
- PagerDuty /
- Blog /
- Automation /
- APAC Retrospective: Learnings from a Year of Tech Outages – Dismantling Knowledge Silos
Blog
APAC Retrospective: Learnings from a Year of Tech Outages – Dismantling Knowledge Silos
by David Ridge
January 16, 2024
| 8 min read
As our exploration through 2023 continues from the second blog segment, “Mobilise: From Signal to Action”, one undeniable fact persists: Incidents are an unavoidable reality for organisations, irrespective of their industry or size.
In the APAC region, a surge in regulatory enforcement has been observed against large corporations failing to meet service standards, resulting in severe penalties. For these companies, the repercussions of an incident now extend beyond lost revenue and dwindling customer trust to hefty fines and operational restrictions.
With challenges ranging from major technical issues to cloud service interruptions and cybersecurity vulnerabilities, modern day businesses must take a proactive approach to incident management. In this third instalment of our blog series, we dig deeper into the incident lifecycle, thus revealing strategies for businesses to remain prepared for what can no longer be avoided: their next incident.

Part 3: Triage: Dismantling knowledge silos
Overview
As we dive deeper into the challenges facing incident management, it has become a recurring issue where a handful of seasoned engineers are consistently involved in all incidents. One of the main reasons for this is a lack of knowledge, access, and skill of the primary on-call responders to perform the initial triage steps during an incident. This results in the senior engineer being called each time to perform what is often a simple and repeatable process. This gap in knowledge, skill and access is known as “The Automation Gap”.
Using an automation orchestration tool to enable event-driven automation, organisations can empower on-call responders with immediate access to automated runbooks, personally crafted by subject matter experts. However, a phased approach is required, starting with diagnostics, progressing to contextual remediations, and ultimately achieving auto-remediation. The delicate balance between automation and human judgement, especially in regulated industries, remains a focal point, but can achieve considerable success.
At this point in the incident lifecycle you have controlled the fire hose of alerts coming from sources all around your organisation, and you have automated the mobilisation of the correct on-call responder only for the relevant actionable items. Then why is it always the same small group of senior engineers that are on all the incidents?
Well, who else has the knowledge, skill, and access to run the scripts required to diagnose the problem? After all, they designed the system and wrote the scripts, so it would be just quicker and safer for them to do it? Wouldn’t it?
If the issue was a once off, and during working hours, then maybe it would. But it’s far more common for it to be after hours on a recurring or frequent basis. It results in the same few experts being involved in every incident, as they hold all the tribal knowledge of how things really work and how to quickly and properly triage problems. For each affected system, they have developed their own standard set of health checks and runbooks to get a deeper view of what could be causing the issue.
Tribal knowledge of undocumented dependencies, or a bespoke script that they wrote themselves and only exists locally on their own machine are the reasons why they are needed on each incident. Without them, the on-call responder may spend the first hour trying to figure something out that might take our subject matter expert (SME) a mere minute or two.
“Quicker and safer” are now subject to waking up one specific burnt-out senior engineer who has to run some complex commands on a production system at 2am. Their knowledge is business critical, but they are the bottleneck of the incident lifecycle.
The Automation Gap
This very common scenario is called the Automation Gap.
It can be measured in a number of ways such as number of required escalations, or additional responders per incident, or as the gap (in minutes and people) between the person who is alerted about the incident and the person who fixes the incident.
Basically, the larger the Automation Gap is, the longer and more expensive your incidents are going to be.
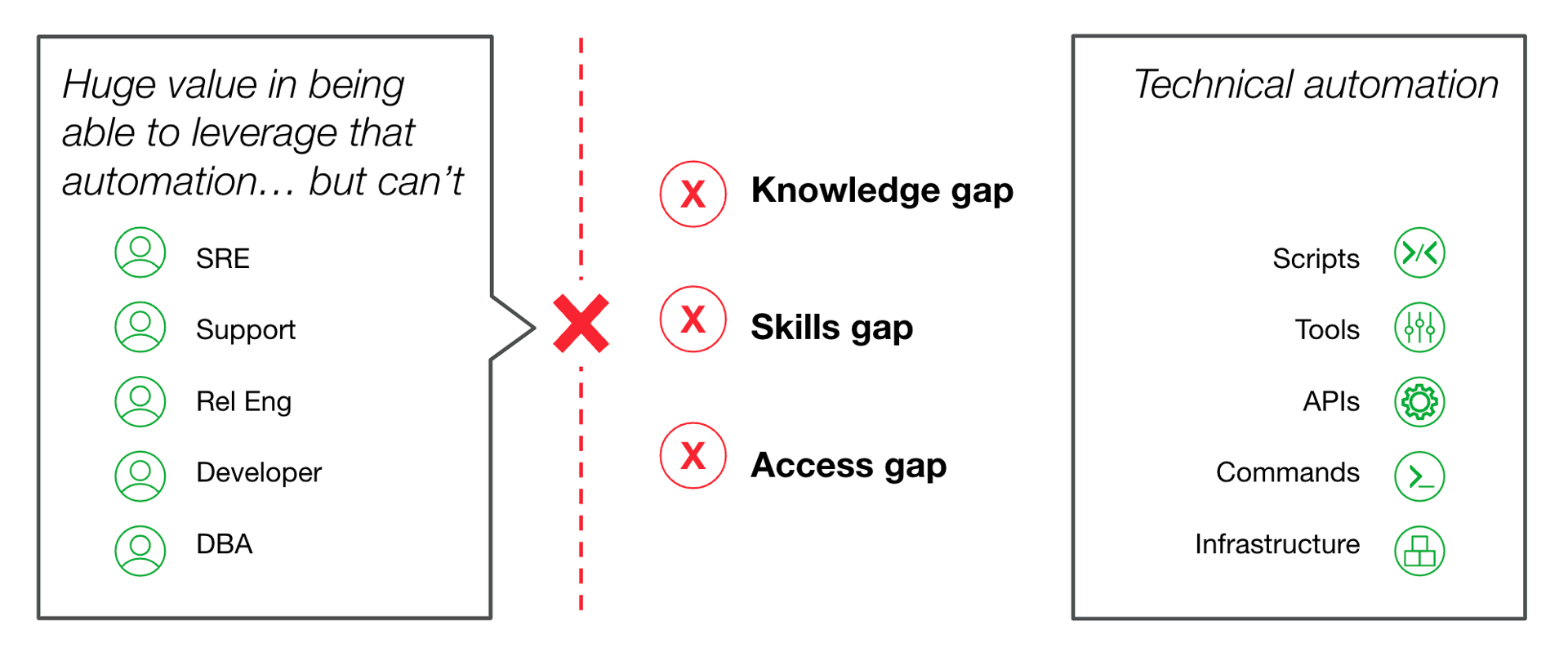
The Automation Gap between who needs to use the automation versus who can use it
The reasons for the gap can be broken down into three main categories: knowledge, skills, and access.
- Knowledge Gap: Companies can spin up a lot of different kinds of services, and often have many covering different use cases—so many, no single person can know them all.
- Skills Gap: Much of the automation that exists today requires specific expertise to properly use, and developing broad value requires additional skills like knowing how to write scripts. Many generalists lack these specific skills.
- Access Gap: Modern security standards dictate that privileged access should not be handed out flippantly to anyone.
Modern organisations need to be able to dismantle the knowledge silos in order to avoid incident bottlenecks and reliance on a single individual, without compromising the resilience or security of their systems. They can do this by having automation orchestration capability that is event-driven, where the event in question is the incident.
Event-Driven Automation
An event-driven automation capability must be available when the alert or incident occurs, and should have the option to be automatically, conditionally, and manually triggered depending on the nature of the incident.
The access gap is addressed by the orchestration tool itself, providing a safe and secure way of accessing the data from controlled production systems. This means that the incident responder does not have to worry about manually accessing the affected system.
The knowledge and skill gaps are addressed by having the SME that is always called into incidents as the one who creates the automated runbook. Chances are they already have the scripts and logic created somewhere themselves. This is the knowledge that can be wrapped in an orchestration layer and safely made available to on-call responders instantly.
Of course, not all incidents can be automated to resolution. The two main qualifiers for whether something should be automated are that it is known (you can’t automate something you don’t know about) and that it is repeatable. In the dynamic and unpredictable world of incident management, “known” and “repeatable” resolutions are few and far between.
However, the health checks, false positive validations, and diagnostic scripts that make up most runbooks or standard recovery procedures are very known and very repeatable. In fact, triage and diagnosis often take up more time than any other stage of the incident lifecycle.
Runbook automation can be applied at multiple stages of the incident lifecycle, anywhere that there are repeatable processes consuming valuable minutes (or hours) when it matters the most. Similarly, regardless of your operational model, event-driven automation can be applied to drive down triage times during an incident.
For example:
NOC: Adopt L0 automation to run before a human is called. This reduces MTTR, risk, and cost to the business as well as mitigate burnout on first-line response teams.
SRE: Automate the full journey of an event by building auto-remediation or “human in the middle” automation where applicable. This reduces MTTR and preserves SRE time for valuable initiatives like scaling automation across more teams.
MIM: Populate incidents with automated diagnostics and normalise event data so it’s consumable. This improves triage speed and helps all your responders work as effectively as your best responder.
Engineering: Intelligently route incidents to the right team every time and create auto-remediation for well understood problems. This preserves engineering time for value-add initiatives that will generate revenue.
Crawl, Walk, Run
When thinking about automation within incident management, it is common to go straight to the shiny, sexy closed-loop, self-healing, auto-remediation of incidents. The reality is that only a small portion of incidents can be auto-remediated. We have previously mentioned the known and repeatable requirements that automation generally has. However, what is known, and what is repeatable, is the amount of time spent on trying to get the information required to triage and diagnose the problem.
This type of automation is also considerably safer to run automatically than something remediatory. Organisations, particularly in highly regulated industries, require an accountable, auditable, person with human judgement to approve the restart, rollback, or change of production systems. So combining automation and human judgement gives a human-in-the-middle automated process that combines the best of both.
Starting with just automated diagnostics enriching the incident with the details that the responder needs as soon as they get notified is a powerful but safe starting point (crawl).
Giving the responder contextual remediations to manually trigger based on the diagnostics adds another level of efficiency (walk).
Finally, based on previous incidents, auto-remediating the incidents that are known and do not require a person to make a decision, removes these incidents completely (run).
In Part 4, we will explore incident resolution. We will unpack the processes and decision making that go into restoring service versus fixing the root cause, and analyse the requirements of declaring an incident resolved.
Want to Learn More?
We’re also going to be hosting a three-part webinar series that focuses on the P&L and how it has helped clients to focus on growth and innovation. Click the links below to learn more and register:
- 7th February 2024: Part 1: Better Incident Management: Avoiding Critical Service Outages in 2024
- 21st February 2024: Part 2: From Crisis to Control: How You Can Modernise Incident Management with the help of Automation & AI
- 26th to 29th February 2024: Part 3: PagerDuty 101

