
- PagerDuty /
- Engineering Blog /
- PagerDuty’s Approach to Reliability
Engineering Blog
PagerDuty’s Approach to Reliability
by PagerDuty Engineering
June 1, 2026
| 11 min read
For sixteen years, we’ve built and operated the platform that teams depend on when operational clarity and incident response capability matter most. Today, our platform processes over 23 billion events per year, including traffic for more than two-thirds of the Fortune 500. That responsibility comes with a particular kind of accountability: we don’t get to be the system that was *also* having a bad day. Our customers don’t care about the reason a notification was delayed. They care that, in the moment they needed it the most, it worked.
So we hold ourselves to a hard line. Any notification that takes more than five minutes to deliver, or any time we spend unavailable, counts against our SLA. No carve-outs. Not for maintenance windows. Not for “scheduled” anything. A scheduled outage is still an outage to the on-call engineer who didn’t get paged.
That standard is easier to write down than to live by, especially when you’re shipping hundreds of deployments a day across a distributed platform. This post is about some of the practices we’ve built to make it possible, and to keep raising the bar as the industry around us changes.
These practices weren’t designed in a vacuum. They were built, and in some cases rebuilt, in response to real failures we’ve had in the past.
Several incidents last year highlighted gaps in our blast-radius controls and rollback speed. We treated those as forcing functions, not footnotes.
We made reliability our company’s top priority, what we called OKR 0, above any new feature or growth initiative. We deliberately prioritized reliability investments, giving teams room to strengthen foundational systems rather than continuing to build on top of them. We ship 600+ production changes per week. Maintaining that velocity at our scale without the right controls is how a bad deployment turns into an extended outage. The practices below are how we’re making sure each of those changes lands safely, and can be unwound quickly if it doesn’t.
The five practices that help us hold the line
These aren’t theoretical. Each one exists because we learned, the hard way, what happens when it isn’t there.
1. Graduated rollouts
The single most important thing you can do to limit the blast radius of a bad change is to make sure a bad change never reaches everyone at once. Every production change at PagerDuty moves through a graduated rollout: canary first, then progressive exposure, with feature flags, service and regional isolation as additional safety layers.
Concretely, that means our US and EU service regions are treated as independent deployment surfaces. A change that ships to one doesn’t automatically ship to the other. If something starts going wrong in canary, the rollout halts before it ever reaches the broader fleet, let alone the other region. Every production change is built to be unwound in minutes, not hours.
This sounds obvious until you’re the team under pressure to push a hotfix globally because something feels urgent. The discipline is in saying no to “just this once” because “just this once” is how single-region issues become global outages.
Earlier this year we ran a coordinated adoption campaign across the engineering org, supported by engineers embedded in each product team to drive adoption and surface blockers early. Completion was enforced and teams that weren’t done were blocked from shipping to production until they were. By late April, all engineering teams were compliant. The policy isn’t aspirational at this point. It’s enforced in the tooling.
2. Watchtower (end-to-end testing)
Service-level monitoring tells you whether your individual services are healthy. It doesn’t tell you whether your customers can actually accomplish what they came to do. Those are different questions, and answering only the first one is how you ship a deployment that passes every dashboard and still breaks a critical customer journey.
Watchtower is our end-to-end testing platform for critical API and UI journeys. Instead of asking “is this service responding?”, it asks “can a customer hit the Events API, have an incident created, and receive a notification within SLA right now, in production?” It runs the same flows our customers run, against the real environments those customers depend on, using controlled test resources rather than mocked-out systems. A passing Watchtower run is evidence that the actual journey completed end-to-end, not a simulation that suggested it should have.
Two things make Watchtower more than just another test suite. First, it gates deployments: a failing journey test halts the rollout at its current stage and forces investigation before any retry. Second, it runs continuously between deployments, because production drifts even when no one is shipping, dependencies evolve, configurations change, and a journey that was healthy yesterday can quietly degrade today. Continuous validation surfaces that drift before the next deployment turns a quiet degradation into a loud one.
We’ll be writing about Watchtower in more depth in a separate post soon, including how we earn trust in the signal itself, since a noisy or unstable gate is worse than no gate at all.
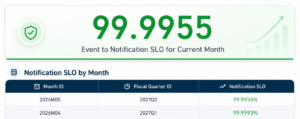
3. Service Level Objectives
We run our platform against explicit SLOs, measurable definitions of what “working” actually means, expressed as percentages over rolling windows rather than vibes. The most important of these is on our core Event-to-Notification pipeline, which is the thing that when it stops, stops everything that matters.
SLOs do two things that no amount of “we’ll be careful” can replicate. First, they convert reliability from a culture statement into a number that either is or isn’t where it needs to be. Second, they create error budgets, a finite allowance for unreliability that, when consumed, becomes a forcing function to drive corrective action. Burn through the budget and the conversation stops being about new features and starts being about fixing what’s broken. That tradeoff is uncomfortable by design.
Our target is 99.99% availability over any rolling 30-day window, measured against real end-to-end delivery with no carve-outs for infrastructure, maintenance, or dependency failures.
Getting to a number we trusted took work. We mapped every service and dependency in the pipeline before we could measure it accurately. You can’t set a meaningful SLO on a system you haven’t fully charted.
4. SDLC management and enforcement
Reliability that depends on individuals remembering to do the right thing isn’t reliability. It’s luck wearing a lanyard.
We’ve codified our software development lifecycle so the safe path is the default path: required deployment gating, mandatory rollback procedures, test coverage thresholds, and approved-source enforcement for dependencies. When a change moves through CI/CD, the pipeline itself enforces the standards. Engineers don’t have to remember to apply them, and they can’t accidentally skip them under pressure.
This matters more as teams change. People rotate. Services change hands. The institutional memory of “oh, you have to be careful with this one because…” fades. Codifying standards into the pipeline is how you survive your own org chart.
One thing that makes codified standards actually work is knowing which services need to meet which standards. You can’t apply graduated pressure without a map.
We built a service tiering system that classifies every service by its role in the Event-to-Notification path, its blast-radius risk, and its downstream dependencies. Tier 1 services carry the strictest requirements: tightest deployment gating, highest test coverage thresholds, mandatory rollback procedures. Lower tiers have proportionally lighter requirements so engineering investment goes where it matters most.
The tiering exercise itself was revealing. It surfaced services whose owners didn’t know they sat in a critical path, dependencies that had never been written down, and blast-radius assumptions that turned out to be wrong. Getting the map right before enforcing standards was worth every hour it took. Tiers will now be reevaluated multiple times per year as system dynamics change to ensure we continue to reflect reality.
5. Change failure rate tracking
If you can’t measure how often your changes break things, you can’t tell whether anything you’re doing is actually working.
Change failure rate, the percentage of production changes that result in degraded service or require remediation, is one of the cleanest signals you can get about engineering health. We track CFR across our services and trend it deliberately downward. When a service’s CFR ticks up, that’s a signal that something has changed: process, ownership, complexity, dependencies. It’s a signal we’d much rather catch in a dashboard than in a major incident review. A change does not need to consume error budget or cause an SLO violation to be considered a failed change. If a deployment requires corrective action, rollback, hotfixes, or other unplanned remediation to achieve its intended outcome, we count that as a failure. This allows us to identify and reduce operational friction long before it becomes visible to customers.
Why these five, and not others
Each of these practices answers a different question, and that’s the point. Graduated rollouts limit how far a bad change can spread. Watchtower asks whether the customer journey actually worked. SLOs convert “are we doing okay?” into a number with consequences. Codified SDLC controls make the safe path the default path, so reliability doesn’t depend on folklore and campfire stories. CFR tells us whether any of the above is actually working over time.
Take any one of them away and the others have a blind spot. Healthy services with broken journeys still page your customers. Healthy journeys with no rollout discipline still produce global outages. Disciplined rollouts with no SLO have no forcing function when reliability slips. SLOs with no measurement of change failure rate can’t tell you whether the slip is one bad week or a trend.
Every one of these practices exists because we’ve felt the absence of it, and because our customers have too. We’ve had the rollback that didn’t roll back cleanly. We’ve had the deployment that looked clean on every dashboard and still broke a customer journey. We’ve had the tribal knowledge that walked out the door with the engineer who held it. Every public post-mortem on our status page is a receipt and the practices above are what we’ve built to make sure the next post-mortem isn’t a rerun of the last one.
The AI era raises the bar for everyone
The industry is moving fast toward agentic software delivery. AI systems write, review, and ship code at a pace humans can’t match. That’s exciting, and it’s also a reliability problem hiding inside a productivity story. When the rate of change goes up, the rate of unintended change goes up with it. The safety nets that worked at human pace will be tested at machine pace.
Which means the practices above aren’t a moat we’re trying to preserve. They’re a baseline the whole industry needs to raise. Graduated rollouts matter more when changes happen faster. SLOs matter more when humans aren’t the ones reading every diff. CFR matters more when the volume of changes makes it impossible to inspect each one. Codified SDLC controls matter more when the entity proposing the change might be an agent, not a person.
We’re investing accordingly. As AI accelerates how software gets built, we’re doubling down on the controls that let software get operated safely. We’re also applying AI to the operational side of the equation through systems such as our SRE agent, helping engineers triage, diagnose, and resolve production issues faster. Not because AI is a replacement for operational discipline, but because reliability has always been about what happens after the code merges, and that isn’t changing.
What’s next
The foundations are in place. The remaining work is about coverage, depth, closing the last gaps, moving validation earlier in the pipeline, tightening isolation between workloads, and ensuring our SDLC standards apply uniformly across every service.
Reliability is earned in increments, not announced in milestones. We’re being transparent about where we are because “here’s what’s done, here’s what’s in progress, here’s what’s still hard” is more useful than a summary that makes everything sound finished.
What this means if you’re a customer
You should expect a few things from us, consistently:
- Our SLA means what it says. Five minutes is five minutes. Maintenance windows don’t reset the clock. Scheduled maintenance is for cars, not critical services/infrastructure.
- When we have an incident, you’ll see it on the status page within minutes. Not because we’re proud of incidents, but because we own them. Public post-mortems are part of how we work.
- We’d rather be slow and right than fast and sorry. If our SDLC controls are telling us a change isn’t ready, the change waits.
PagerDuty’s reliability practices are an ongoing investment, not a finished project. If you want to go deeper on any of the practices above, we publish public post-mortems on our status page and detailed engineering follow-ups for major incidents.
