
- PagerDuty /
- Blog /
- Best Practices & Insights /
- Better SecOps with Incident Management
Blog
Better SecOps with Incident Management
by Patrick O Fallon
July 7, 2017
| 6 min read
The threat landscape is expanding at a crazy pace. There are new vulnerabilities released every day, and the amount of servers, applications, and endpoints for ITOps to manage is continually growing. These threats are also growing more potent and frequent, as a recent spate of global ransomware attacks have seen perpetrators extort thousands of dollars. Experts believe that they’re often a ruse that mask attempts to destroy data.
As organizations adopt bimodal ITOps methodologies in order to be more agile, avoiding incidents and increasing security can pose quite a challenge. Some new challenges include leveraging containers and public cloud resources, managing security incidents across these separate data domains, and working entirely new sets of pseudo-admin users who have access to key resources. To enable full stack visibility and incident resolution for the ever-expanding demands on ITOps, a multifaceted strategy to SecOps is required. In fact, I tend to think of SecOps incident management as a necessary combination in order to build a truly secure environment that is both actionable and visible.
Phase 1: Stop the Threat
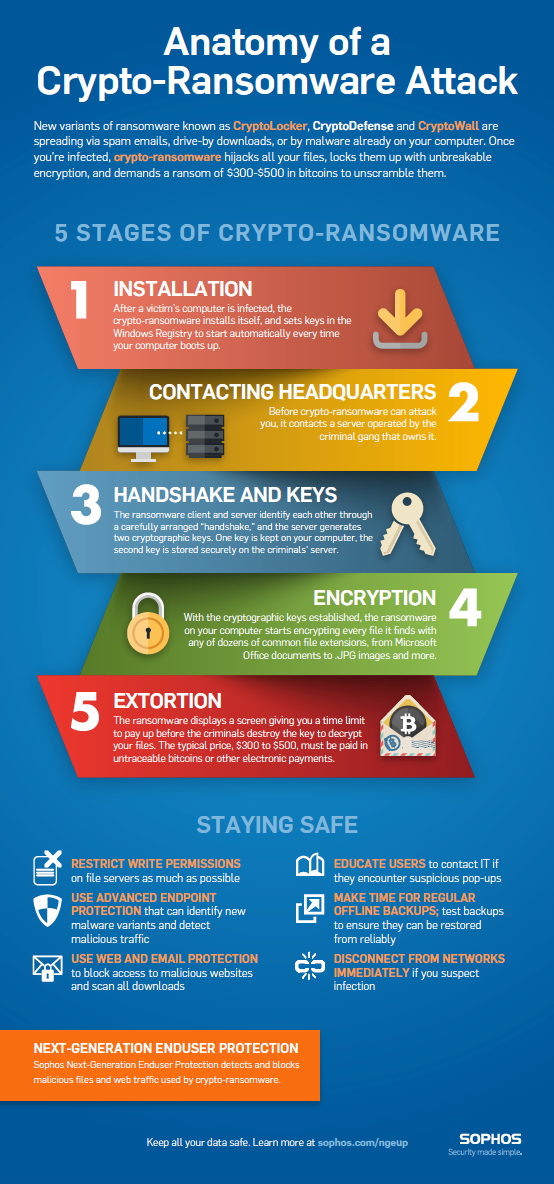
Source: Sophos – Anatomy of a Ransomware Attack (infographic)
First and foremost, reducing the complexity of your SecOps stack will help you maintain actionability while enforcing your SecOps policy. To put it simply, thwart the attack and notify your ITOps team that it needs to remediate. Simplicity is key when reducing the noise of your security alerts and incidents so you can focus on the signals that truly matter. SecOps practices advise that teams leverage a built-in stopwatch to react as quickly as possible and ensure threats are stopped before they do damage to production SLA’s and critical data. The best examples of this severity is when networks and systems are exposed to Zero-Day Threats or ransomware. In these cases, the key is to build a strategy around stopping and preventing exposure to massive threats while issuing alerts to your incident management system. In the case of crypto-ransomware, such as Cryptolocker and Cryptowall, the goal is to leverage tools that prevent the ransomware from engaging the threat (Stage 2 of the below infographic from Sophos), thereby preventing the handshake and averting the crypto infection.
We can then ensure that firewalls, endpoints, third party security monitoring tools, and other relevant data sources are piped into a central incident management solution. This way, SecOps and ITOps can be immediately notified and equipped with the data and workflows required for effective investigation and remediation of high-priority issues. Using effective security tools remains crucial for the success of managing your security incidents.
Phase 2 -> Incident Management and Remediation
The ability to not just detect and notify, but also enrich, escalate, and facilitate remediation and future prevention of issues are equally as important in best practice, end-to-end security incident lifecycle management. Again, to accomplish this full stack visibility, you’ll want to integrate and aggregate all of your security systems into a central incident management solution. For example, configure your firewalls and network devices to aggregate information into your monitoring platform by leveraging SNMP traps/queries, as well as integrating syslog servers to send all security incidents to these sources.

Source: Sophos UTM – Syslog Priority Values
When configuring your firewall and network syslogging, you can save a significant amount of time and reduce alert fatigue by configuring thresholds for warning and critical alerts versus info and debug alerts. Depending on your vendor, thresholding can vary. However, with SNMP, filtering the OID to disregard information-based and debug alerts while permitting alerts from warning and critical status messages, ensures that only high-priority alerts get sent to your incident management system.
With syslogging, you can set more granular logging conditions, but the key here is to keep the noise down and only notify on specific conditions. Once you’ve aggregated these events into your monitoring system, you can establish a framework to enriches the alerts with actionable information and routes them to your team to remediate threats.
Syslogging can be valuable for a few reasons. Not only does it capture detailed information on the security and the network data flowing into your monitoring systems, it can also facilitate intrusion detection and prevention as well as threat intelligence. Instead of piping your syslog directly into a monitoring system, you also have the option to send your syslog data into a third party intrusion analysis system like AlienVault or LogRhythm to increase your intrusion visibility and enrich your logging data, creating actionable alerts. Then you can send those alerts to your incident management system (such as PagerDuty) so you can group related symptoms, understand root cause, escalate to the right expert, remediate with the right context, and view and construct analytics and postmortems to improve future security incident response.
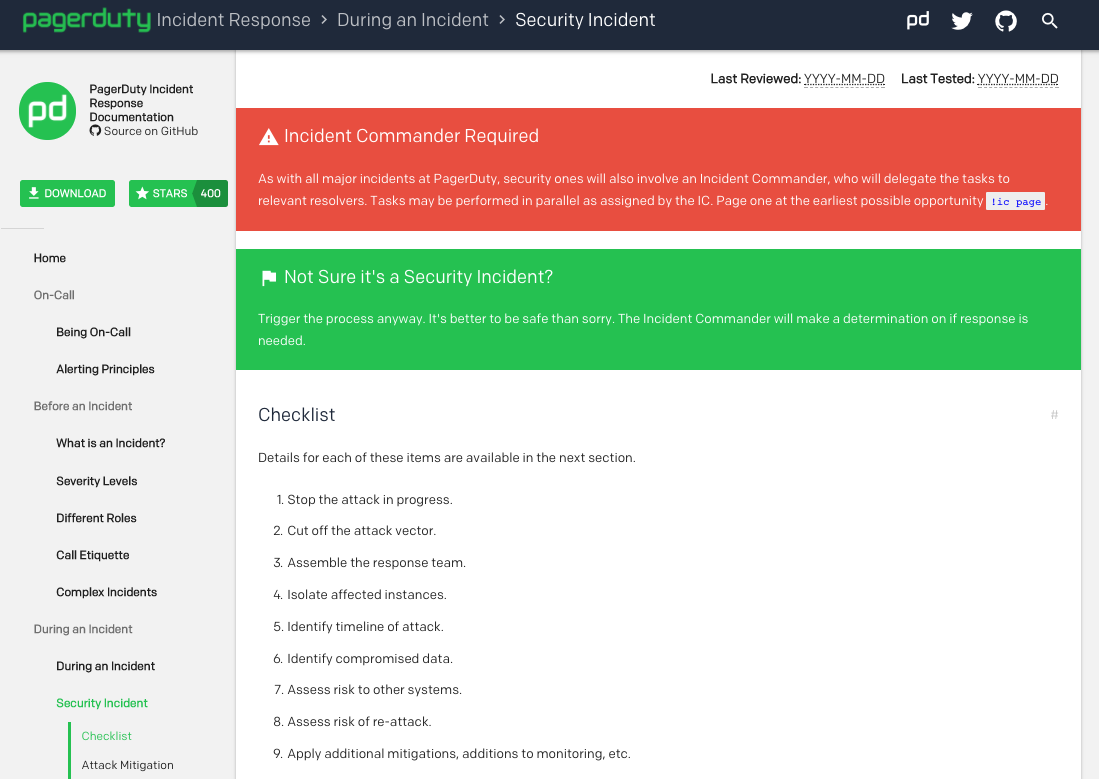
Source: PagerDuty Security Incident Response Documentation
- Bottom Line: Leverage security tools to actually stop the threat
- Baseline Monitoring: Establish a baseline monitoring and alerting policy
- Enrichment: Leverage third party tools to enrich your data and threat intelligence
- Incident Management: Gain full stack visibility and ensure issues are prioritized, routed and escalated. Improve time to resolution with workflows and analytics
Finally, the same framework can be implemented for organizations with hybrid cloud or public cloud resources, although you will need to leverage different third party tools to analyze and enrich your visibility and alerting. For example, leveraging Azure Alerts when leveraging Microsoft Cloud or AWS Cloud Watch when utilizing Amazon’s cloud will allow you to configure similar thresholding and noise reduction with your public cloud server monitoring and alerting. The good news is that there are also third party tools such as Evident.io and Threat Stack that will conveniently perform security-focused analyses across your cloud infrastructure, for anyone with an agile, public, hybrid, or bimodal ITOps strategy.
Whatever suite of tools and systems you prefer to leverage when designing full stack incident management processes that fit your SecOps team, the fundamentals of simplicity, visibility, noise reduction, and actionability remain paramount to success. ITOps and SecOps teams are in very similar positions in which the demands of the business often conflict with the ability of these teams to ensure secure and efficient access across an ever-growing list of devices, services, and other endpoints.
To learn more about best practices for security incident response, check out PagerDuty’s open-sourced documentation, which we use internally. You’ll get an actionable checklist and insights on how to cut off attack vectors, assemble your response team, deal with compromised data, and much more. We hope that these resources will give you a head start in building a solid framework for optimizing SecOps with effective incident management, as that will be your recipe for success.

