
- PagerDuty /
- Blog /
- Incident Management & Response /
- 6 Essential Steps to Reducing Incident Resolution Time
Blog
6 Essential Steps to Reducing Incident Resolution Time
by Michael Churchman
October 13, 2016
| 7 min read
What is Time to Resolution?
Time to resolution (TTR) or Mean time to resolution (MTTR) refers to the average length of time needed to resolve a customer service case or ticket once it’s been opened. When a customer or user reaches out to your team because of an issue they are experiencing with your service, it’s important to minimize MTTR in order to ensure the best possible experience with minimal downtime. For example, let’s say a customer calls in to report an issue they are having with your product. The TTR clock starts as soon as this interaction takes place, and stops once a resolution has been reached. The shorter the resolution time, the happier the customer.
TTR can be calculated for different employees and different incident categories in order to show trends as well as any possible areas for improvement. The goal should always be to minimize the amount of time needed to resolve an issue so customers are able to properly use your service with as little disruption as possible.
“How can we reduce incident resolution time? Our MTTR numbers are dragging us down!”
If you find yourself shouting this question at the sky, you’re hardly alone. It’s a chronic support problem. How do you reduce incident resolution time? As it turns out, there are some very effective and very sensible things that you can do. We’ll take a look at them in this post.
Metrics, Metrics, Metrics
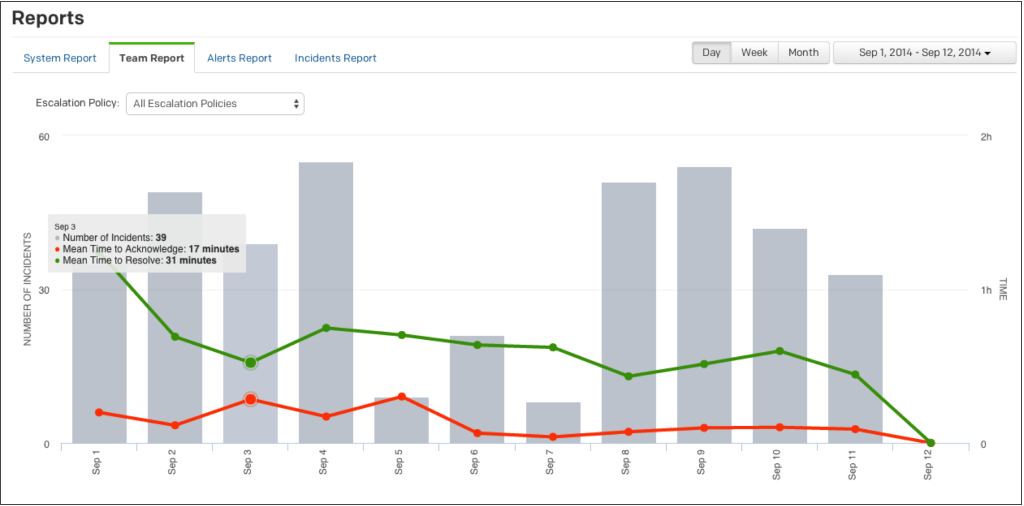 First and foremost, it’s important to understand the ways that metrics are used to gauge incident resolution and decide which aspects of those metrics matter most to you.
First and foremost, it’s important to understand the ways that metrics are used to gauge incident resolution and decide which aspects of those metrics matter most to you.
The most basic metric for resolution time, of course, is MTTR (Mean Time to Resolution). It’s one of those metrics that upper management tends to like because it condenses everything into a nice, simple number. Unfortunately, it’s also one of those numbers which can turn out to be too simple, squeezing out important information, and leaving only a near-meaningless average.
Overall MTTR (covering response to all incidents) is a reliable metric if the data isn’t influenced by too many outliers, and if it is based on a broad spectrum of incidents which fit nicely under a bell-shaped curve. If, however, there exists two distinct sets of incidents, representing two different kinds of problems with very different resolution times, MTTR can be misleading. Since broad, bell-shaped curves often include anomalous outliers, the overall, system-wide MTTR may not be a good metric at all.
If you do have a choice when it comes to metrics, what are the alternatives to overall MTTR? Here are some recommendations:
- Separate MTTRs for Each Class of Incident: If you can define specific classes of incidents, you can use separate MTTRs for each class. This can be very helpful if the incidents involved naturally divide into distinct classes. But don’t give into the temptation to devise incident classes artificially just so you can have some good MTTR numbers to show at the next meeting.
- Percentage Resolved: You can also look at the percentage resolved within a target time or the percentage unresolved after a set time limit. This allows you to measure resolution time against a goal, and to adjust incident-management practices in order to meet that goal.
- Total Number of Incidents & Cumulative Incident Time: In order for either MTTR or target resolution time numbers to make sense, however, you need to take into account the total number of incidents and the cumulative incident time for a given period. Why? Let’s take a look at Table A below. You have two different IT departments monitoring and measuring incidents in the same way. Based strictly on the percentage of incidents exceeding target time and MTTR and, IT Dept. B is the clear winner; when you don’t take into account the actual incident totals and cumulative times, it’s too easy to wind up comparing trash statistics.
Table A: Incident Management and MTTR
| IT Dept | # of incidents per month | # incidents exceeding target time | Cumulative incident time | % incidents exceeding target time |
MTTR |
| A | 3 | 1 | 4.5 hours | 33.33% | 1.5 hours |
| B | 35 | 10 | 26.25 hours | 28.57% | 0.75 hours |
Keep Your Numbers Down
How ever you measure resolution time though, the one constant is the need (usually accompanied by pressure from the C-suite) to keep that number down. What can you do?
There are several steps you can take and when done together can make a positive impact. Below are six essential steps you need to begin doing starting now:
- Use a fast and accurate incident management system.
A response starts with your Incident Management system. How does your response team receive alerts? Do they get phone calls and e-mail messages from end-users during regular office hours? That kind of system is OK for low-priority problems and feature requests. You need an automated incident system that will notify the appropriate response team leaders by using multi-channel global communication options (phone calls, SMS, email, or any other quick-response communication system) immediately when an incident is detected or reported. Incidents should be routed to the correct team leads to avoid any confusion or misunderstanding over who’s responsible for handling the incident. - Cut alert noise and filter non-alerts.
Filter and limit alert noise right from the start, so that response teams are not tied up with low-priority incidents, or worse yet, non-incidents that weren’t filtered before dispatching. These functions should be built into your alert and dispatching system, and to a large degree, they can be automated. - Keep incident acknowledgement times short.
This involves both the alert system and the response teams. If there is no acknowledgement of an incident after a set (and very short) time, the incident should automatically roll over to a second team member, then to a third, etc. If none of the team members acknowledge the incident, it should roll over to a second team (or to IT management). Incidents should not be left hanging indefinitely, without acknowledgement. - Set priorities from the start.
Have a clear priority in place, based on such things as severity and extent of the incident, the systems affected, and their impact on company operations. This may have a mixed effect on your MTTR, but if you start with a clear understanding of which incidents need the most attention, and which can wait, you will reduce wasted time, and ultimately cut resolution time. - Use real-time collaboration.
Bring in specialty teams and support resources at crucial points during incident resolution if necessary. Real-time collaboration over the appropriate media (which can include VPN and live video, as well as text and voice) can mean the difference between a quick, on-the-spot resolution and waiting for an e-mail message the next business day. - Establish response teams with clear roles.
Incident response should never be ad-hoc. Each team should have a leader, and all team members should be clear about each other’s responsibilities. Communication, both within the team and across stakeholders outside the team, should be clear and open.
There are plenty of other steps you can implement to cut response time. For example, for larger organizations, a formal command system with incident drills may be appropriate. By following the guidelines listed above, however, you should be able to bring your IT team’s MTTR numbers down to something that won’t leave you shouting at the sky.

