
- PagerDuty /
- Blog /
- Integrations /
- How to Introduce Automation to Incident Response with Slack and PagerDuty
Blog
How to Introduce Automation to Incident Response with Slack and PagerDuty
by Slack
June 24, 2021
| 5 min read
Major-incident war rooms are synonymous with stress. Pressure from executives, digging for a needle in a haystack, too much noise—it’s all weight on your hardworking technical teams.
Incident responders clearly need a more effective way to collaborate across various technical teams. A method that both minimizes interruptions and keeps stakeholders up to date while ensuring everyone has the right level of context to do their job.
Many organizations already use PagerDuty and Slack together to quickly alert on-call responders but aren’t aware that integrating the two apps can speed up resolution from incident declaration all the way through postmortem. Engineering and IT operations teams are able to:
- Quickly spin up incidents with complete context for new responders
- Streamline troubleshooting and minimize interruptions
- Turn incident-review insights into immediate action
The cumulative result is reduced mean time to repair, less stressed engineers and, ultimately, happier customers. Let’s dive into how users of Slack and PagerDuty can successfully minimize incidents and downtime.
Quickly Spin Up an Incident
Once an incident is declared, the PagerDuty integration for Slack vastly reduces the time it takes to begin troubleshooting. Many of those improvements come from automation. Here’s how it works:
- Monitoring and APM tools send alerts through PagerDuty and into various Slack channels, typically dedicated to a specific team or app (e.g., #team-web-app). Alternatively, your team could create a single alerts channel (e.g., #alerts-infra).
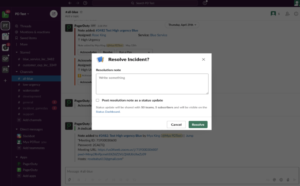
- Someone who can appropriately assess impact and severity will manually declare the incident and provide additional context for the group. This can easily be done in the alerts Slack channel with the click of a button.
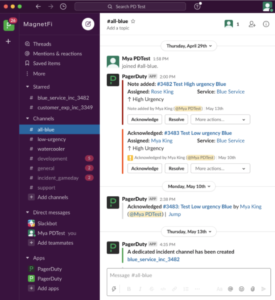
- PagerDuty automatically spins up a new incident channel that’s easily searchable by date or unique identifier (e.g., #incident-___) and invites all on-call responders, who are pinged via Slack and other methods (like SMS). A Zoom call is automatically started and a message (with links to the specific incident channel and Zoom call) is automatically sent to a general #incidents channel, ensuring nonresponders also have visibility.
Streamline Troubleshooting
Incidents are often complex and span multiple systems—observability metrics, traces and logs provide many different perspectives on root cause. Effective cross-team collaboration and reducing noise are critical for resolving incidents quickly and correctly. To that end, here are three ways Slack can help responders get up to speed quickly while minimizing distractions for their peers:
- When new responders join the incident channel in Slack, they can simply scroll up and see the full history of what’s already been explored, ruled out and accomplished, without interrupting ongoing investigations. All key status updates, messages and documents are neatly pinned atop the channel for quick reference. New joiners get up to speed quickly, troubleshooters stay focused on resolution and incident commanders manage the incident process, not individual demands.
- In-channel threads are started for high-velocity and detailed conversations around subtopics like performance degradation or cloud infrastructure. By threading these deeper dives, responders can run parallel investigations while keeping the main channel focused on major updates. When a key finding or decision is made in a thread, it’s posted back to the channel for all to see.
- Emojis can be fun, but they’re also incredibly fast and informative when collecting input and approvals during incidents. To communicate short notes without creating unnecessary noise, responders can simply mark messages with emojis. Popular conventions include 👀 for “I’m looking into it,” 👍 for “I agree” and ✅ for “I’m finished with that.”
Turn Incident Reviews into Instant Action
Effective incident reviews require multiple teams’ participation, which means they’re at best a hassle to organize. Even worse, when reviews are conducted, a lack of certainty often leads to guessing, bias and blaming. Here’s how it should go:
- During the heat of an incident, responders can mark messages with 📮 to signal an insight or action to follow up with during the incident review. After all is clear, an incident reviewer can simply search for any message marked with this particular emoji, in this particular channel. Your team could also build a simple workflow that automatically posts these messages to a dedicated channel (e.g., #inc-review-insights). A thread or even a channel can be started to discuss each insight and ensure it’s acted upon.
- To conduct the review, an incident reviewer scans the incident channel to see a time-stamped audit trail of exactly what happened, what decisions were made, who was involved and any observability metrics. Incident-review meetings are straightforward and action-oriented, without guessing or arguing about the truth.
- Each incident channel is archived and preserved so that anyone (even new employees) can quickly search and reference if a similar issue occurs in the future.
Transform From Reactive to Proactive Incident Management
An effective incident management process is not complicated or difficult to configure but can be a lot of change for IT operations and engineering teams. Take the first simple step and install the PagerDuty app for Slack to automate incident-channel creation and on-call responder invitations. From there, you can run your virtual war room just like you do today and post key decisions and summaries back into the channel where all stakeholders and responders have visibility.
As you grow more comfortable collaborating in real time with Slack, you can gradually pull more communications and teams (even business stakeholders) into the process. Soon enough, you’ll be significantly reducing MTTR and downtime with PagerDuty and Slack.
Reach out to someone at Slack for a customized plan that will transform the way you manage incidents before the next “big one” happens.

