
- PagerDuty /
- Engineering Blog /
- How We Closed the Gap Between Infrastructure Health and Customer Reality
Engineering Blog
How We Closed the Gap Between Infrastructure Health and Customer Reality
by Dheeraj Balakavi
June 8, 2026
| 10 min read
On August 28, 2025, PagerDuty experienced one of its most significant customer-facing incidents in recent memory. A logical error in a gradually enabled feature caused Kafka, the backbone of PagerDuty’s event ingestion and asynchronous processing architecture, to become unstable under load.
We’ve already written about what happened technically and how we responded, as well as the human side of operating during the incident. What the incident exposed for us was something subtler than the specific failure mode itself: a gap in how we were measuring rollout safety in the first place.
We already had layers of automated and operational safeguards before that day. The strongest rollout signals, though, were centered on service-level and infrastructure health, which are exactly the signals most rollout systems lean on. But healthy services and healthy customer journeys are not the same thing. A deployment can pass canary analysis, look clean on dashboards, and still leave a critical end-to-end journey broken.
The changes described in this post would not necessarily have prevented the original Kafka failure, which only became fully visible under real production conditions and traffic patterns. But it made us look more closely at what was missing in how we deployed safely. The lesson was that the journeys our customers actually rely on deserved to be a first-class input into rollout decisions, not a downstream signal for teams to interpret only after a deployment advanced.
This post is about Watchtower, PagerDuty’s end-to-end testing platform for critical API and UI journeys, and how those journeys became deployment gates within our broader rollout safety model.
Raising the Bar, Not Starting Over
The shift was not from “untested” to “tested.” We already had a mature validation ecosystem: unit tests, integration tests, automated checks including canary analysis, monitors, dashboards, alerts, PagerDuty for incident response, and operational review processes.
Each layer in that stack is good at a specific job. Unit and integration tests catch regressions in well-defined units of behavior. Canary analysis and infrastructure monitors catch service-level and traffic-level anomalies as a change rolls out. Dashboards and alerts surface deviations from normal in production. Operational review helps with rollout decisions that still require human judgment. None of those layers, individually or together, were designed to answer the specific question of whether a multi-system customer journey still completed successfully as a deployment progressed.
We had also built end-to-end tests in different parts of the organization, each focused on the journeys most relevant to their service area. Much of that work was valuable, and some of it carried directly into Watchtower. But it had naturally grown up the way these things tend to at scale: in different repos, on different cadences, owned by different teams, each tuned to a specific slice of the product. In practice, if we needed to know whether a critical cross-system journey was still healthy during a rollout, the answer required pulling from multiple teams and tools — and often we didn’t have time for that. What was missing was a single layer that could speak to whether critical customer journeys were healthy across services and bring that signal directly into rollout decisions.
Watchtower was created to close that gap, not by adding another testing layer alongside the others, but by giving us one platform where critical customer journeys are owned, run, and gated against real environments. It represents a shift from component and infrastructure confidence to journey confidence. A deployment is not considered safe to advance simply because individual systems look healthy. It must also preserve the end-to-end journeys that customers actually depend on.
What Watchtower Is and What It Isn’t
Watchtower is our unified platform for testing critical journeys across both API and UI. It gives us a standardized way to author, run, and maintain high-signal tests against real environments. A journey is an end-to-end user-facing flow that crosses service boundaries, such as receiving an event, creating an incident, escalating it, and notifying the right responder.
Global journeys are tier-1: when they fail, a large portion of customers and functionality is affected, often spanning multiple service areas. When these are down, our overall reliability takes the biggest hit. They run as part of the standard deployment path, and answer questions like:
- When an event hits the Events API, does it flow through the ingestion pipeline, create an incident, and deliver notifications through email, SMS, and push within our SLA?
- Can a user create, acknowledge, and resolve an incident through its full lifecycle?
- When the primary on-call does not respond, does the incident escalate to the next level in the policy?
- Can a user create and resolve an incident fully through the web interface?
Domain journeys are scoped to specific systems and run when changes touch those systems — their failure affects a narrower set of customers and functionality. The teams closest to those journeys own them:
- The alerts team validates that related alerts correctly group into a single incident.
- The webhooks team validates that V3 webhook notifications reach subscriber endpoints within our SLA.
- The mobilization team validates that round-robin escalation policies advance assignment state correctly through the UI.
For example, the event ingestion journey posts an event to the Events API, the API our integrations use to send events, asserts that it flows through the pipeline and creates an incident, and then verifies that the corresponding notification is delivered to the responder. Each step has an expected SLA enforced as a test assertion. If the incident is not created or the notification does not arrive within its expected window, the journey fails as a hard failure, not as a warning or a logged metric.
Watchtower tests run against our actual environments and real code paths. They use controlled test resources rather than mocked services or separate test environments. A passing result gives us evidence that the real journey completed end to end, not just that a simulation of it did.
Metrics, dashboards, and alerts remain essential — they tell us how individual systems are behaving. Watchtower answers a different question: whether users can still complete the journeys that depend on those systems. That distinction is what gives Watchtower tests their authority in rollout decisions.
Giving the Tests Real Authority
We ship changes through a graduated rollout pipeline. Deployments do not jump directly to 100% production traffic. Traffic expands incrementally across environments and traffic slices, widening only after validation at each stage. At each promotion boundary, where a deployment moves to the next environment or a larger traffic slice, the relevant Watchtower test suite now runs first.
If the tests for all journeys pass, the deployment continues. If they fail, the rollout stops at that boundary and follows the configured failure path for that service and stage. The change is investigated before any retry.
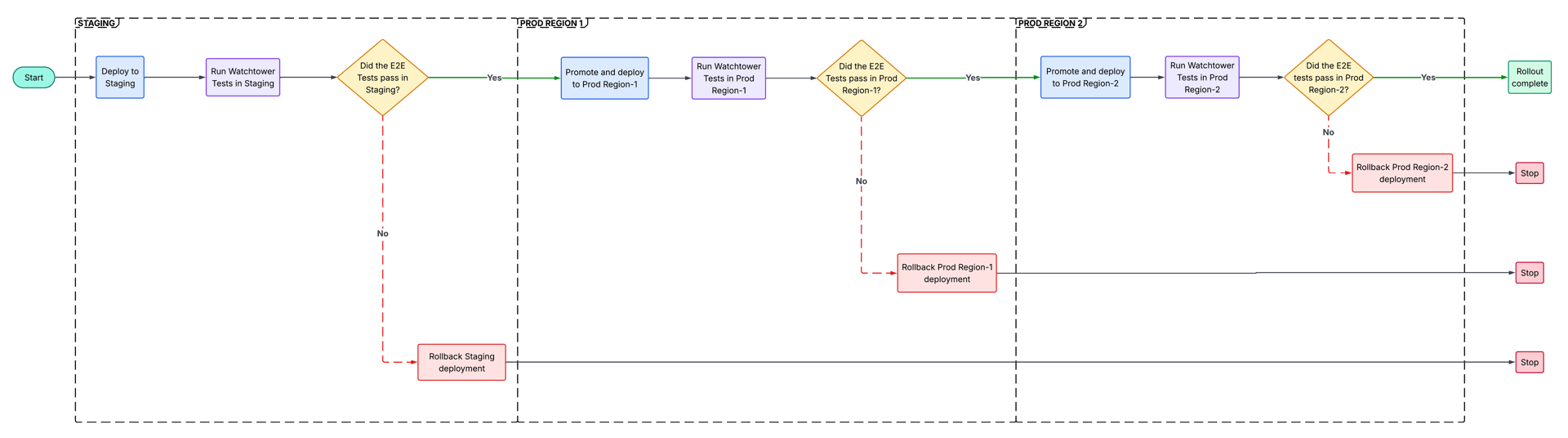
A failed journey no longer requires an operator to correlate test results, dashboards, and a deployment timeline before deciding whether to continue. The rollout system has a direct signal on journey health, not just service health: if the relevant journey is unhealthy, the deployment does not advance. That creates a clearer and more repeatable decision point for teams shipping changes, especially during high-pressure rollouts where ambiguity can slow down response.
That covers active rollouts. But production can degrade between deployments too.
Production Never Sits Still
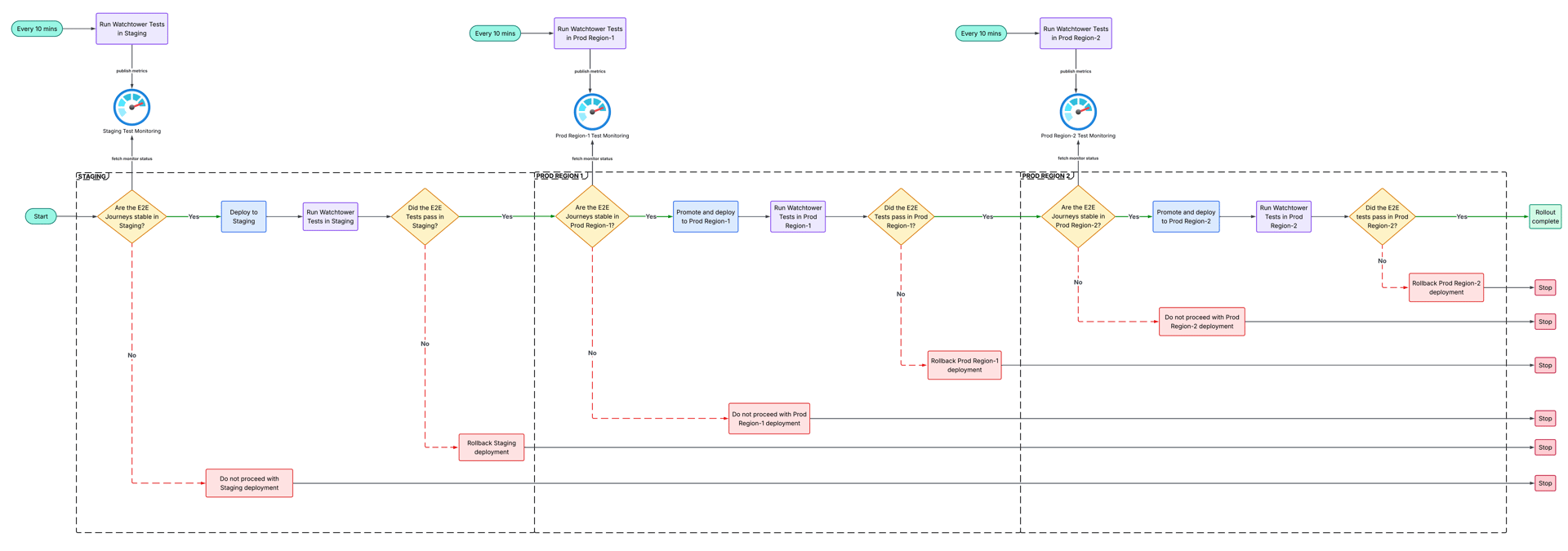
Production systems can drift independently of deployments. Dependencies evolve, configurations drift, and systems behave differently over time. A journey that was healthy when a deployment landed can degrade without any new change touching it.
That is why Watchtower runs on a regular cadence outside of deployment activity. Critical journeys execute against staging and production environments continuously, so we can detect journey degradation even when no active rollout is in progress. These scheduled runs surface degradation before additional changes continue shipping into an already unhealthy environment. This only works if the tests themselves remain highly reliable, which is why Watchtower intentionally focuses on curated, high-signal journeys rather than attempting exhaustive coverage across every possible scenario.
Earning Trust in the Signal
It would be easy to frame Watchtower as purely a technical solution: build the tests, wire them into the deployment pipeline, and the problem is solved.
But the platform only works because we agree to act on the result. If we bypass the gate whenever a deployment feels urgent, it stops being a gate. If failures are dismissed as flaky without investigation, the signal loses meaning. If scheduled runs become background noise, the system turns into theater.
In a recent 30-day window, Watchtower executed ~16,000 scheduled and deployment-triggered journey runs across staging and production environments, maintaining a 99.8% overall success rate. The 0.2% represented real journey regressions, several of which aligned with degradation we were already observing during incidents.
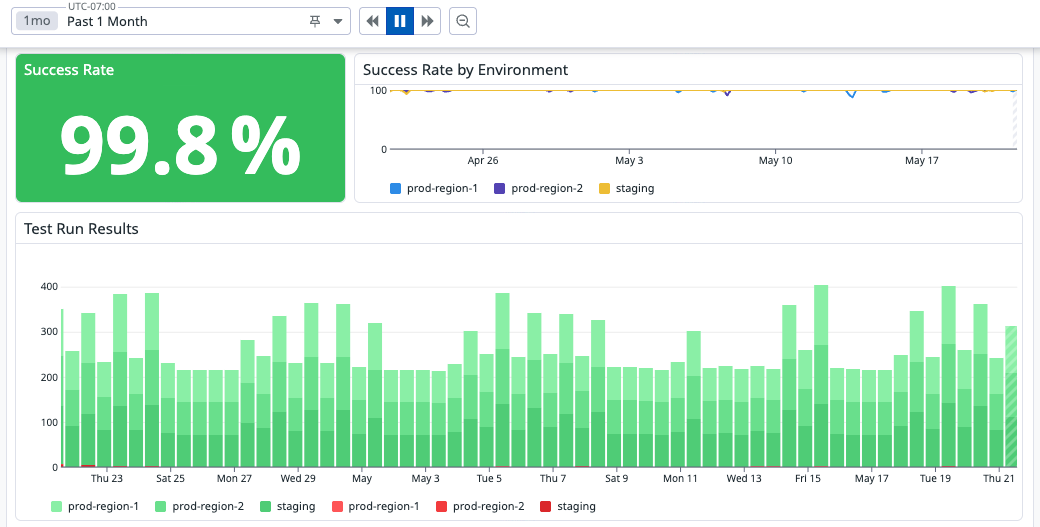
That reliability matters because a deployment gate is only useful if teams trust the signal. A noisy or flaky gate quickly becomes something teams work around; a high-signal gate becomes part of how we make rollout decisions. It also matters because of what the signal protects: over the same 30-day window, the event-to-notification journey — one of our most critical end-to-end flows — has held four-nines reliability, with events accepted at 99.9993% and notifications delivered at 99.9974%, both above our 99.99% SLO target.
Hitting that reliability bar was not free. It required disciplined journey selection, including declining or reshaping proposed tests that would not have held that bar. It required sustained investment in flake reduction and stable per-run infrastructure, including pre-provisioned, isolated test resources for each run so that parallel executions never interfere with each other. And it required team ownership norms that treat a failed journey like a failed build rather than a ticket to triage later. The value comes from the combination: trustworthy tests, clear failure handling, and operational discipline around acting on those failures when they occur.
What This Means for Teams Shipping Changes
For PagerDuty engineers, Watchtower is part of the normal deployment path rather than another dashboard to remember. The main shift is not one more signal to check manually; it is that critical customer journeys now participate directly in the rollout decision.
For teams writing journeys, the larger change is in how we think about ownership. The question is not only whether a service appears healthy independently, but whether users can still complete the journeys that depend on that service. A team changing alert grouping, webhooks, escalation behavior, or incident lifecycle APIs can encode the expected customer journey once and then rely on Watchtower to validate it consistently during rollouts and scheduled runs.
That changes how teams think about testing. Journey authoring often exposes implicit dependencies: which data must exist, which downstream systems are involved, which SLAs matter, and which user-visible outcomes define success. It also gives us a common language for release safety. Instead of asking only, “Is my service healthy?”, we can ask, “Is the customer journey still healthy?”
What We’re Holding Ourselves To
The August 28 incident still comes up in conversations about how we ship software, not because it was the only reason for this work, but because it made the lesson concrete:
Service health and journey health are different signals. Rollout systems need a way to account for both.
Watchtower is not a guarantee that nothing will ever break. Nothing is. What it gives us is a stronger mechanism for keeping the journeys users depend on at the center of rollout decisions, not at the periphery of them.
That means investigating when scheduled validation surfaces degradation, not shipping more change into an unhealthy environment. It means treating a failed deployment gate as a signal to understand before retrying, not a step to work around.
That is the bar we hold ourselves to — that PagerDuty works when our customers need it most.
