
- PagerDuty /
- Blog /
- Incident Management & Response /
- 3 Easy Steps to Suppressing Alert Noise
Blog
3 Easy Steps to Suppressing Alert Noise
by David Cooper
April 17, 2017
| 3 min read
For many of our customers, reducing alert noise is a difficult, yet rewarding task. Cleaning up your alerting means fewer late night pages and happier team members. But this task can feel a lot like yak shaving if you don’t have the proper tools.
In this post, I’m going to run through an effective workflow that will allow you to identify these noisy, non-actionable alerts, and do something about them. You’ll be able to easily control what notifies your team, without having to mess around with upstream tool configurations.
1. Get a holistic view and identify noisy alerts
First, you need a holistic, live view of your alerting infrastructure. To truly understand service dependencies, alerting behavior, as well as the impact of any outage, you need a visualization in which you can easily grok thousands of data points.
Our Infrastructure Health Application, which lives within our Operations Command Console, does just this. Think of it as the ultimate timeline, where you can spot those noisy, redundant alerts that are continually paging your team.
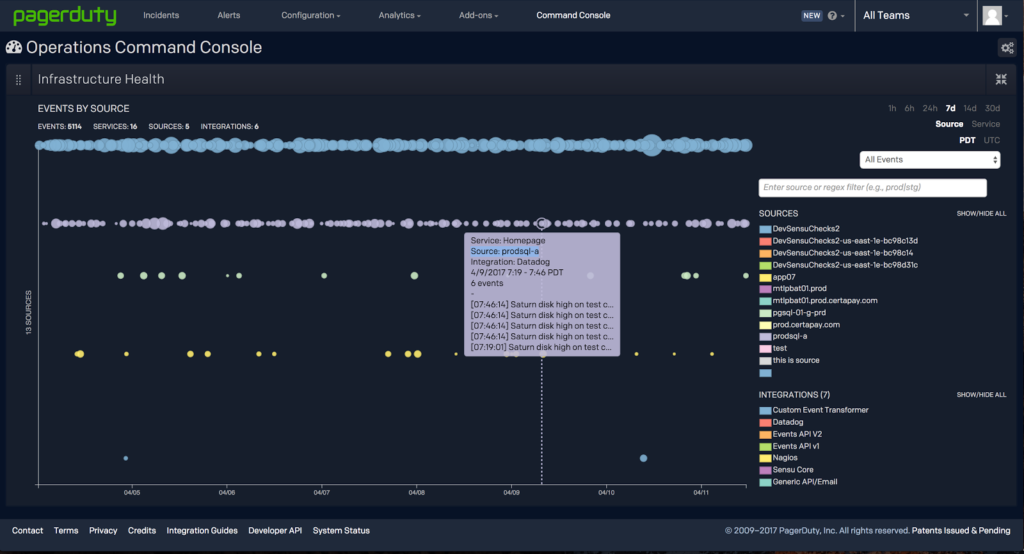
2. Learn more about these alerts
Where do they come from? What is their severity?
After identifying a noisy source, you can glean more information about it by diving into our new Alerts Table. Here you can search, sort, and filter through alerts across your entire infrastructure. These alerts have also all been automatically normalized via the Events API v2, making it really easy to find all the right information without needing to memorize schemas across different vendors. In my example, I can see that alerts coming from source prodsql-a all have Severity = Info. These are informational alerts and really shouldn’t be paging my team.
3. Take action and suppress
Because I’ve spotted informational alerts that shouldn’t be paging my team, I’m going to use PagerDuty’s Event Rules Engine to suppress these informational alerts. Event rules within PagerDuty span multiple integrations, which is great because I don’t need to change any configurations in my upstream monitoring tools, saving me time.
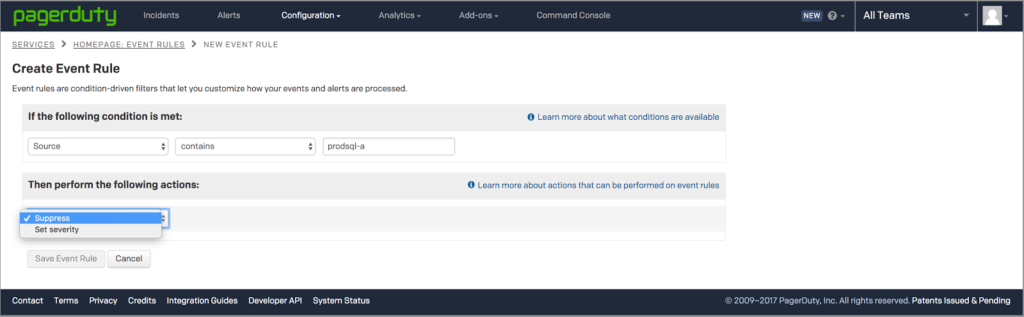
Voilà, I have successfully identified a non-actionable alert and created an event rule to suppress it. Now, these types of alerts will no longer page me, but all of that data still exists and is visualized within PagerDuty, so I can get a truly holistic view of my infrastructure at all times.
Finding the right balance of alert suppression is just as much an art as a science. However, the more information you have and less obscure your alerting infrastructure is, the better the chances you have of focusing on what matters, missing less of the important stuff, and ultimately being successful. At PagerDuty, we equip you with the solutions needed to understand, learn, and intelligently take action on infrastructure events. We’re proud to empower amazing development and operations teams to manage their services in production with ease.
For more information on these solutions, check out our latest release of capabilities designed for developers.

