
- PagerDuty /
- Engineering Blog /
- Elixir at PagerDuty: Faster Processing with Stateful Services
Engineering Blog
Elixir at PagerDuty: Faster Processing with Stateful Services
by Elora Burns
June 23, 2020
| 9 min read
One of the core pieces of PagerDuty is sending users incident notifications. But not just any notifications—they need to be the right notifications at the right time to avoid spamming your phone when you’re already trying to deal with an incident. In 2018, using Elixir, we rewrote the service that schedules all of your PagerDuty notifications.
In this blog post, we’ll cover some context around how notifications work and take a look at how we leveraged the Erlang VM (aka BEAM) and Elixir to make the rewrite successful. I hope this post provides inspiration for you to consider a new paradigm when the old one just isn’t holding up anymore!
Ancient History
In the beginning, all notifications were sent directly by our monolithic Rails app.

In 2014, this scheduling behavior was extracted into a new Scala service: Artemis. At the time, Artemis was novel and used our home-grown, Cassandra-backed WorkQueue library to effect a synchronous, multi-region, and durable queue (Kafka didn’t quite check all these boxes back then).
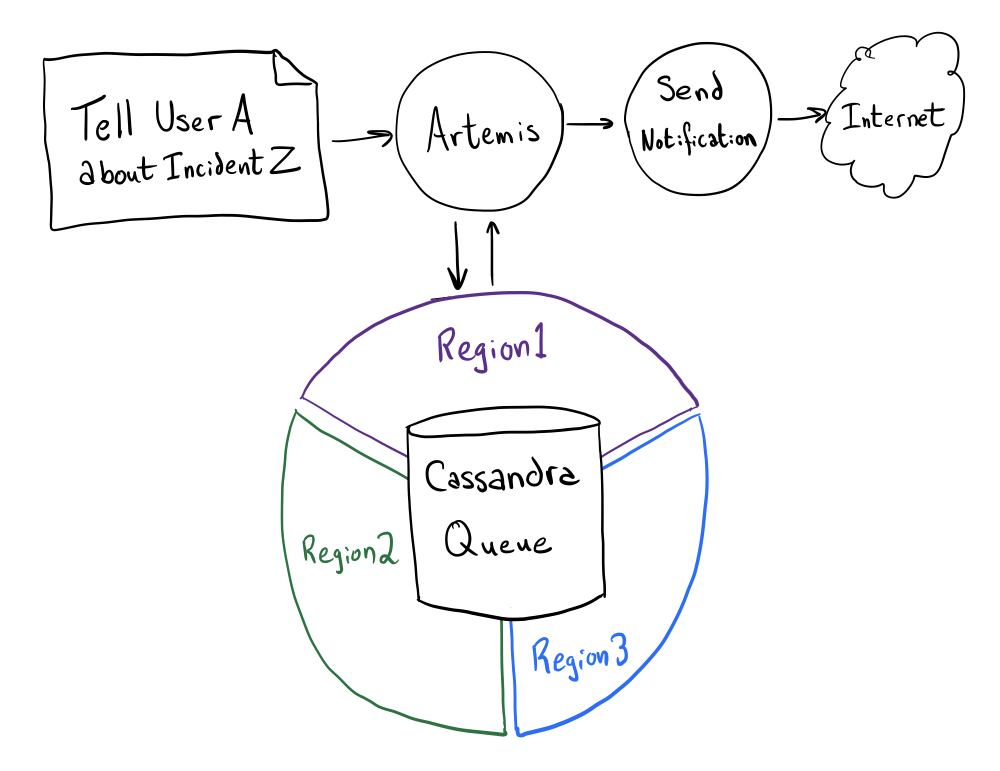
On top of this abstraction, Artemis was effectively stateless: poll a queue, lock a work item, do the work, unlock, forget. This fine-grained locking is effective and allows us to work on items anywhere and for unrelated work items to be executed concurrently; however, the overhead of taking distributed locks for every little thing is quite high and it did not scale.
Recent History
We reviewed the black-box behavior of the system (i.e., its inputs and outputs) and contrasted it with the complexity and infrastructural cost of Artemis. Something definitely had to be done. We considered doing minor remedial work, a major refurbishment in-place, or a full rewrite.
After careful consideration of the dangers of a full rewrite, we saw that the benefits outweighed the risks and decided to move forward. This is normally considered a risky proposition, but it worked for us in this situation because we wanted to stop using Scala, WorkQueue, and Cassandra. Our engineers were becoming less familiar with these technologies as they fell out of favor across the organization (and as the original code authors left), and our use of Cassandra was entirely off-label.
Three anti-patterns for Cassandra are:
- Don’t use Cassandra as a queue
- Don’t replicate synchronously across the Internet
- Very wide rows block Cassandra from scaling horizontally
We were doing all three. Since we were looking to use a new tech stack and completely change out the underlying data model, a full rewrite made more sense.
At the time, PagerDuty was starting to use Elixir for new services. Elixir is a language that compiles to run on the Erlang VM (BEAM), much like Scala compiles to the JVM. The Elixir/Erlang runtime brings a completely different paradigm consisting of independent, lightweight processes (100k in a single VM is completely normal) that can only communicate with each other via message passing. Erlang is not well suited to number crunching or shared-memory calculations, but it excels when there are a lot of separate things that need to be done asynchronously.
How Notification Scheduling Works
PagerDuty lets you configure custom contact methods and notification rules that indicate when to use those contact methods. For example:
- Add your mobile phone number (e.g., +1-555-555-0123)
- Add a notification rule to phone you immediately when an incident is assigned to you
- Add a notification rule to phone you 5 minutes after an incident is assigned to you (if it’s still open, assigned to you, and you still haven’t acknowledged it.)
Each contact method is treated separately, as are the different ways of using the same phone number (e.g., “phone 555-555-0123” is separate from “SMS 555-555-0123”). Low- and high-urgency incidents also don’t mix. Info notifications (“tell me immediately when an incident I’m assigned to is escalated/ack’d/resolved”) do interact with these rules, but it’s not relevant for this example.
Let’s say incident #1 is assigned to you. We’ll try calling you to let you know, but maybe you don’t answer. A few seconds later, another incident (#2) is also assigned to you. We won’t immediately tell you about it because we just tried calling you. We call this behavior “pacing,” and it keeps us from harassing you when you’re trying to fix the thing we’re telling you about.
Once the pacing interval has expired, we will tell you about incident #2 and the fact that you’re still assigned to incident #1. Let’s say you didn’t answer the phone that time either (maybe you were in the shower).
At the 5-minute mark, your next notification rule comes into play. This time, however, we notice that we need to tell you about incident #1 now and about incident #2 in a few seconds. This time, we’ll call you once to actively tell you about both. We call this behavior “bundling.”
Note that if either of these incidents were resolved or acknowledged by someone, we won’t keep telling you about them.
TL;DR: You have rules governing the intervals at which we will contact you about unhandled incidents. We try to send you as few notifications as is reasonable while also letting you know about everything that’s happening at each opportunity.
Notification Scheduling Service
Enter the Notification Scheduling Service (aka NSS). The beautiful thing about this problem is that it lends itself well to parallelism. Each user’s notifications in PagerDuty don’t interact with each other at all; each user is an island. Even within each user’s little island, each individual contact method (e.g., “Phone me at +1-555-555-0123 for high urgency incidents” vs “Push notify me on MarvinDroid for low urgency incidents”) doesn’t interact with another, except when mapping “user assigned to this incident” into contact methods via the user’s rules.
We model each User as an Erlang process, which manages its associated UserChannels (also each modeled as an Erlang process). This allows us to ingest new information quickly (enqueuing future-dated notification triggers for each incident-times-rule), but allowing each UserChannel to evolve its state at its own pace. On learning that we need to tell User A about incident #1, we send a message to User A’s User process. That User process consults the user’s notification rules and sends a message to all the relevant UserChannels telling them when they should tell the user about this incident.
The User’s job is now done! When a UserChannel decides that it’s time to send a notification, it just does it. In order to keep the UserChannel responsive, we keep the amount of synchronous work to a minimum. The UserChannel just records the list of incidents we need to send to the user’s contact method (via a NotificationBundle), removes the incidents from the UserChannel’s queue, and moves on. Each UserChannel manages its own pacing, treating “the timer has run out” exactly the same as “here’s something new to tell the user.”
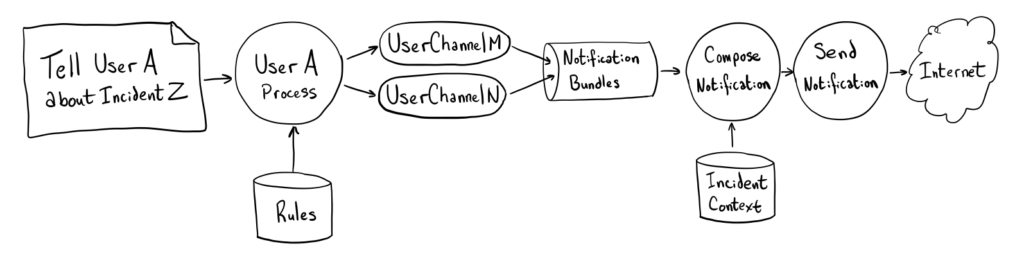
The NotificationBundles are picked up by a second stage in NSS which then determines the actual notification content to send to you. This can take a bit of time, but since these NotificationBundles are all destined for separate contact methods and users, we can parallelize the work.
PagerDuty is not a small system, but in computer terms, the number of open incidents that we handle is not “big data.” We keep all of this relevant state in memory so that it’s faster for us to act on. This is the opposite of the stateless Artemis system. We associate each user with a Kafka partition and ensure that there is at most one (and usually exactly one) instance of NSS handling any given partition. This makes it trivial for the User and associated UserChannels to be singletons in the system. With coarse-grained partition locking, we don’t need to synchronize processes every time they try to do a tiny piece of work. There is no other part of the system responsible for modifying that particular data except the one that’s currently working on it. Users and UserChannels are still responsible for persisting changes to their state, along with idempotency metadata, to allow for crash recovery and regular software deployments.
While it would be great to give each user their own independent partition, Kafka has a relatively low limit on the number of partitions (around 50k per cluster), so we can’t just give each user their own. Instead, as is usual with Kafka-driven applications, we divide our traffic into partitions. Because there are different kinds of data with different life cycles, we ended up using multiple topics with “parallel partitions.” Messages between these topics do not need synchronization, but we benefit from ensuring that all traffic for a given User shows up on the same set of partitions. In our case, we have three types of incoming messages:
- Updates to incident assignments/state
- Updates to user contact methods and notification rules
- Feedback from downstream systems (e.g., “This phone call is complete”)
We run a Partition Owner for each partition in the system, and it consumes from its partition of all three topics concurrently (e.g., the Partition Owner for Partition 1 coordinates the consuming and processing of data from the Incident Updates topic Partition 1, Notification Rules topic Partition 1, and Control Messages Partition 1.)
In the diagram below, all data destined for Users A and B ends up only on partitions numbered 1, and all data destined for users C and D ends up only on partitions numbered 2.
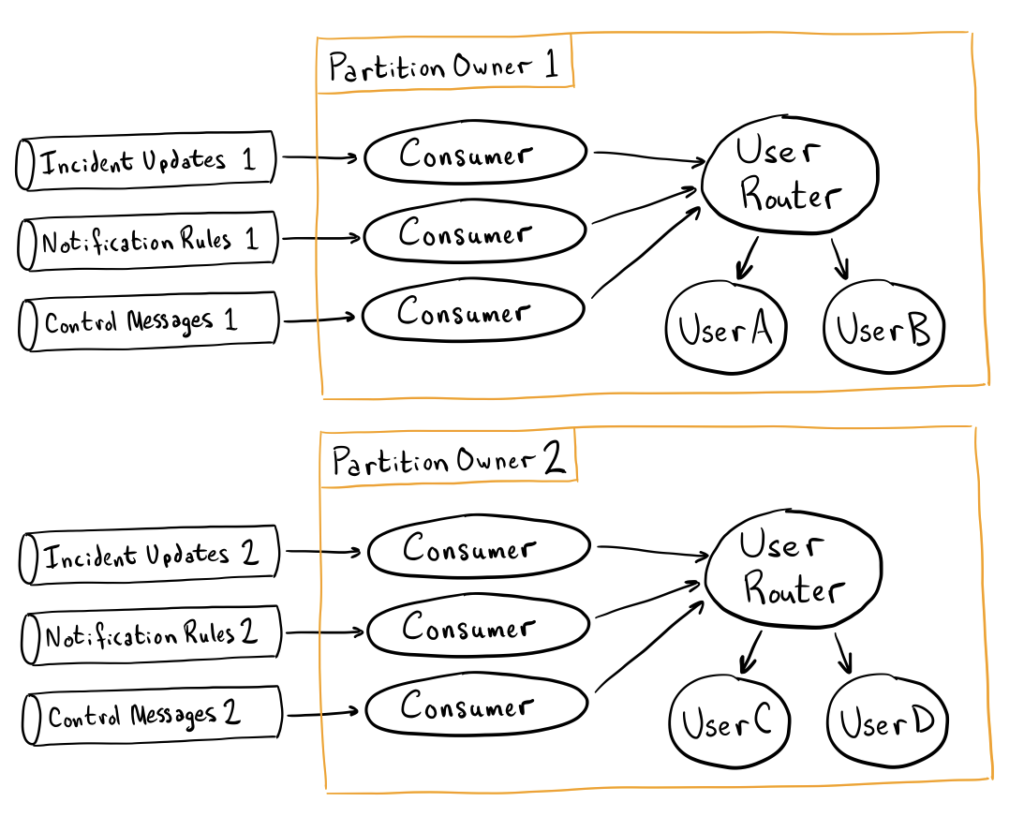
Outcome
Making NSS maintain state keeps all in-flight work in memory, where it’s fast to access. Locking occurs only at the partition level, avoiding the overhead of fine-grained locking for every piece of work. The use of lightweight processes to manage independent behaviors allows us to focus on one thing at a time where ordering matters and lets the system deal with doing lots of those at once where the ordering doesn’t matter. The new infrastructure is one-tenth the size (in terms of compute and data storage), imposes half the lag time, and provides 10x the throughput (with plenty of room for additional horizontal scaling). We’ve been running 100% of our notification traffic through it since January 2019, and we couldn’t be happier about how it’s held up to customer demands!
This post barely scratches the surface of what we did and what’s possible with Elixir. I’d love to publish a second installment building on this background. What parts of the system would you like to hear more about? Come tell us about it in our Community forums!
