
AWS: Operations Health and Best Practices
by Ophir Ronen
November 26, 2018
| 5 min read
The ITOps world is a harsh working environment where ITOps personnel are expected to minimize the business impact of incidents at all hours of the day—regardless of the impact to themselves or their families. As more companies undergo digital transformation, the number of alerts and interruptions flowing to IT first responders will continue to increase.
This constant and growing pressure to keep business systems running around the clock is leading to higher-than-ever responder burnout, resulting in increased employee attrition and negative impact on the customer experience. In September 2018, we inspected 85,000 services to determine which monitoring systems are generating interrupt notifications (defined as SMS, voice, and push notifications) on each service.
AWS Integrated Services
The results? We found that services integrated with AWS have a consistently higher health score for every day through the first 7 months of 2018. On average, AWS integrated services have a higher daily health score by more than 3 points, as shown below.
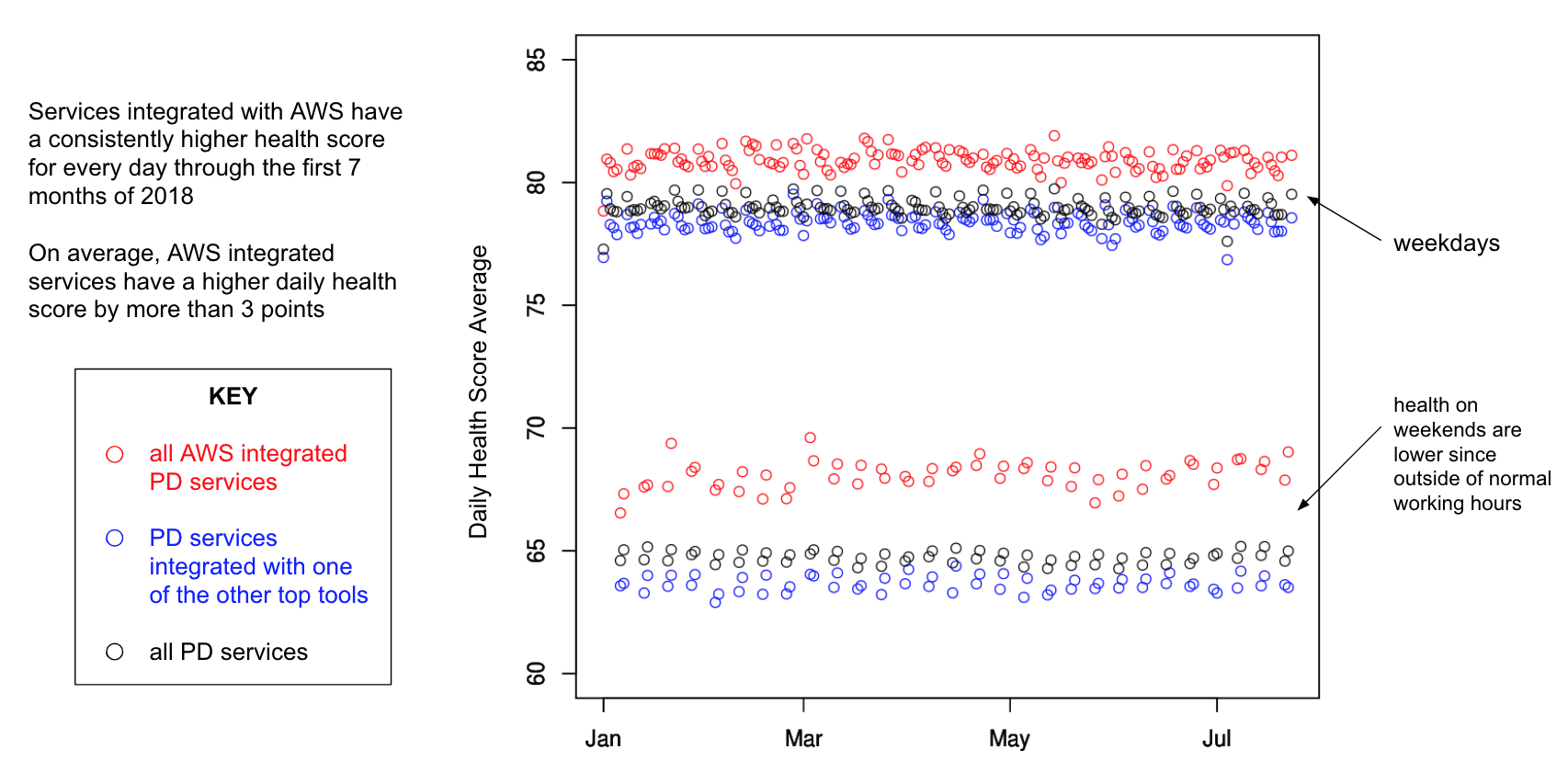
We also found that AWS integrated services had:
- 45 percent fewer daily notifications on average
- 52 percent fewer notifications during sleeping hours on average
- 60 percent fewer interrupt notifications during weekends
- Lower proportions of daily notifications during off-work and sleeping hours
- Lower number of days across periods of time (e.g., week or month) with off-work and sleeping hours notifications
So what is AWS doing to generate less noise and, therefore, less alert fatigue?
Short answer: We can’t definitively answer that. We can only speculate why AWS users experience better-than-average health compared to users of other DevOps tools—for example, there could be general AWS resiliency across both service offerings and instances or EC2 instance auto recovery and the highly available nature of most AWS services enable greater operations efficiency and generate less alerts. What we do know, however, is that based on our data collected from over 10,500 customers in the past decade, we have proven best practices that you can implement in order to attain measurable improvement in all three facets of operations health: people, efficiency, and maturity.
Best Practices for Operations Health
Run a Transient Notifications Analysis
One of the easiest ways to improve operations health is to run an analysis of transient notifications, which are alerts that auto close/auto resolve quickly after they’re generated.
Let’s say you’re an on-call responder who’s been awakened in the middle of the night by an SMS interrupt notification. You groggily acknowledge the event on your phone, then get out of bed and head to your laptop to begin remediation efforts. But the management system has already closed the incident, making it no longer relevant as it shows as closed (resolved). Now you’re grouchy—being woken up by an on-call alert is part of the job but being awakened for something that has already resolved itself is incredibly frustrating, especially if it occurs multiple times a night.
To help prevent such scenarios, you should run transient notification analyses to determine the number of transients that occur in under two minutes on each service. Then, depending on the percentage of transients, we add in a notification buffer of two minutes to absorb those transients while the upstream issue causing those them is being addressed. Any incident that remains open past the two-minute buffer is sent to whoever is on call. Absorbing transients in this manner increases the health of your teams, as well as the overall effectiveness of your operations by eliminating a significant source of false positives.
Alert Grouping
Humans are good at many things, but attempting to determine the scope of an incident by looking at a table of alerts gathered from a myriad of sources is not one of them.
With alert grouping, two great things happen together:
1) Alerts are automatically associated and grouped into incidents that provide much better situational awareness when compared to doing so manually, and
2) the on-call responder will receive 1 interrupt notification for an incident that includes 50 alerts as opposed to receiving 51 separate notifications for 50 alerts and 1 incident.
Service Taxonomies
Having a consistent taxonomy for your Teams, Schedules, Escalation Policies, and Services is another important best practice. Why? Because properly named services can shave crucial minutes off of incident response times by giving the responder context around what’s broken—making it easier to escalate incidents, bring in more subject matter experts, and, most importantly, decrease the business impact of incidents.
How Are You Thinking About Operations Health?
Keep in mind that one of the most important aspects of achieving better operations health is to work on continuous and measurable improvement. There are numerous other best practices you can use to help our customers improve their operations.
Methodology
To help mitigate the negative effects of on-call life, PagerDuty’s Operations Health Management Service (OHMS) analyzes the health of the organization through a human factors lens by pinpointing the services that are causing degradation of operations health and providing specific actionable recommendations for improving health in a measurable way. To learn more about our Operations Health Management Service, contact us today.

