
APAC Retrospective, Part 2: Mobilise: From Signal to Action
by David Ridge
January 4, 2024
| 7 min read
Continuing our series on 2023 learnings from APAC, it’s increasingly evident that incidents in organisations are not a matter of ‘if’ but ‘when,’ regardless of their size or industry.
Recently, the APAC region has been witnessing regulatory bodies taking stricter actions against major companies for subpar services, leading to substantial penalties. Aside from the immediate loss of revenue and customer trust, these organisations now face significant financial and operational consequences.
As businesses today face a spectrum of issues, from major technical failures to cloud service disruptions and cybersecurity threats, they must be in a constant state of alert and preparation. In this second part of our blog series, we’ll further explore the critical stages of the incident lifecycle, emphasising how organisations can gear up for the inevitable: their next incident.

Part 2: Mobilise: From Signal to Action
TL;DR Incident management requires organisations to cater to the diverse needs of stakeholders. Implementing automated and user-friendly on-call management systems is crucial for reducing mean-time-to-acknowledge (MTTA) and expediting initial responses. In major incidents, simultaneous mobilisation of targeted responder groups ensures time efficiency when it matters the most. Additionally, streamlining incident status updates with appropriate detail for each persona enhances communication effectiveness, allowing the organisation to manage the narrative and keep all parties reliably informed.
According to a recent report and survey conducted by EMA Research, most respondents see IT outages and significant incidents as either increasing (40%) or remaining roughly the same (27%). However, another 15% of participants acknowledged that they’ve experienced an increase, but say that they “can lower the impact with AIOps and automation,” according to the report. With the growing cost and pervasiveness of unplanned outages, organisations can’t risk adopting “good enough” incident management solutions and processes to manage their operations.
As much as we would love to automate and AI our way out of having incidents, people will always be at the centre of incident management. By their very nature, incidents are unplanned work that we didn’t predict or account for and (at least outside of known issues) require the mobilisation of people who can help manage and resolve them. Depending on the impact and severity of the incident, the size of the required group can change dramatically. Whether it’s paging the on-call engineer who builds and runs their own application, the classic ITIL framework tier 1, 2, 3+, or a major incident managed centrally with a cast of dozens, getting the right people aware of, and responding to, an incident can often be the biggest source of wasted time in the lifecycle.
Designing the Path of Least Resistance
The number one cause of this wasted time? People.
More specifically, manual processes and out-of-date records. When left to their own devices, people will often take the path of least resistance—the human brain is hardwired to do so. In this scenario, that is just manually calling the person you know, or the person who fixed it last time, or even just the team’s manager and let them decide who to call. This may feel like the quickest and simplest solution to mobilising a response, but it is a short-term win that will break down under the slightest bit of strain and complexity.
-
- What team owns the affected system?
- Who is on-call right now for that team?
- What happens if they don’t answer?
- How long do you wait?
- Who else should you call?
- What if they are on leave?
- Should anyone else be looped in?
All of these questions require time to answer, and steps to manually execute.
Even with many of these processes in place, people require flexibility. People go on leave, get sick, or have personal emergencies that see them unavailable on short notice. These daily occurrences are simple things that strain a manual or spreadsheet based approach to on-call roster management.
Fundamentally, for a human-centric process to work, we need to ensure the path of least resistance is also the right thing to do.
Modern organisations require an automated solution to mobilise the appropriate response to an incident. This system needs to be aware of the service ownership model within the organisation but also flexible enough to deal with the ever developing blast radius of incident. In addition, it must accommodate the people who use it, with easy changing of points of contact, automated escalations, and multiple modes of communication.
These requirements are even more business critical for a major incident as they are for getting a DevOps engineer awake at 2am. Without an automated solution, major incident managers must go through this process for each required team representative. And as we have seen repeatedly throughout this past year, time is of the essence. Getting the right people together as quickly as possible to begin the incident response process is crucial in the first few minutes of an incident. Being able to get ahead of the potential outage before there is customer impact can often be the difference between a regular day in operations versus making the morning news.
Therefore, having preset, scenarios or system-specific automated workflows that can be triggered on the declaration of a major incident can turn the first 30 minutes of an incident into the first 30 seconds.
No News is Bad News
One of the lessons to be taken from the past year of incidents, is that staying silent does not always end well. Regular updates to the various stakeholder groups is a must. Without them, stakeholders go looking for their own updates, and the official channel loses control of the narrative. Speculation and side stories become the latest update, and the perception of the incident may become bigger than the incident itself.
A key to managing the incident narrative is streamlined stakeholder communication—the ability to have persona-based communication channels for both internal and external stakeholders. Stakeholders should have the flexibility to subscribe to the systems and services that they care about (they can get noise too!) but incident managers should also have the ability to push an update to whoever they feel needs to know.
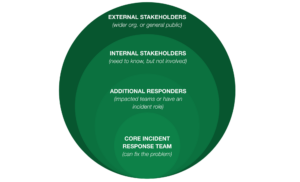
This is where our ever increasing circles of communication come into play. Different stakeholders may require different levels of detail. Some internal terms and system names may not translate externally. Similarly, an update to a Slack or Teams channel may not be appropriate for the highly formatted and structured email that goes to the executive team.
Persona-based communication templates can auto-fill the static repeatable data, but also use Generative AI to author an appropriate status update for approval. They can help modern organisations reduce the toil of the major incident managers so that they can focus on restoring service. Additionally, having this update automatically go directly to an external comms specialist, who can adapt and approve it for external stakeholders and/or the general public via updates to the external status page, is a way of ensuring that incident communications are consistent and regular.
In summary, it is important for organisations to understand the needs of the various groups when it comes to incident notifications and communications. Having an automated and human-friendly way for on-call management can significantly drive down mean-time-to-acknowledge (MTTA) times for initial responders. Scaling this out to simultaneously mobilise multiple targeted groups of responders in major incidents can ensure that precious time is not wasted when it matters the most. Finally, streamlining the incident status updates so that each persona gets the appropriate level of detail will ensure that the organisation can manage the narrative and keep everyone reliably informed.
A Look Ahead
In Part 3: Triage, I will dive into the various tasks, actions, and runbooks that are utilised during an incident to see how organisations can safely democratise their tribal knowledge and empower level 1 teams and junior engineers to reduce the size and duration of an incident. We will also look at some ways to streamline the incident process by automating some of the runbooks completely.
Want to Learn More?
We will also be hosting a three-part webinar series that focuses on the P&L and how it has helped clients to focus on growth and innovation. Click the links below to learn more and register:
- 7th February 2024: Part 1: Optimising Incident Management: Boosting Productivity for increased ROI
- 21st February 2024: Part 2: Remodelling and Optimising Incident Response with AI and Automation
- 26th to 29th February 2024: PagerDuty101 (Registrations to open soon)

