
- PagerDuty /
- Blog /
- Integrations /
- PagerDuty + Atlassian: Taking Modern Incident Response in Stride
Blog
PagerDuty + Atlassian: Taking Modern Incident Response in Stride
by Dave Cliffe
May 31, 2018
| 5 min read
In order to meet rising customer demands and the expectation of “real time, all the time,” digital operations are changing the way people work. And one of the most interesting macro trends is seeing how that impacts not just your IT Operations and Development teams, but also how the entire business is becoming involved in raising the level of responsiveness to customers. For better or for worse, incident response is a great example of this—both because of the time pressure involved and the efforts across your organization (including Customer Support, Executives, Communications/Marketing, Sales, etc.) to formulate an effective response. Major incidents are a business problem, not a product problem. And good communication and collaboration are essential for modern incident response.
Atlassian gets this reality. In addition to our already rich set of integrations with JIRA, HipChat, and StatusPage, we are excited to announce the general availability of our PagerDuty Stride extension. Stride is the complete team communication solution, which is great for raising visibility across your team when a PagerDuty incident is triggered. But the best part is how Stride can help align your organization in times of crisis, such as during a major incident. In particular, it offers a great set of capabilities for Incident Commanders, Deputies, and Scribes to drive effective incident response. (Not familiar with Incident Command? Take a quick read through our best practices: https://response.pagerduty.com/.)
Here are a few of our favorite Stride capabilities for Incident Command.
The PagerDuty Stride Sidebar
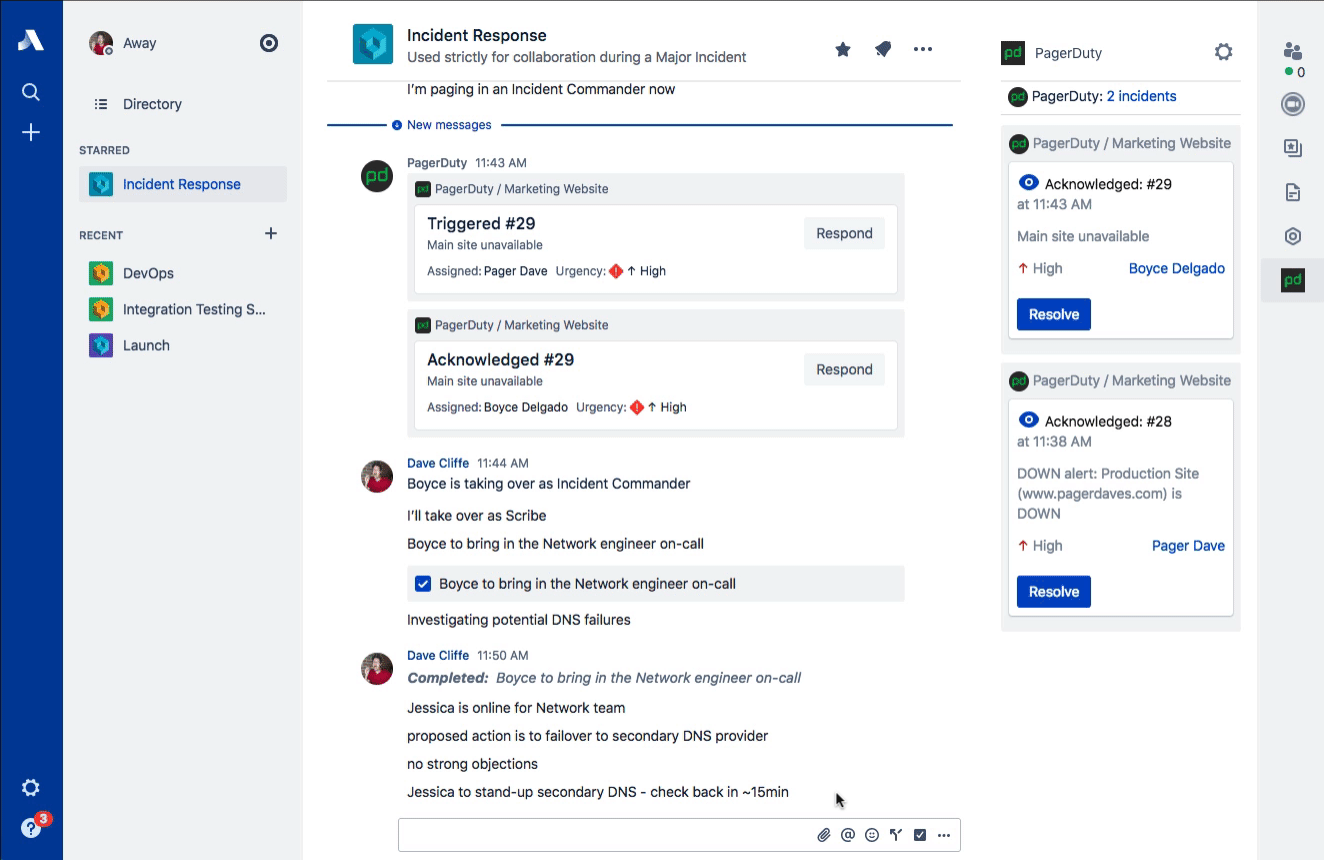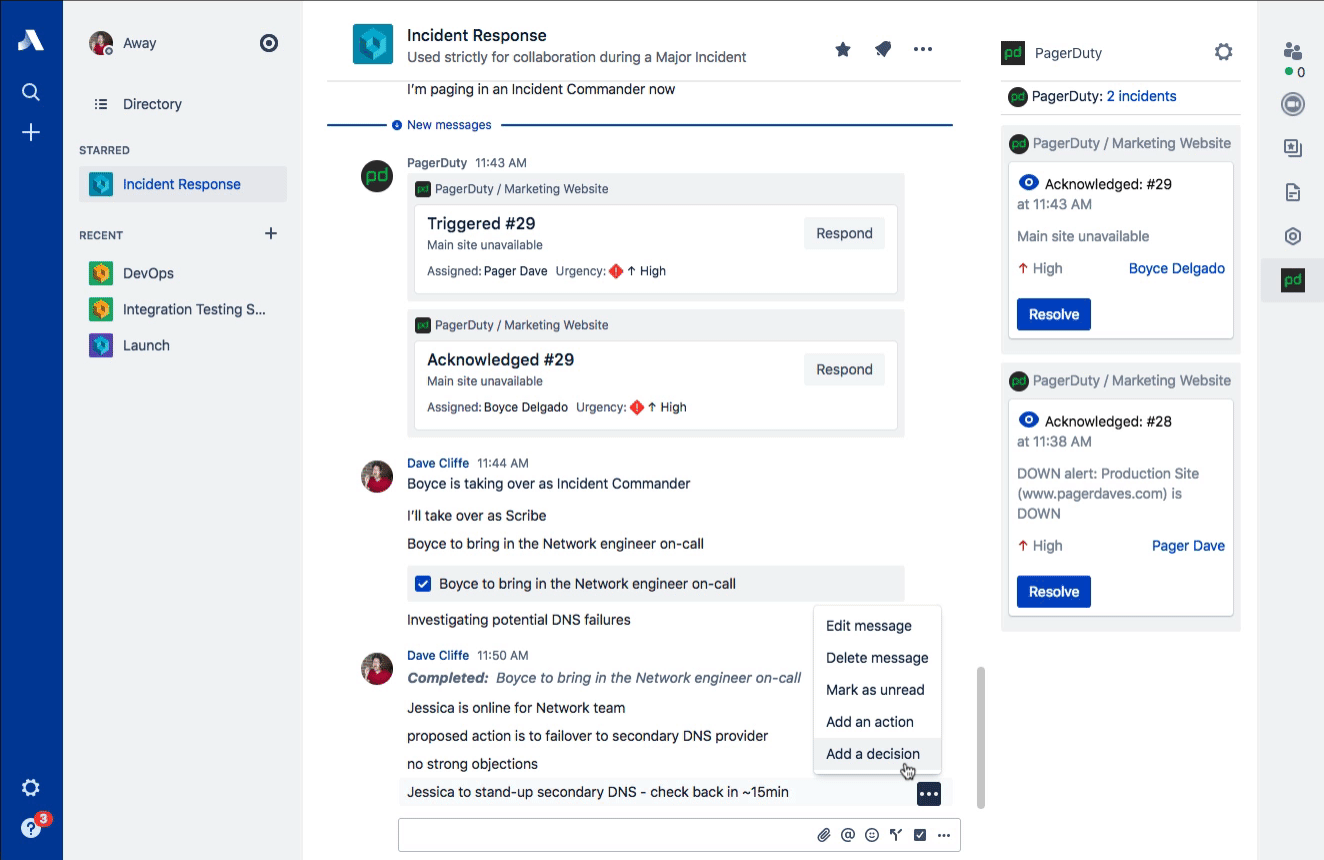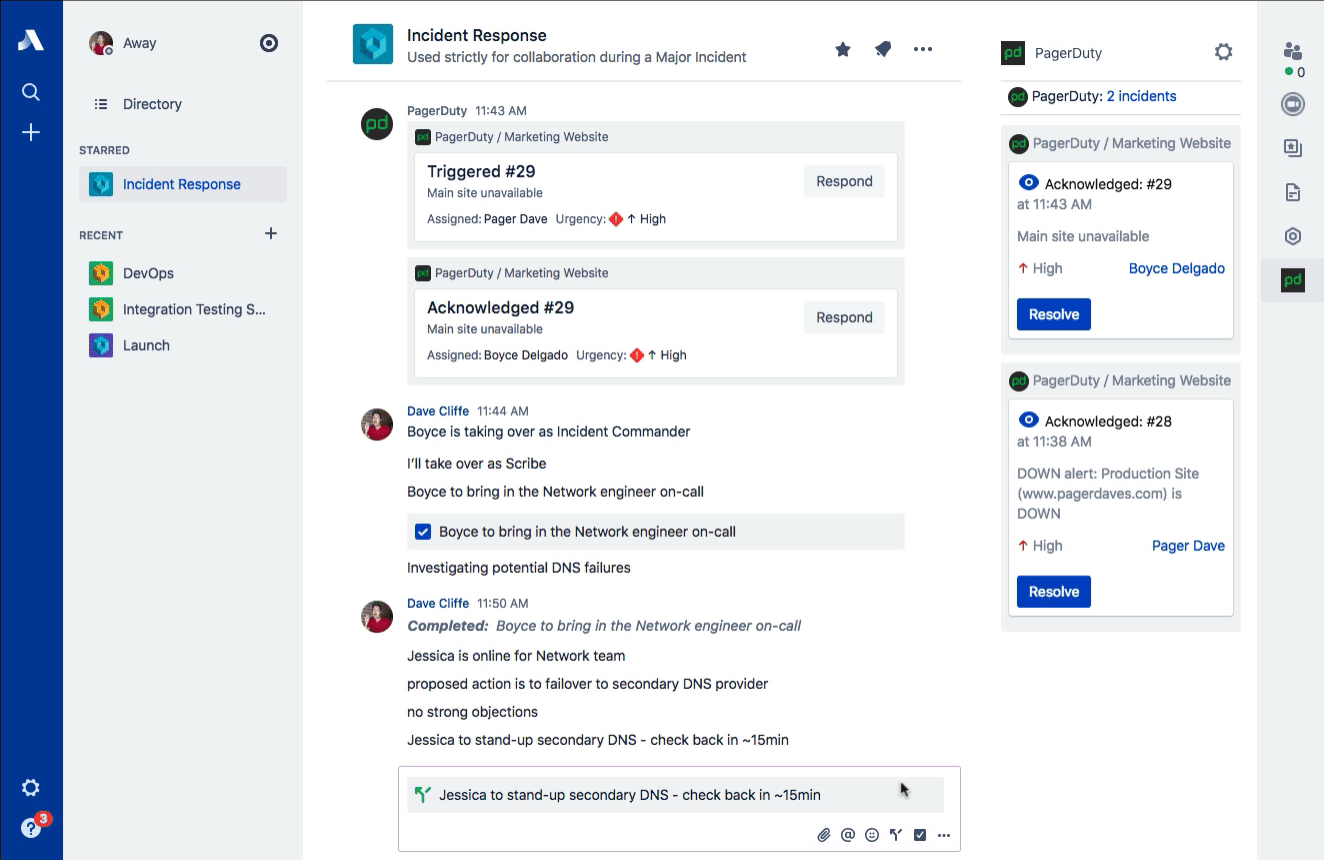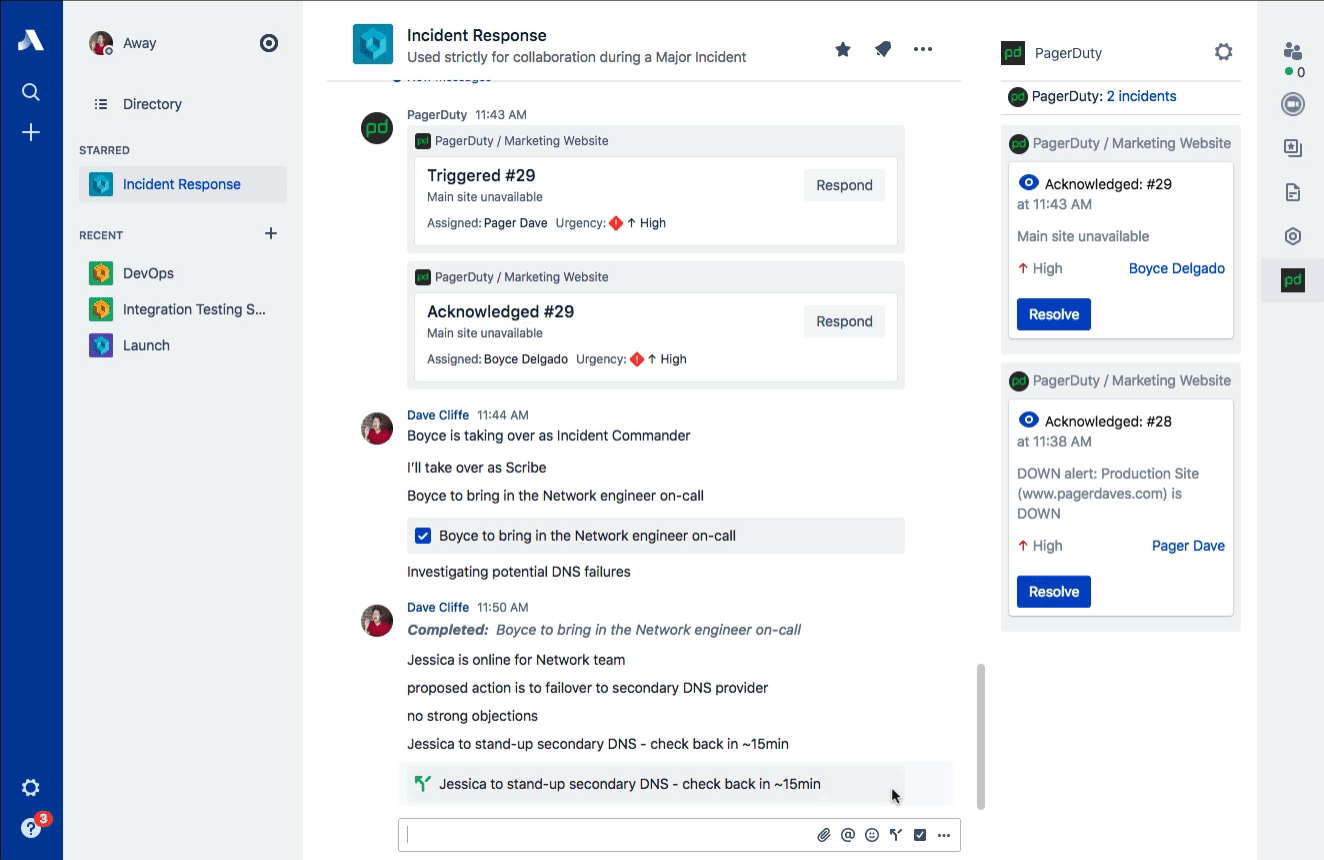
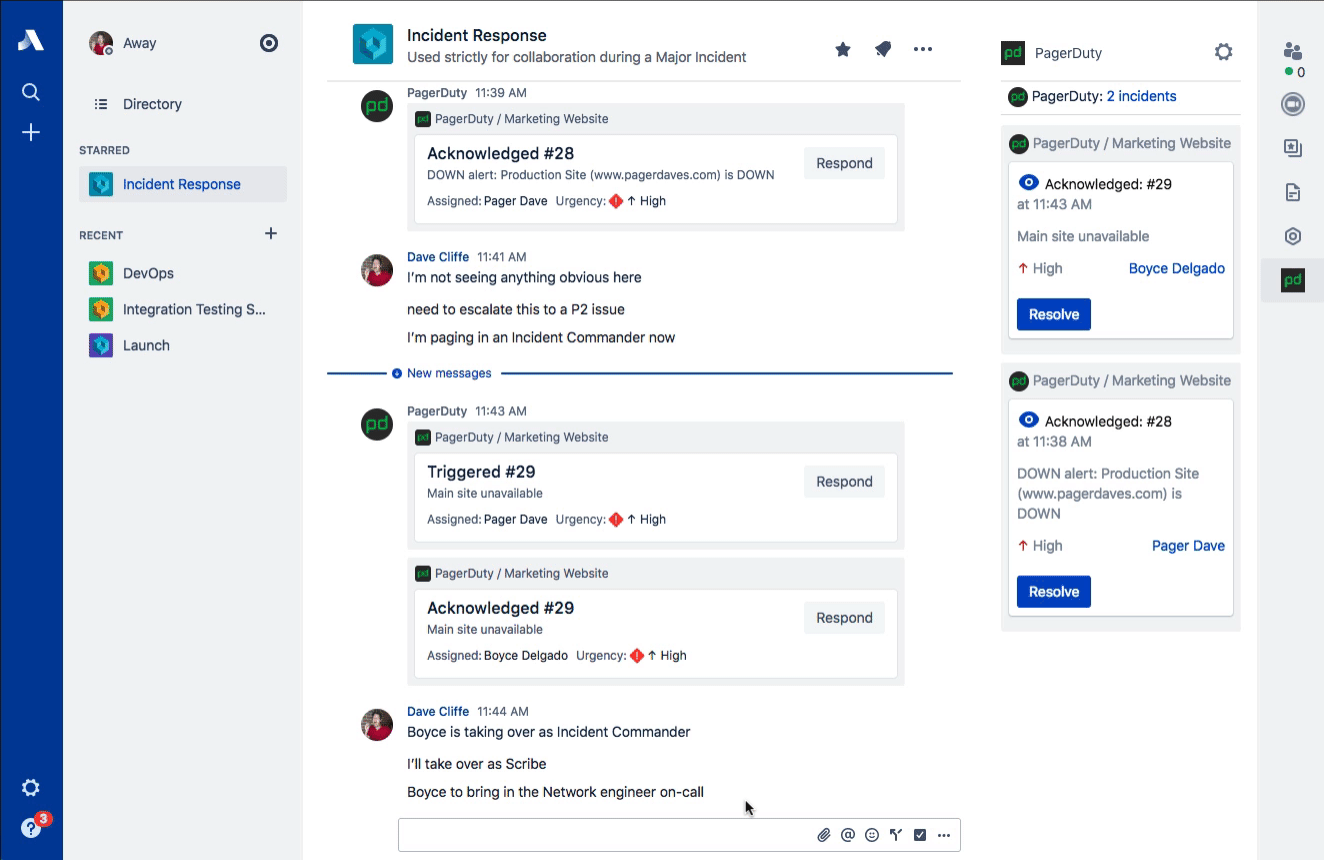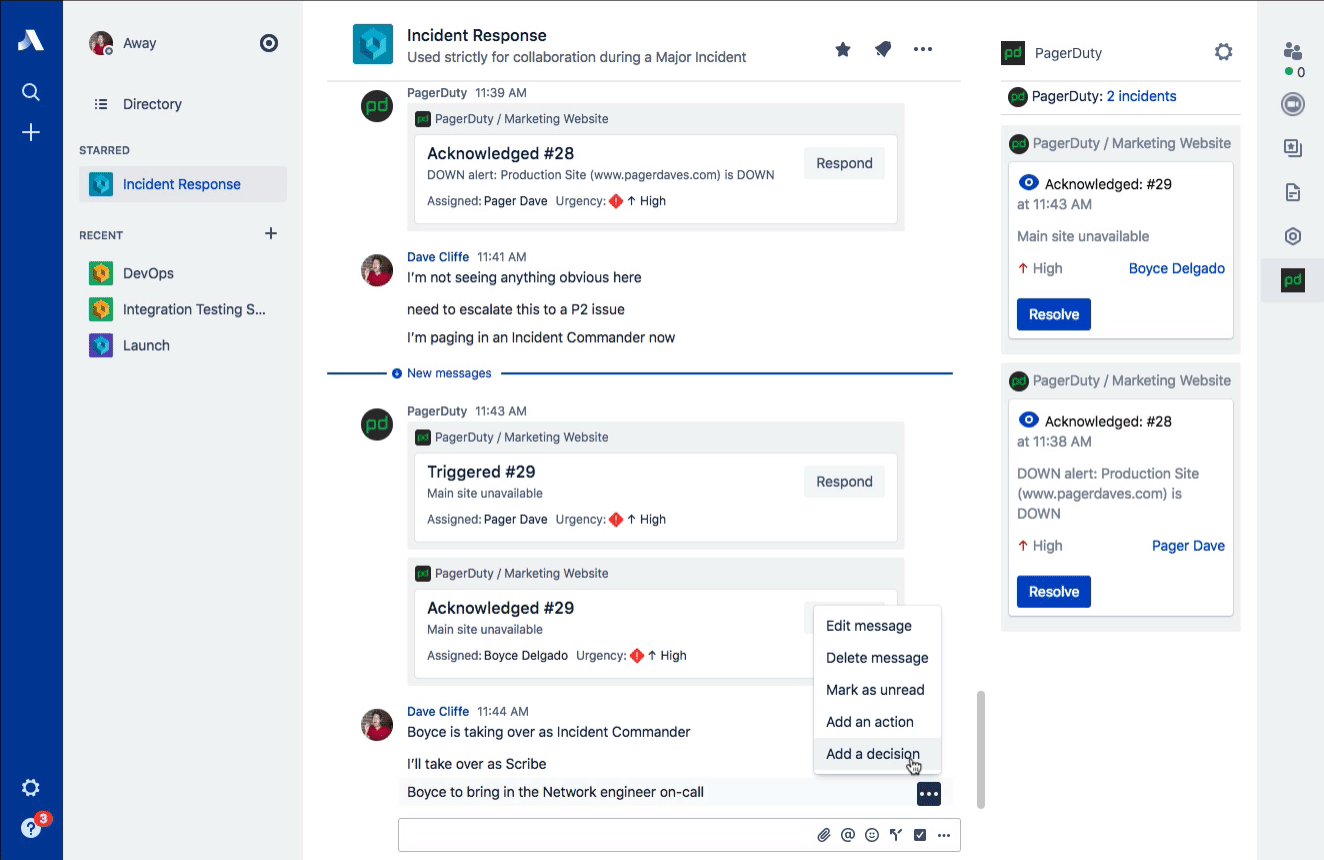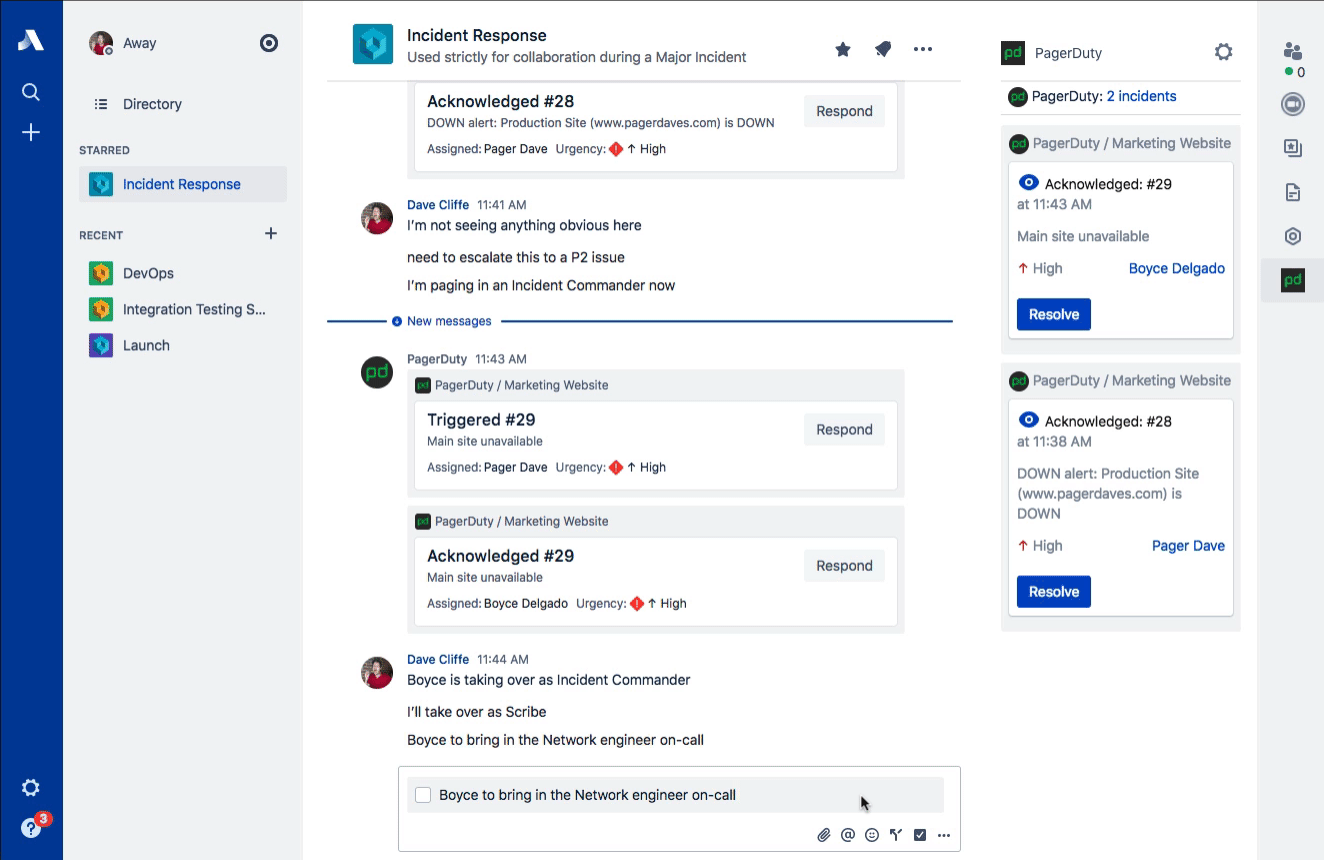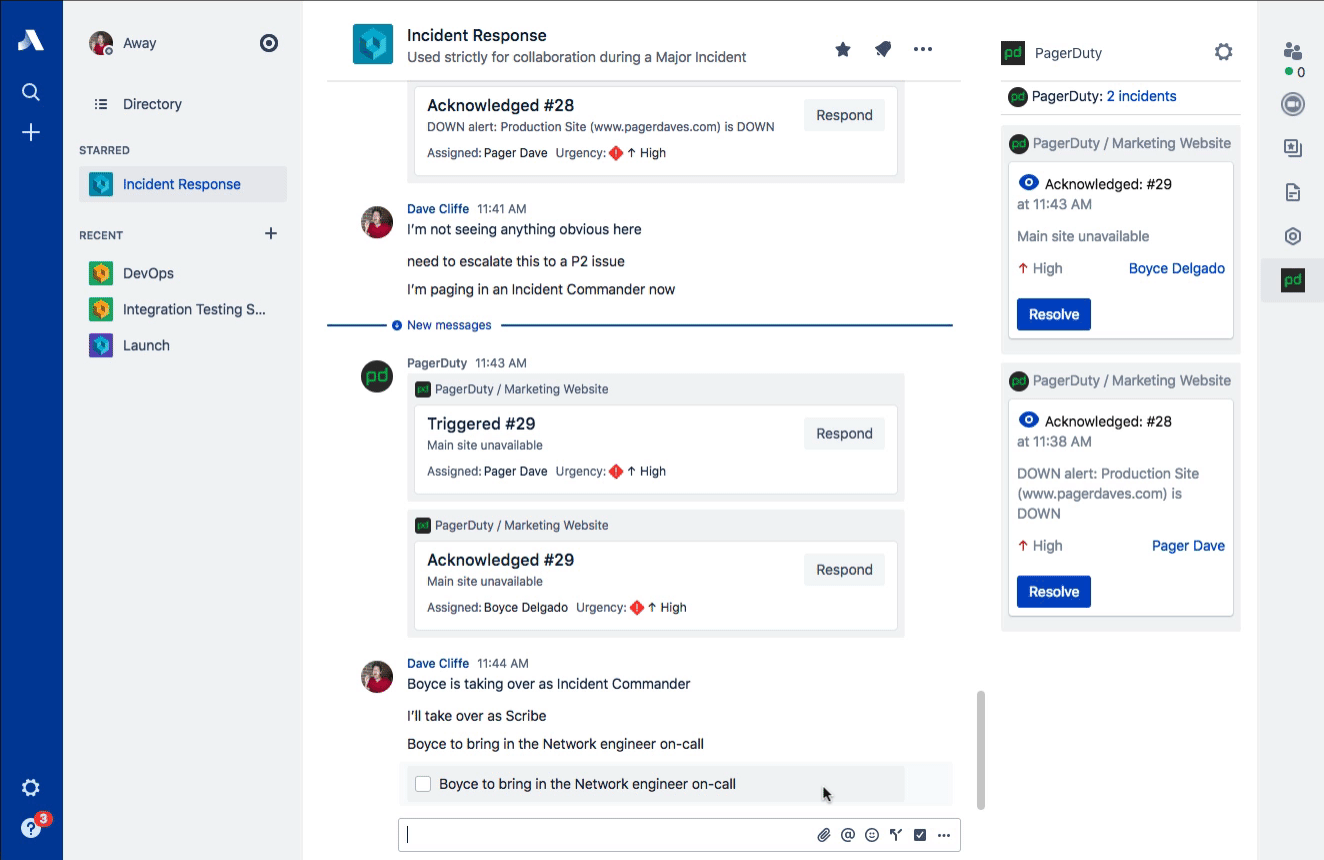
While PagerDuty has the honor of being associated with the origination of ChatOps (credit to GitHub), one of the most common ways that ChatOps gets abused is forcing new responders to read through the entire chat log in order to catch up on the details surrounding an incident. Stride’s sidebar provides a place to maintain a snapshot of the most relevant information about the incident. The verbose conversations related to the incident happen in the room, while the active incident in the sidebar contains a summary of impact, events, key decisions, and actions that have been taken.
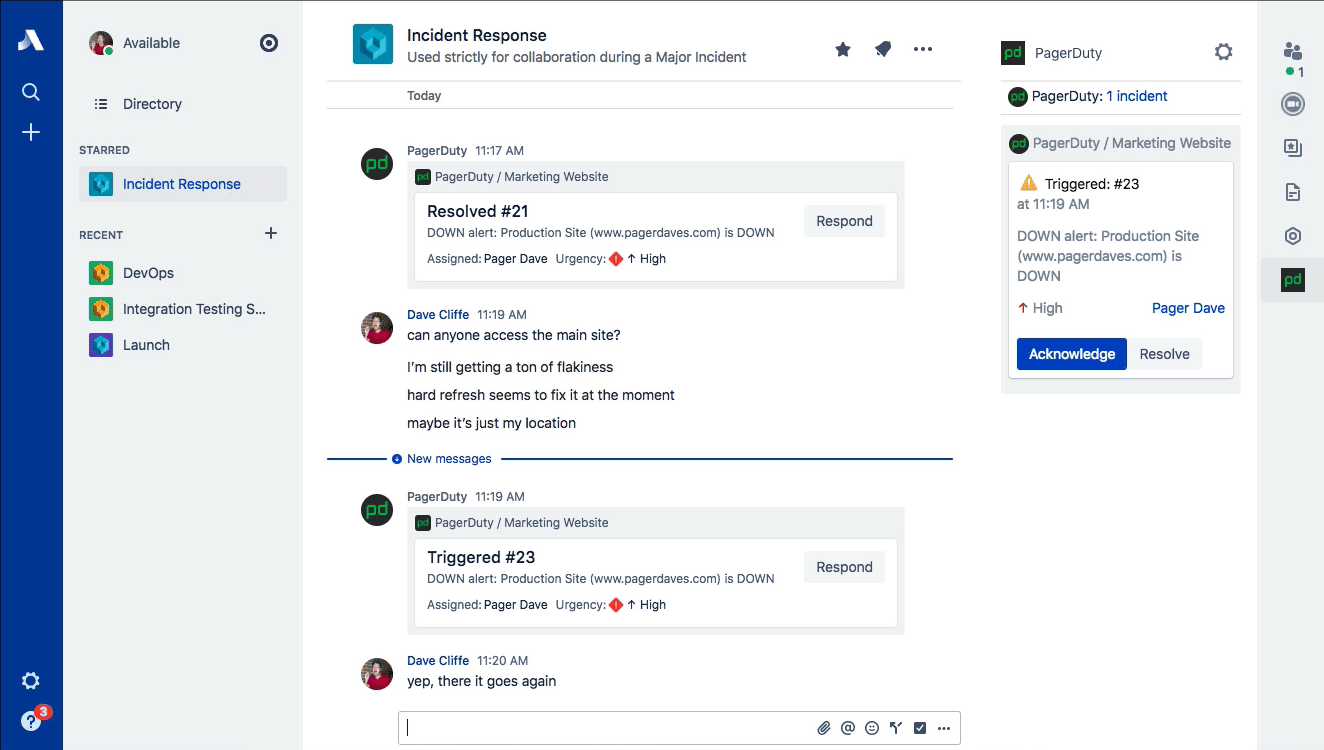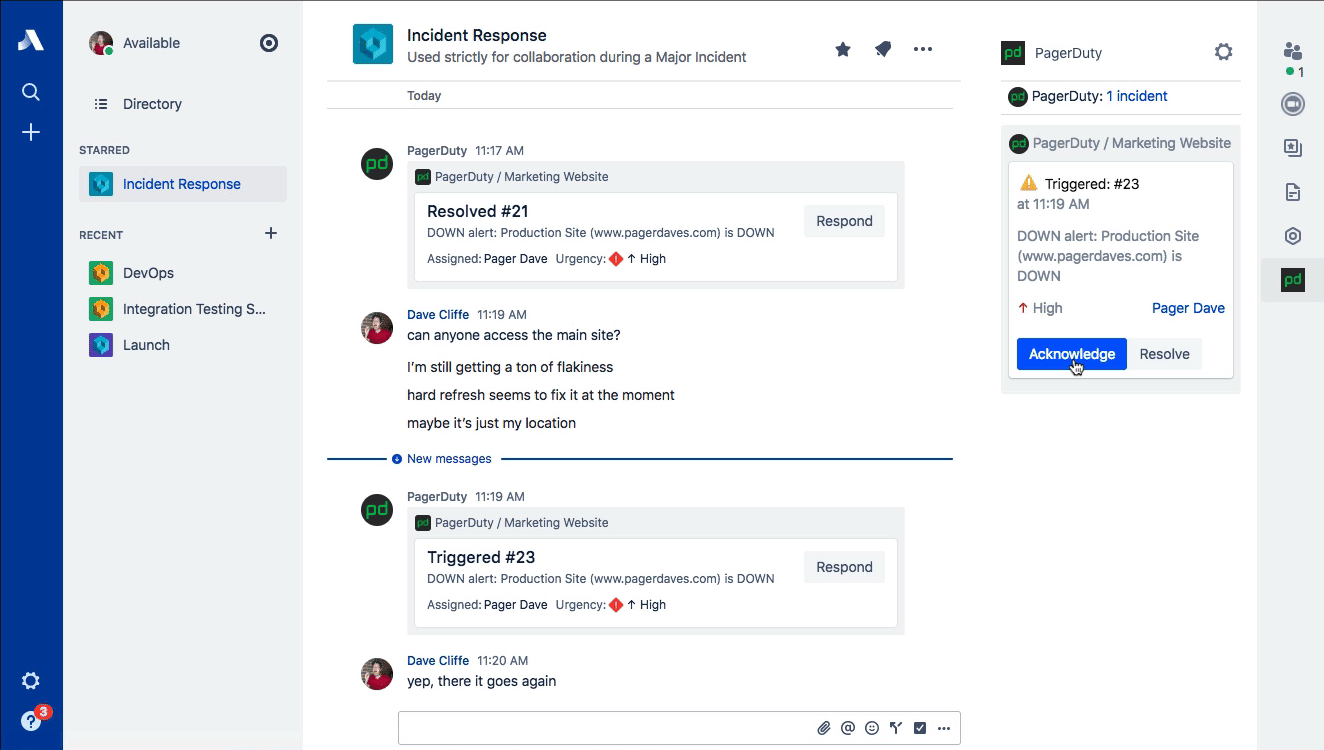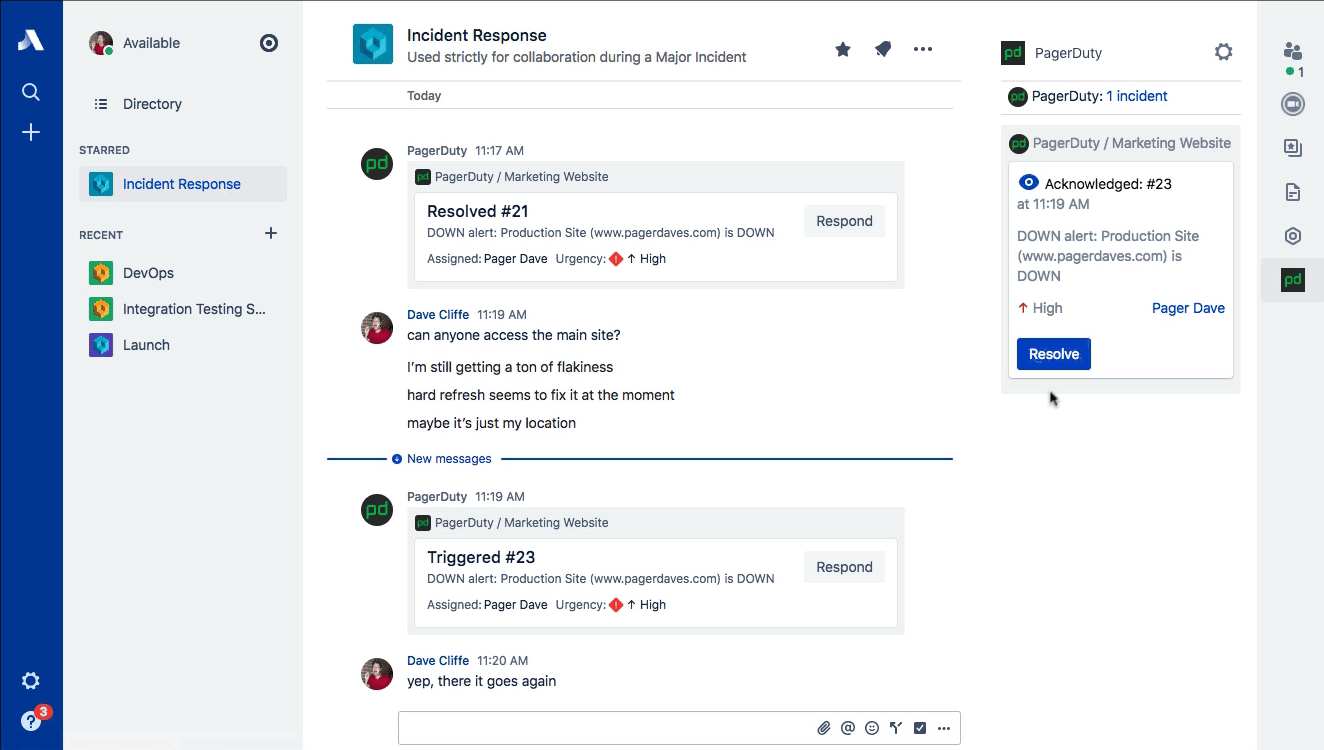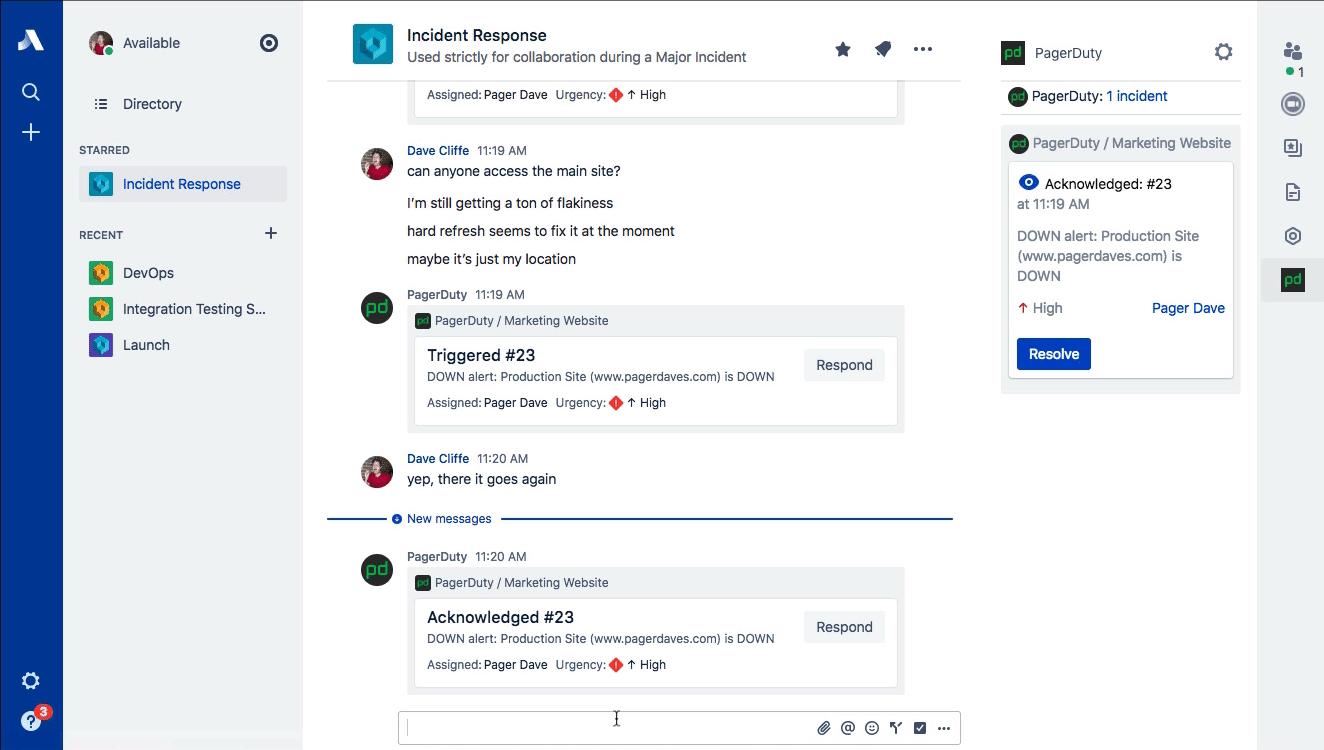
This type of information is exactly what the Scribe needs to be capturing and is perfect for both real-time catch-up and compiling the postmortem timeline later. Common ground is a key concept in communications and is especially important for incident response. Incident Commanders are also trained to do these kinds of summaries regularly (often verbally on the voice call) for the benefit of maintaining that common ground. Stop forcing people to “read the chat log” to get up to speed! (Dan Slimmon of Exosite has a fantastic talk from Velocity Santa Clara 2016 on this exact topic if you’re interested.)
Stride Decisions
One of the key principles of effective incident response is that all decision-making authority is given to the Incident Commander. This is particularly important during a major incident, where riskier decisions may be necessary in order to mitigate customer impact. One example that we use in our training: You wouldn’t typically restart all of your web servers at the same time as that would incur downtime, but when all of your customers are already impacted in some other way, opting for that over a rolling restart might be the right call.
Stride Decisions makes it easy to record those hard decisions in-line as the response is being scribed. These sorts of decision points are a great way of updating common ground amongst your response team. Just remember: Though you have the authority to make the decisions, you should always leverage the expertise of your Subject Matter Experts (SMEs). You don’t need approval on your decisions, but asking for “any strong objections” prior to moving forward is always a good idea to prevent hindsight bias.
Stride Actions
Staying organized during the intensity of Incident Command can be difficult. Once a decision has been reached, a variety of actions often follow. Stride Actions are perfect for tracking the different investigations and experiments that are necessary to understanding the breadth of customer impact and how to potentially mitigate it.
For these sorts of time-sensitive actions, we also highly recommend three points:
- Assign them, either to an individual by name (“Dave Cliffe”) or by function (“Network on-call”).
- Time-box them, so the person knows how much time before they should come back with more information (this also helps to implicitly drive some urgency).
- Receive acknowledgement, so the Incident Commander knows they’ve understood the task.
Don’t Neglect the Postmortem
When the chaos has died down and the customer impact has been mitigated, one of the final items that an Incident Commander should do is assign the postmortem. Remember that every incident is a learning opportunity—and not just with respect to the technical aspects of your systems. Understanding how your teams communicate can help make future response efforts even more successful, so review your incident response process regularly. The PagerDuty JIRA integration also provides a great way of following up on action items that your response team has identified.
Modern incident response requires a new approach, one that embraces distributed ownership while enabling a precise, automated, and collaborative response that improves through iteration and learning. Using the PagerDuty Stride extension in concert with the JIRA and StatusPage integrations, PagerDuty and Atlassian provide a great platform for effective operations. Try it out and let us know what you think!
Additional resources:

