
APAC Retrospective: Learnings from a Year of Tech Turbulence
by David Ridge
December 18, 2023
| 6 min read
Throughout 2023, one thing has become abundantly clear: regardless of an organization’s size or industry, incidents are inevitable.
Recently across the APAC region, we’ve seen numerous regulatory bodies clamp down on large companies who are failing to provide acceptable service, with some handing out quite severe penalties. For many, the cost of an incident is no longer just lost revenue and customer trust, but financial penalties and business restrictions.
Whether facing significant technical faults, disruptions in cloud services, or cybersecurity threats, modern businesses must proactively plan and ready themselves for potential incidents.
In this blog series, we’ll delve into the five stages within the incident lifecycle, offering insights into what organizations should do to ensure preparedness for the inevitable… their next incident.

——————————–
Part 1: Detect: Filtering the Noise
In the midst of all the chaos from recent outages and incidents this year, we would bet that somewhere in all the noise was the alert that truly mattered.
Observability stands as a foundational element of any resilient system. While originating from traditional monitoring capabilities, the term has evolved significantly as systems grow in complexity, offering a heightened view of business processes and customer journeys. Understanding the performance of your business across varying timeframes and workloads is crucial not only for operational excellence but also for fostering business growth.
However, comprehensive monitoring comes at a price. With the decrease in the cost of gathering data, monitoring applications are now collecting more and more data. This is great for analytics, but the problem lies in the fact that alerts are growing at the same exponential pace. People are becoming numb to alerts, making them less effective.
Many organizations are getting drowned in signal noise from the hundreds of metrics that are firing every minute from their various suites of observability tooling. With increased complexity and vast dependency death stars (We’re looking at you, microservices!), the chances of being alerted to something that is upstream and out of your control are ever-increasing. So how can we solve this problem?
At some point in time, each one of these many alerts will be useful and actionable, so we can’t just arbitrarily turn off 30% of our alerts to get a 30% noise reduction; we need a holistic view, and we need context.
Not all alerts are equal… it depends.
In order to understand your alerts, you need to understand your systems.
Not all services are created equal, so when an alert fires, you should react with an appropriate response.
What is the appropriate response? Well, it depends…
- What service is affected?
- What time is it?
- Does this service have 24/7 support or just business hours?
- What is the severity of the alert?
- What kind of alert is it?
- Is this something I can suppress?
- Have we already raised an Incident for this?
- How many times has this happened already?
- Is this related to something else?
- Did something change recently?
- Is a person even required?
- Is this a known issue?
- Will it auto-resolve in 2 mins as always?
- Can we auto-remediate it?
If you have the same alerting policy and mechanism for all alerts, and you don’t have a way of filtering the actionable and important from those that do not require immediate attention, then the people on the receiving end of these will eventually get alert fatigue and tune out, only responding when the Major Incident Management team comes calling.
The reality is that modern enterprises can no longer afford to leave this up to manual event management and ticketing queues. They need an automated solution that can manage the scale and complexity of large modern systems and the capabilities to ensure that the right filters are in place to route and correlate the relevant alerts, with the appropriate response, to the right person, in seconds.
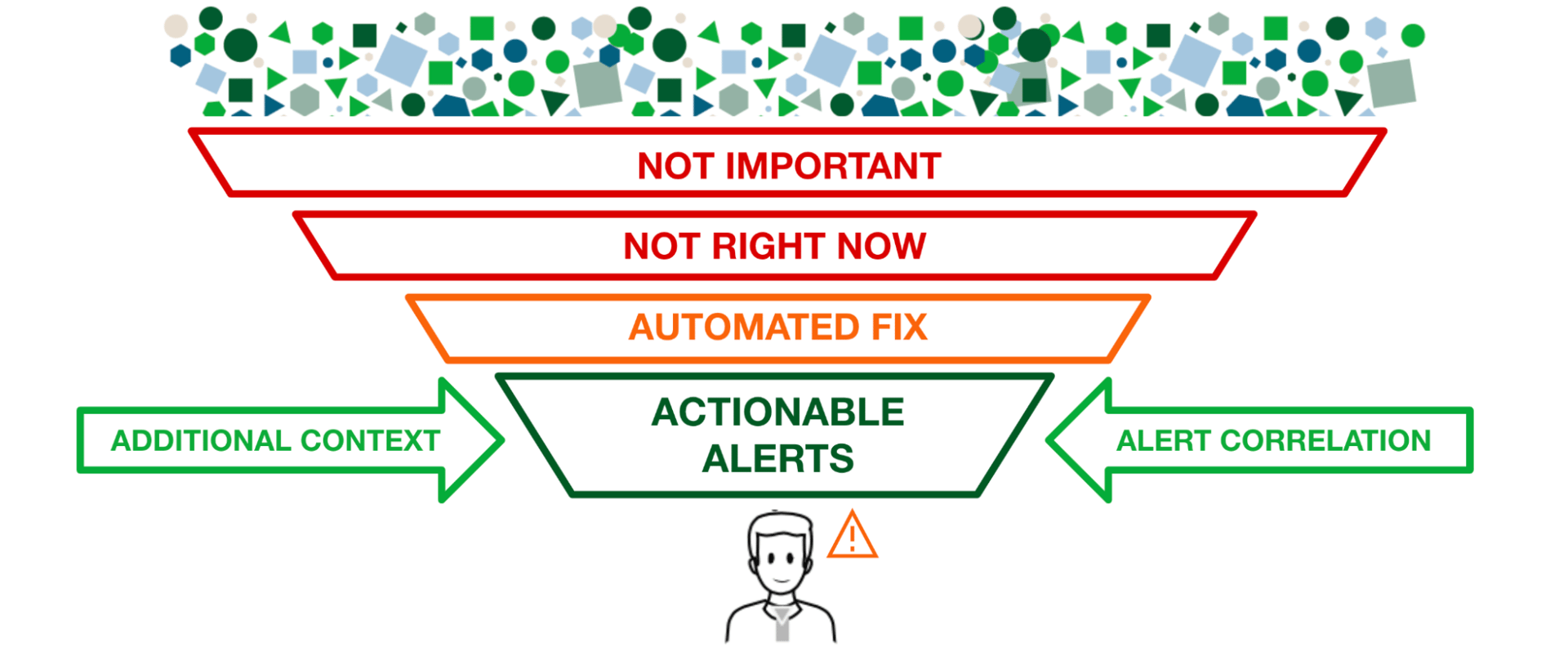
Context and relevance are key to alert management.
The evolution of basic event management into modern-day AIOps has brought with it a new set of capabilities that enable organizations to understand their alerts within the context of an ever-increasing dataset. Machine learning algorithms can understand whether an alert is actually an anomaly based on historical patterns, as well as how often that same alert occurs. Similarly, a holistic view of all relevant, active alerts and incidents, enriched with the context of their dependencies, can add some much-needed perspective to a single alert, potentially showing a cascading failure from a probable origin or a direct dependency failure.
Whether you are a single DevOps engineer on-call for your own application, a Level 1 Support Engineer responsible for assessing alerts from multiple systems, or a Major Incident Manager trying to gauge the blast radius of a failed change, having immediate context about what else is happening in the organization and which ones are specifically relevant to your incident can save you crucial minutes (even hours) at the start of an incident to make sure you are focused on the right signals and not being led astray by false positives
The goal for organizations is to move up the maturity scale from a reactive process to proactive, and ideally to a preventive state. However, this requires shifting the Incident Response from Major Incidents where there is a known customer impact, to responding to leading indicators of failure or degraded performance and remediating the issue before there is ever a customer impact. This can only be accomplished with some kind of intelligence or AIOps capability to understand the broader elements involved, provide immediate relevant context, and ultimately filter the noise.
In Part 2: Mobilise, we will be unpacking how organizations can optimize the human response element of the incident lifecycle. From initial responders and major incident managers, all the way through to business stakeholders and even the public, we will dive into what is required at each level of incident communications..
Want to learn more?
We will also be having a 3 Step webinar series. These webinars will focus on the P&L and how it has helped clients to focus on growth and innovation. Click below to learn more and register:
7th February 2024: Part 1: Optimising Incident Management: Boosting Productivity for increased ROI
21st February 2024: Part 2: Remodelling and Optimising Incident Response with AI and Automation
26th to 29th February 2024: PagerDuty101 (Registrations to open soon)

