
- The orchestrator can’t react to sub-agent 1’s result at t=3min while sub-agents 2 and 3 are still running.
- No external event — including user input — can reach the graph while it’s blocked inside a parallel tool call.
- The tool set is fixed at the point of dispatch. You can’t inject new work mid-run without restarting.
Understanding this gap is the key insight: our desired properties are per-result reactivity, so we decided to build the reactive loop ourselves rather than relying on framework-level orchestration.
Building it the hard way: a reactive loop from first principles
Deep Agents pointed at the shape of the answer: detach each sub-agent as a background task — the supervisor spawns it, remains interactive, and the sub-agent signals back when it finishes. At the time we ran this experiment, we were working at the edge of what the frameworks supported, which meant we had to build things ourselves to understand the problem space. What follows is a walkthrough of what we tried and what we learned. The value was in understanding why each primitive was needed, and that understanding shaped the decisions that came after.
Moving from sync to async execution
A detached background task has to signal its result back somehow. The distributed-systems reflexes here are Kafka — the sub-agent publishes a completion event to a topic the supervisor consumes — or webhooks — the supervisor hands the sub-agent a callback URL it POSTs back to when it’s done. For a prototype with moderate task volume and no hard durability requirements, we reached for webhooks: the simplest thing that could possibly work, nothing new to run. Hold onto that choice — it quietly assumes the sub-agent and the supervisor live in different processes, and we’ll come back to it.
Two properties of LangGraph made building this ourselves harder than it looks, and both trace back to the async nature of what we needed. The first we’ve already met: its BSP execution advances in supersteps separated by barriers, which fights an async workload where results arrive at unpredictable times and you want to react to each one the instant it lands, not at the next barrier. The second is new here: within an asynchronous runtime, LangGraph gives you no abstraction for communication between graphs. Each agent is its own graph, so the moment you have a supervisor graph and several background sub-agent graphs, getting a result from one into another is a problem the framework doesn’t solve. Making agents talk to each other is essentially a distributed system problem. We started building the identity, transport, and mailbox machinery. Most of the work below is, in effect, building the per-result reactivity and cross-graph communication that LangGraph doesn’t provide.
What we tried: naive concurrent fan-out
The plan: spawn sub-agents concurrently, pause the graph at a clean checkpoint, resume it each time a result arrives, let the main agent do some work, and pause again until the next event. In a graph-based workflow engine, the mechanism for this is an interrupt-and-resume pattern — pause execution at a node, then resume with new data when ready. This pattern was originally designed for an approval flow – when a single agent “interrupts” its execution until a user approves it, which “resumes” the graph from a checkpoint. Our experiment consists of taking this execution model for the distributed communication between agents.
The simplest version. Spawn N sub-agents fire-and-forget. Pause the graph. Each time a sub-agent posts its result back, resume the graph with that result.

That approach is a solid core, but it breaks the moment two sub-agents finish close together and attempt concurrent resume. The first completion resumed the graph and triggered the main agent working loop. While the main agent was still processing, the second completion arrived and tried to resume the same graph. LangGraph either errored or started a fresh execution from scratch, which was worse because now we’d lost the state from the first arrival.
We needed a buffer.
What broke: concurrent resumes
Put incoming results into a local queue. Then the Main Agent would “drain the queue” in a loop, pulling one result at a time and only resuming the graph after the previous resume has fully completed and the graph has re-interrupted.
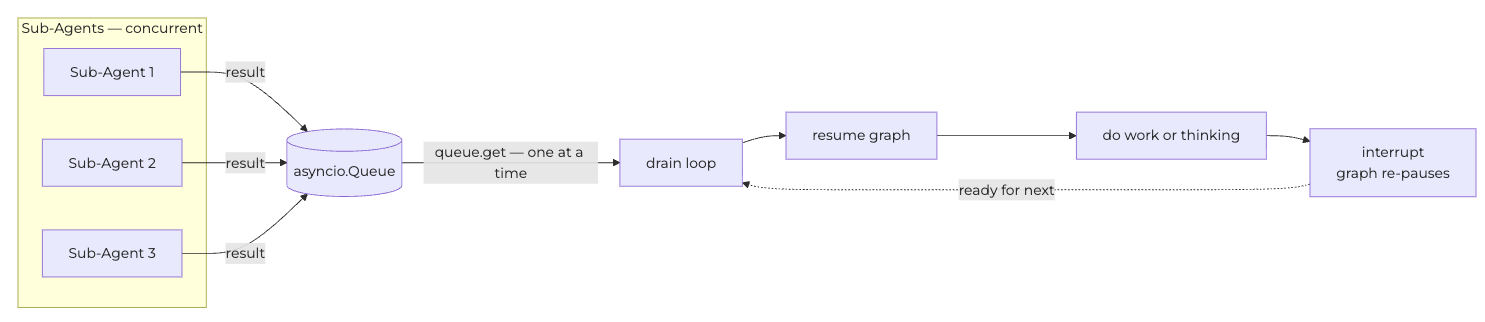
In practice, sub-agents finished at unpredictable times separated by minutes, so the queue was rarely actually occupied. It was insurance for the edge case where two arrivals landed within seconds of each other. But it had to be there, because that edge case was real and a corrupted state when it happened.
What we learned: a queue alone isn’t enough

The queue alone wasn’t enough. There was a window between “main agent completed” and “graph re-interrupts” where the drain loop could pick up the next item and call Command(resume=...) before the graph was genuinely paused. Same race, different shape.
The fix was a lock around the resume call. The drain loop held the lock while resuming, and the graph signaled through a callback when it had actually re-interrupted, releasing the lock. Now the drain loop could never issue a second resume until the first one had fully cycled back to a paused state.
The drain loop was the spine of the whole architecture. The graph was interrupted. A result arrived in the queue. The drain loop acquired the lock, resumed the graph, let it run through until it interrupted again, then released the lock and went back to waiting on the queue. Concurrent arrivals were serialized. The graph was never resumed twice in flight.
The insight: user input as a first-class event
So now we ensured that no message is lost, and comply with our requirement of continuous progress reporting by the agent. The other requirement is the mid-run steering of agent execution by user input. User input is just another actor producing events into the system. The natural thing was to push user messages into the same queue and let the drain loop handle them.
But with a regular FIFO queue, this had a problem. Suppose three sub-agent results were already buffered in the queue, and the user typed “also check the deployment logs from this morning.” The user’s message went in fourth. Or worse: by the time the drain loop got to it, the graph might have already finished and reached END. The user’s hypothesis would never spawn.
The fix was a priority queue with two priority levels. User input was priority 0 — highest, processed first. Sub-agent results were priority 1. Whenever a user event was sitting in the queue, it jumped the line and got processed before any backlog of sub-agent completions.

Each incoming event — whether from a sub-agent or a user — was wrapped with a priority level before entering the queue. User messages carried the highest priority, so they always jumped ahead of any buffered sub-agent results. Now, when the graph resumed, the next node — route_event — looked at what arrived and branched. Sub-agent results went to handle_sub_agent_result. User messages went tohandle_user_input, which added the new work to the state, marked it as pending_spawn, and re-entered plan so the new sub-agent got dispatched immediately.
Six nodes. The whole reactive loop fits in this picture. accept_event was where the graph spent most of its life — paused, waiting for the drain loop to deliver the next event from the priority queue.
That was the execution model. Now we needed a transport.
The three primitives that the experiment surfaced
By this point, we had the async execution model working. But we were still missing some fundamental system engineering details:
-
Each sub-agent needs an identity and a relation to the parent agent, both for traceability and control. When a user wants to stop a sub-agent, we need to propagate the event correctly. When an agent fails, we want to have a post-mortem analysis.
-
Each sub-agent needs to be able to communicate its status and results back to the parent agent efficiently. This requires a reliable event propagation mechanism that can handle high concurrency and potential failures.
By this point, we’d accumulated three layers of machinery, each solving a different problem: the task identity layer, event queue and transport layer, and reactive loop.
Primitive one: task identity
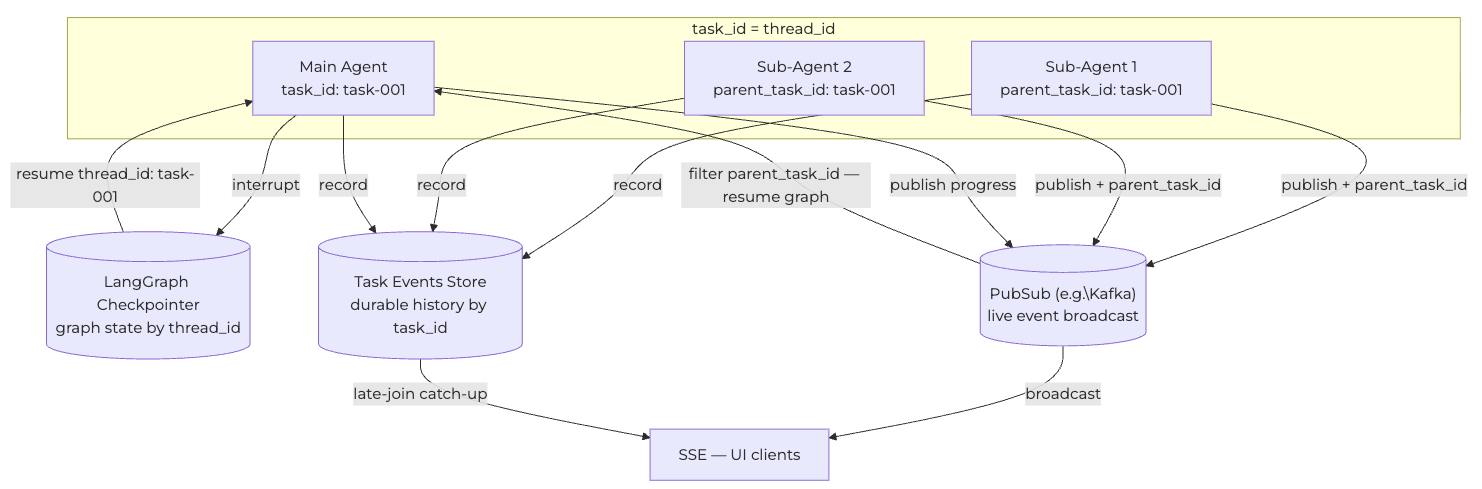
Every agent run has a UUID for its task_id. Every sub-agent carried a parent_task_id pointing back to whoever spawned it. The convention we settled on was that the LangGraph thread thread_id was identical to the agent’s task_id. This sounds trivial, yet it was the single most important convention in the system.
It meant that when a sub-agent published a completion event carrying parent_task_id: task-001, the parent agent immediately knew which LangGraph thread to resume. No lookup table. No correlation logic. The identifier on the event was the identifier of the graph that needed to wake up.
Main Agent (task_id: task-001, thread_id: task-001)
│
├── Sub-Agent 1 (task_id: sub-1, parent_task_id: task-001)
│ └→ completes → publishes event with parent_task_id: task-001
│ → parent agent resumes thread_id: task-001
├── Sub-Agent 2 (task_id: sub-2, parent_task_id: task-001)
└── Sub-Agent 3 (task_id: sub-3, parent_task_id: task-001)task_id was what was running. parent_task_id was what spawned it.
Primitive two: event queue and transport
Each agent wrapped its logic in a simple lifecycle: working → completed | failed | canceled. Inspired by the A2A protocol. The progress events flowed into a shared event queue. Every event that an agent published landed on the right channel automatically. Parent agents subscribed to the same channel to pick up sub-agent completions and resume graphs.
Alongside the PubSub broadcast, every event was also written to a durable event store indexed by task_id. PubSub alone was fire-and-forget — it wouldn’t reach clients who joined after an event was emitted. The store covered late-joining clients, catching up on an in-progress investigation. In production, this would need to be a fully durable store (thinking about Kafka persistence or a database) to survive pod restarts and handle crash recovery properly.
Progress reporting from graph nodes flowed through callbacks injected via LangGraph’s configurable dict, keeping the graph nodes entirely decoupled from transport. A node would invoke a callback it received through configuration without knowing anything about queues or task IDs — the transport concerns stayed at the agent runner level.
Primitive three: the reactive loop
This was what we built in the previous section. The interrupt/resume graph, the priority queue, and the lock. It depended entirely on the two layers below it. It used task_id === thread_id from layer one to know which LangGraph thread to resume. It used the PubSub subscription from layer two to receive completion events.
From demo to production
And there it was: every property we’d set out to get. Real-time visibility, mid-run injection, cancellation — all working. This experiment also surfaced the complexity and cost of such implementation. To coordinate between supervisor and sub-agents in production, we would have to build multiple services: a webhook callback path, a PubSub broadcast, a durable event store for each agent, an interrupt-and-resume graph, a drain loop, a lock, and a priority queue.
Building it the hard way, on purpose, allowed us to understand the depth of the problem and the only way to know which of these primitives were truly essential was to build all of them and feel where each one earned its place. But as something to run in production, it was the high-water mark of complexity.
The simplification: one process, not separate services
Stepping back from the proof of concept, the biggest lever was a question we’d answered implicitly the moment we reached for webhooks and PubSub: where do the agents run? We’d built as if they were distributed — separate processes, a broker between them, a durable store for the transport. A multi-agent system reads like a distributed system, so that’s the reflex. But when we actually reasoned through the distributed-systems toolkit, almost none of it earned its place.
The usual justification for splitting work into services is computational: CPU-heavy tasks you want to isolate and scale on their own. Our sub-agents do almost none of that. An investigation is overwhelmingly IO — call a log API and wait, call a metrics API and wait, hand the text to the model and wait. There’s no compute hotspot to isolate. The other common justification is organizational: separate services let separate teams own and ship independently. That doesn’t apply here either — a single team owns the whole sub-agent system, so there are no team boundaries for service boundaries to mirror. Spreading IO-bound agents across services buys operational complexity — deployment, service discovery, network failure modes, distributed tracing — without buying the thing services are for.
So the key insight is: every agent in a single run shares one process — the supervisor and all the sub-agents it spawns are co-located. Multiple concurrent runs can still land on different pods or processes, so cross-process primitives remain at the supervisor boundary: a durable store for checkpoints, a message broker, or a webhook for receiving work from the outside. What changes is that sub-agents don’t need any of that. Because they are guaranteed to live in the same process as the supervisor that spawned them, and an asyncio queue is sufficient for their mailboxes.
Durable supervisor, stateless sub-agents
Running all agents on the same service lets us relax a whole class of concerns, the biggest being that we never have to reconcile state across independently-running services. Instead, we draw a deliberate line between the supervisor and its sub-agents:
- The supervisor is durable. Its state is checkpointed, so it can pause, resume, and recover. The message queue lives inside the supervisor and is covered by the same checkpoint — events survive a crash because the supervisor’s state does. It’s the component that is long-running, so failing mid-execution could be wasteful minutes or hours of investigation.
- The sub-agents are stateless. They have no checkpoints. A sub-agent runs, produces a result, and reports back; if it dies, we re-spawn it rather than resume it mid-flight.
This asymmetry is the point. Making every agent durable would mean keeping N+1 checkpoints consistent and reconciling them on every restart. By concentrating durability in the supervisor and treating sub-agents as cheap and replaceable, there’s exactly one source of truth to recover.
In this design, everything lives in a single process. The mailbox sits inside it, and only the supervisor reaches out to a durable store:
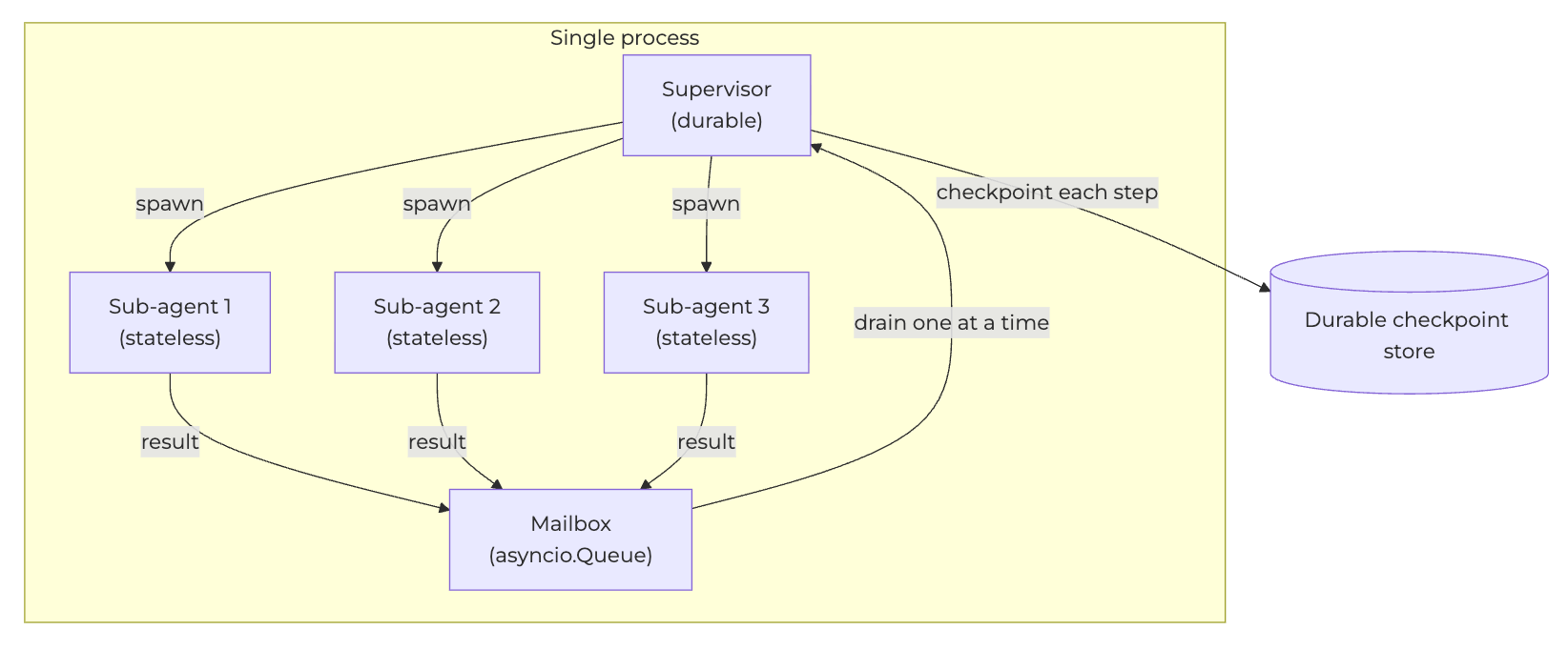
The distributed version we’d been building toward turns that single recoverable store into N of them, each behind a network and a message broker, with cross-process state to reconcile on every restart:
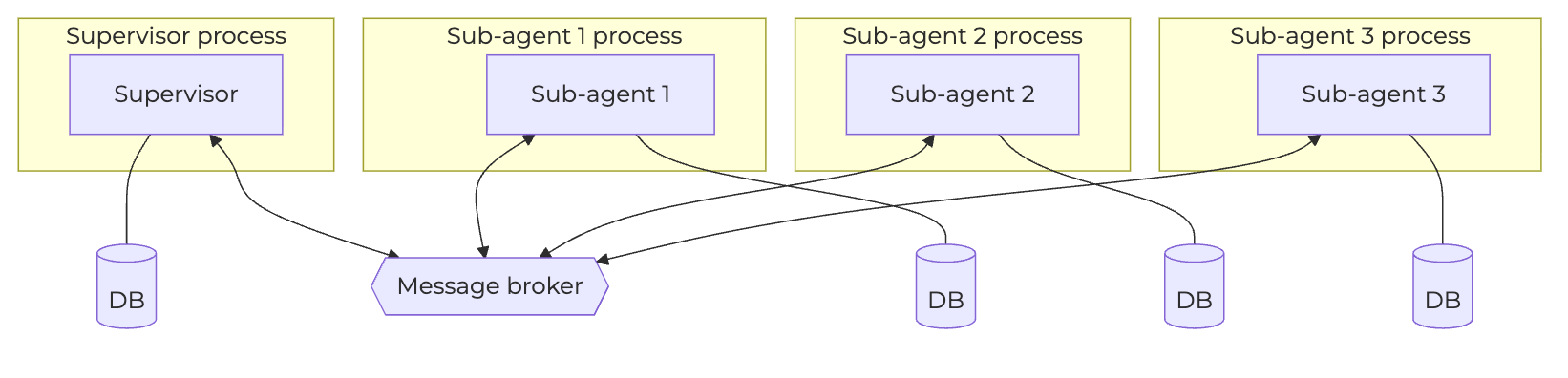
And that one source of truth is what lets the mailbox stay an ordinary in-process queue rather than something durable. The supervisor drains the mailbox one event at a time: it pulls an event, runs the execution forwards to the next interrupt, and that single step is checkpointed before it touches the next event. Because each step is atomic and persisted the moment it’s applied, the checkpoint never has to capture in-flight mailbox contents — every persisted step can start from an empty mailbox, since the supervisor is constantly draining it. On restart, the supervisor reloads its last checkpoint with an empty queue; any sub-agents that were still running are simply re-spawned, and their results land in the fresh mailbox. Nothing in the queue needs to survive a crash, because nothing durable ever lived there.
The queue, the lock, and the reactive loop we built above all live inside this one process — they’re in-process primitives, not distributed ones, which is precisely why they stay simple.
From webhooks to a mailbox
Once everything shares a process, the part of the proof of concept that collapses hardest is the transport. The webhook callbacks, the PubSub broadcast, the durable event store — all of it existed to move a result across a network from one process to another. Inside a single process, the answer is much smaller: an in-process mailbox — an asyncio.Queue — injected into each background task when it’s spawned. The sub-agent writes its result to the queue; the supervisor reads from it. No broker to run, no callback endpoint to expose, no network hop to fail.
This is the choice we told you to hold onto. Kafka and webhooks only ever earned their keep because we’d assumed the producer and consumer lived in different processes. They don’t need to. Dependency injection keeps the sub-agent ignorant of the transport: it’s handed a queue to write to and knows nothing about who reads it — exactly the decoupling the callback-injection layer gave us, now without the network.
Another simplification we weighed: native framework support
Collapsing to one process was the big lever, but it wasn’t the only simplification on the table. The other was to give up the custom reactive loop entirely and lean on native framework support. LangGraph’s async sub-agents are a good example: a native extension where the supervisor launches background tasks and returns immediately without blocking — the supervisor checks progress when it makes sense, and the complexity of managing concurrent execution stays in the framework rather than your codebase.
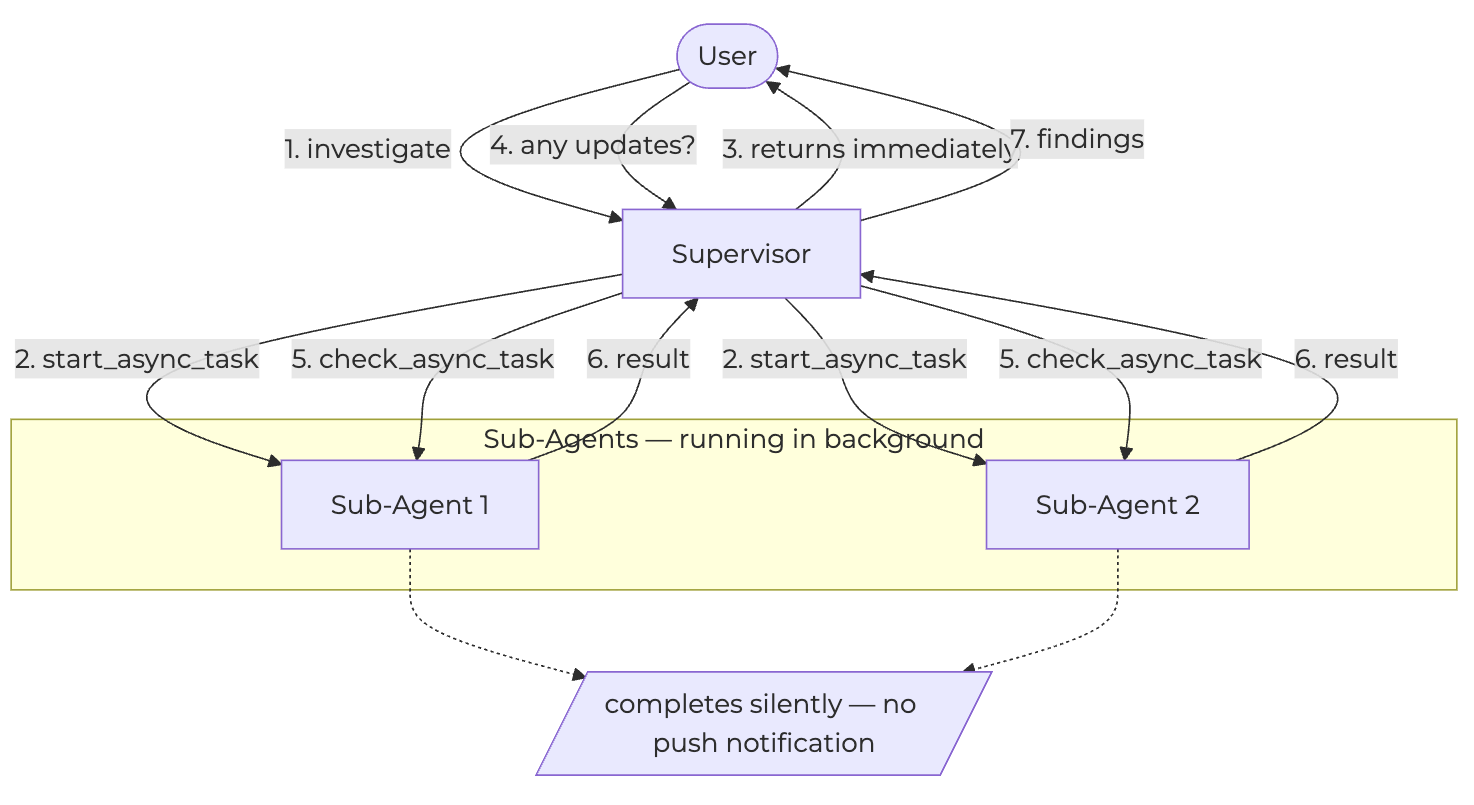
The pull-based polling model in these frameworks leaves a specific gap: there’s no push notification when a sub-agent finishes, which means no deterministic synthesis the moment each result arrives. But that gap often matters less than it first appears.
For most deep investigation scenarios, sub-agents run for minutes. A polling cycle of a few seconds is invisible, and the reduced complexity is a significant advantage. Before building the custom reactive loop described in the previous sections, first verify that your latency requirements genuinely can’t be met by polling. The interrupt/resume loop, priority queue, and lock coordination are not a silver bullet for all scenarios.
So why didn’t we use it? Not really because of poll versus push. The deeper reason is that the native support stops short of the two things our SRE Agent actually needs: true mid-run steering, and gradual emission of artifacts as each hypothesis resolves. To get those, our experience was that you end up reimplementing the same primitives we’d built by hand — identity to route events to the right graph, a transport for sub-agents to communicate back, a reactive loop with a priority queue so user input can preempt and steer the investigation while it runs. Since we still have to reimplement all of these, we figured that the native layer isn’t buying us much. The hard part—the inter-agent communication—is still ours to build.
Key Takeaways
Three observations shaped every engineering decision in this post, and they’re worth naming before the technical summary.
On AI-native product engineering: the failure modes here — context rot and instruction overload — don’t appear in conventional software systems. They’re specific to building products where AI is the core logic rather than a feature layered on top. Understanding them and designing around them from the start is what separates an AI-native product from an AI-assisted one.
On reliability: the SRE Agent isn’t a nice-to-have. It’s a tool engineers depend on when something is already broken. That context shapes every engineering decision in this post. The lock preventing state corruption, the priority queue ensuring user input isn’t buried under a backlog of sub-agent results — these might feel like over-engineering until the moment they’re not there. Building a reliable AI-native product means treating these concerns as first-class, not as polish you add after the happy path works.
On building to simplify: the most complex version of this system was a deliberate step, not a mistake. Building the reactive loop the hard way — webhooks, PubSub, a durable event store, the full primitive set — is what let us see which parts were essential and which were accidents of assuming a distributed architecture. The shippable design was the one we reached by taking complexity away: one process, a durable supervisor, stateless sub-agents, an in-process mailbox. Build the hard version to understand the problem; ship the simple one.
These observations point to the same concrete foundation. The pattern compounds: context rot and instruction overload push you toward multi-agent architectures; multi-agent parallelism pushes you toward async execution; and because the work is IO-bound rather than compute-bound, that async execution fits in a single process with a durable supervisor and stateless sub-agents — which is what lets the queue, lock, and priority pattern stay simple in-process primitives instead of distributed machinery you’d have to reconcile across services.
The following three insights, while building a multi-agent system, remain true regardless of the runtime engine:
- Identity (task_id === thread_id): routes events to the right graph without lookup tables.
- Event transport: delivers results reliably, handles late-joining clients, survives restarts.
- Reactive loop: processes results as they arrive, serializes concurrent completions, and treats user input as a first-class event.
For us at PagerDuty, experimentation is at the core of our engineering culture. The decision of whether something should be built or not is something we can confidently decide after actually building one of the options. Building a proof of concept — even just enough to demo it — is a proven way to get the actual feel of the trade-off, and, just as often, the feel of what to throw away.
Understanding why each layer exists is what lets you extend it or replace individual pieces as your framework evolves. That understanding is ultimately what makes the difference between inheriting an architecture and owning it.
References
- Freitas, J. (2026, June 11). Production AI agents: Closing the gaps between idea and reality. PagerDuty Engineering Blog. https://www.pagerduty.com/eng/production-ai-agents-closing-the-gaps-between-idea-and-reality/
- Jaroslawicz, D., Whiting, B., Shah, P., & Maamari, K. (2025). How many instructions can LLMs follow at once? arXiv. https://arxiv.org/abs/2507.11538
- LangChain AI. (2024). Deep agents [Software]. GitHub. https://github.com/langchain-ai/deepagents
- LangChain AI. (2024). LangGraph async sub-agents [Software documentation]. https://docs.langchain.com/oss/python/deepagents/async-subagents
- Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2023). Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 2023. https://arxiv.org/abs/2307.03172
- Google. (2025). Agent-to-Agent (A2A) protocol specification. https://a2a-protocol.org/latest/
About the authors:
Micah is a Staff Software Engineer at PagerDuty, specializing in AI agent architecture and platform-scale technical leadership. He co-led the SRE Agent development from concept to general availability, designing its core architecture and coordinating delivery. He also shapes cross-team agentic patterns at PagerDuty and is an active champion for AI tool adoption across the engineering organization.
Ralph Bird is a Principal ML Engineer at PagerDuty, focused on AI agents, LLM observability, and production-grade AI systems. Previously an astrophysics researcher at UCLA and a nuclear safety engineer at Rolls-Royce, he now builds autonomous AI systems for high-stakes incident response and reliability workflows. Ralph combines deep technical expertise across machine learning, distributed systems, and software architecture with a strong background in research and engineering leadership.
Viktor is a Senior Software Engineer at PagerDuty, where he builds AI systems and scalable backend infrastructure. With a full-stack background ranging from fast-paced product teams to major enterprises like Sky and NBCUniversal, he specializes in Python, AWS deployment, and AI application development using frameworks like LangGraph.

