
- PagerDuty /
- Engineering Blog /
- Writing Intelligent Health Checks for Kafka Services
Engineering Blog
Writing Intelligent Health Checks for Kafka Services
by Tanvir Pathan
May 12, 2020
| 8 min read
Health checks are vital for maintaining resiliency and ensuring continuous operations of any system. In an ideal world, health checks should be able to detect problems within a system as early as possible to either allow the system to automatically remediate or notify a service owner of the issue for manual resolution.
Creating the right health checks for a system can be difficult, as discussed in a great article by David Yanacek, a Principal Software Engineer at Amazon; however, when done right, health checks can effectively lower the downtime of a given service and reduce the impact a service can have on its reliant customers.
The main focus of this post will be on the health check implemented for the Event Ingestion Admin (EIA) service at PagerDuty. EIA is an administrative interface for the Events API that allows users to see information about various event types and the state of events while they’re being ingested and processed within our systems. I will focus on EIA’s Consumer application, which consumes events from various Kafka topics and saves those events to ElastiCache. After reading this blog, you’ll be able to see how a health check for a system reliant on Kafka can be written and how to deal with complications that may occur.
What’s Unhealthy?
The problem with EIA surfaced after the system unexpectedly crashed due to the Elixir logger’s inability to process new logs. We also knew that there had always been a chance that EIA could stop consuming new messages from Kafka and that we would be unaware until the problem escalated to a much higher severity.
Thus, there were two problems that needed to be solved with the health check for EIA: (1) making sure that the Kafka consumers were making forward progress, and (2) that the Elixir logger process continued to work without silently crashing. If either of these stopped functioning, the health check should fail, triggering the necessary actions to bring the system back to a stable state.
Once the problems are detected, fixing them is quite easy! The following code demonstrates the simplicity of what a health check endpoint ought to do:
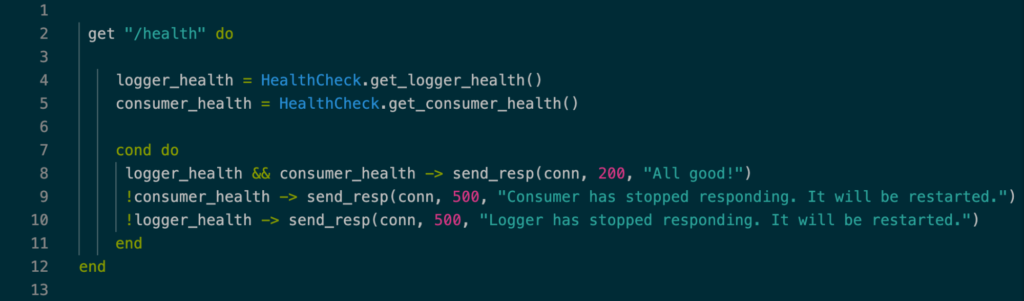
Image 1: The health check endpoint.
At the forefront of the health check is a networking tool called Consul. It is responsible for providing service discovery, health checks, load balancing, and more. In our case, Consul essentially pings the /health endpoint of the consumer application at a given frequency (every 10 seconds for EIA) to ask the system if it’s healthy or not. If the health of both the logger and the consumer app are okay, the service will return a 200 status code; otherwise, a 500 status code is returned, signaling Consul to start the recovery process (restarting the service).
While fixing the problem for this case was quite easy, detecting whether there was a problem proved to be much more difficult and interesting.
The Naive Approach
EIA consumes from a number of Kafka topics, and each topic has 64-100 partitions. We spin up separate containers for each topic consumer; each has its own health check and can be restarted individually based on its health state.
We started by creating an Elixir GenServer (generic server). A GenServer is a process that can store, state, and execute code asynchronously while communicating with other processes within the application. In particular, the health check GenServer is responsible for updating the current state of events and determining if the app is healthy based on the current state.
To do this, there were a few steps that had to be taken. Every time an event was ingested and processed, the state of the GenServer would be updated with a timestamp indicating the last time an event was processed successfully. When Consul would ping the /health endpoint, if the latest timestamp was within a 10-second threshold of the current time, then the consumer app was deemed healthy.
There were a few issues with this approach. No two consumers ingest and process messages at the same rate. Take the incoming_events topic and failed_events topic, for instance. The incoming_events topic is a high-throughput stream. If the threshold for determining a healthy topic was 20 seconds, the health check would be able to determine that it’s healthy.
Comparatively, the failed_events topic may not see any traffic within 20 seconds. The health check would believe that the failed_events consumer is unhealthy after that duration, which isn’t necessarily true. We could have set a different threshold for each consumer, but in non-production environments, there was a good chance that there would be no traffic at all for long periods of time. This would lead to EIA continuously getting restarted for no good reason.
If You Fail Once, Try, Try Again
Since we proved that a time-based approach would not be sufficient, the next idea was to leverage Kafka consumer offsets. There are two types of offsets that we wanted to use: the current (latest) offset and the committed offset. The current offset points to the last message that was sent to the topic, while the committed offset points to the last message that was processed successfully by the consumer.
To check if the consumer app was healthy, we wanted to ensure that forward progress was being made. Given that the latest offset was moving (i.e., consuming new messages), the committed offsets were moving as well (i.e., processing the new messages). With this solution, it wouldn’t matter when or if a message came in at all, thus solving the issue from the first approach.
To implement this solution, the health check GenServer needed to store a more complex set of information in its state. The following is a small excerpt of what the state is:
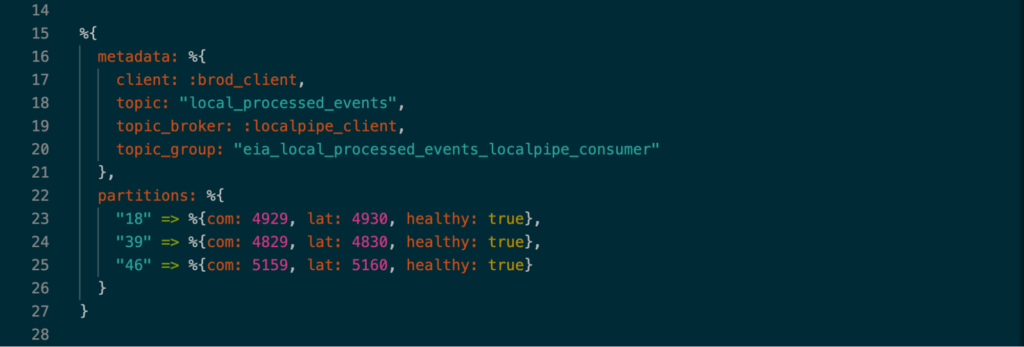
Image 2: Structure of the state.
There are two main components stored in the state: metadata (necessary to retrieve the different offsets) and partition information. Each partition stored the committed and latest offsets, along with a flag determining the health of the partition. Every time a new event would come in, the GenServer would be updated with the new offsets. When the networking tool pings the health check endpoint, the state would be iterated through to check if all the partitions were unhealthy. If they were, then the consumer container would be restarted.
After running tests in pre-production environments, the health check functioned well … or so we thought. After applying these changes to production, it became evident fairly quickly that the GenServer could not keep up with production traffic and the health check process kept crashing, causing the application to be in an unstable state. We reverted the change and went back to the drawing board.
Third Time’s the Charm
The biggest bottleneck with the previous approach was the amount of traffic that EIA had to process; thus, the next solution needed to be independent from the number of events that were being ingested. Fortunately, the answer was not too far from the solution at hand. Instead of updating the state of the GenServer after each event, the health check could update and check each partition every 10 seconds. Let’s take a look at the main function of the health check to see how this was achieved:
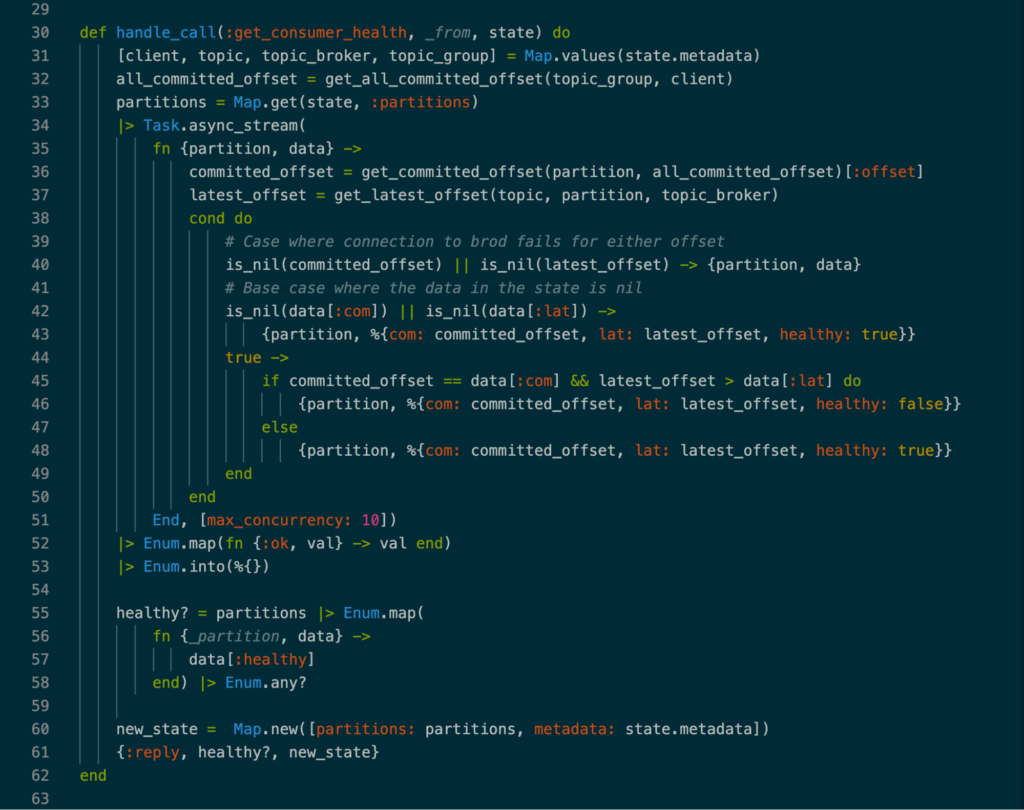
Image 3: Health Check Implementation.
When the GenServer is initialized, the partition data in the state is set as null. The first time Consul pings the health endpoint, the GenServer fetches for the committed and latest offset for each partition and sets them in the state. On each subsequent run, the current committed and latest offsets for each partition in Kafka are compared to the old ones stored in the state. If forward progress is being made, the health state of the partition is updated to true, and the state is then updated with the offsets. Once each partition is looked at and updated, the state is iterated on to check to see if the entire topic is healthy or not and return the appropriate value to Consul.
With this method, the number of events EIA consumed would not matter and thus the health check GenServer would be doing significantly less work than before. This was pushed back out to production and worked successfully! 🎉
Parting Thoughts
One of my key takeaways throughout the process is that the answer to a problem may not always be obvious at first. Depending on the system and its requirements, there is room for a lot of iterations before getting it just right. For someone new to Kafka, figuring out creative ways to leverage its tools to determine if a system was healthy was interesting and very rewarding in the end. If you are also looking to do something similar with a service reliant on Kafka, I’d love to share our lessons learned to help you out and hear how your process went!
