
- PagerDuty /
- Engineering Blog /
- How Lookups for Non-Existent Files Can Lead to Host Unresponsiveness
Engineering Blog
How Lookups for Non-Existent Files Can Lead to Host Unresponsiveness
by Tamim Khan
May 27, 2021
| 12 min read
Late last year, we had an interesting problem occur with the Kafka clusters in our staging environment. Random hosts across several clusters started experiencing events where they would become unresponsive for tens of seconds. These periods of unresponsiveness led to client connectivity and throughput issues with services using Kafka, in addition to under-replicated partitions and leader elections within Kafka.
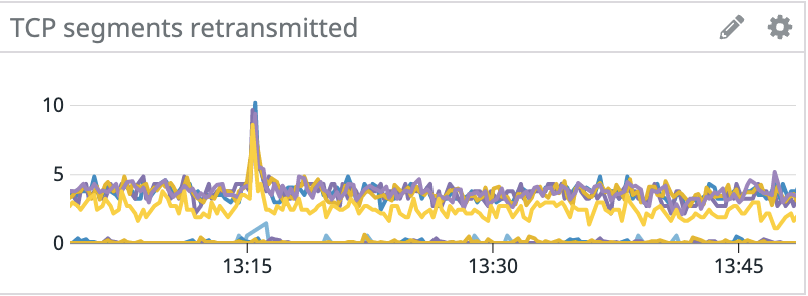
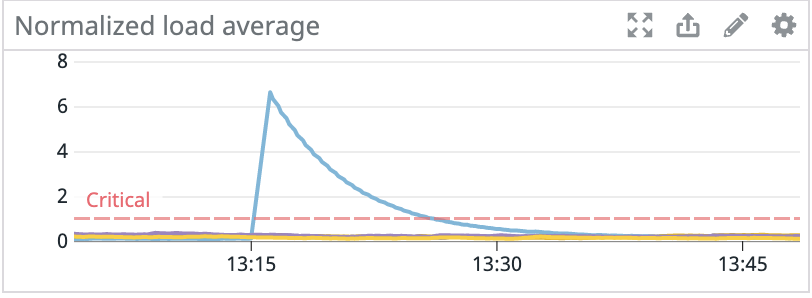
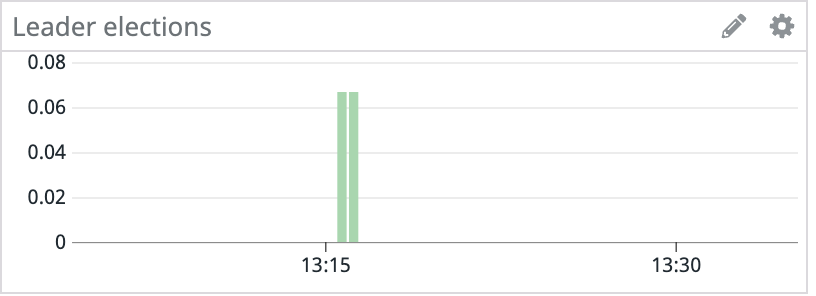
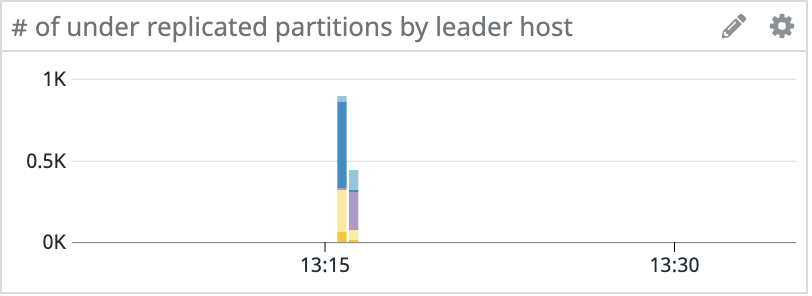
Since the issue started with only a handful of machines, we initially suspected degraded hardware, so we provisioned new machines to replace the problematic ones. This fixed the problem for the next couple of days, but eventually the newly provisioned machines also started to experience lockups.
Eventually, we discovered that the culprit responsible for these issues was third-party software that we were trialing at the time. When we initially began our investigation, we suspected this software since its rollout was somewhat aligned with the start of problems. However, our suspicion completely hinged on this correlation and wasn’t supported by any further evidence. The process monitoring tasks that this software was responsible for didn’t seem like they could lead to the system-wide machine unresponsiveness that we were experiencing.
So how were we able to trace this problem back to this tool and what was it doing that was leading our machines to become unresponsive?
Consistently Reproducing the Problem
Since the problem was occurring randomly, our first challenge was being on the right machine at the right time when it was occurring so we could investigate in real time. This is where we caught a lucky break and noticed while removing unnecessary dependencies from a long running host that systemctl --system daemon-reload could also reproduce the issue.
When we ran this command, our terminal locked up and our graphs looked identical to when the issue was occurring “randomly.” Running this command on a newly provisioned host had no such impact and returned instantly without any noticeable change in our graphs. A quick top showed us that systemctl was not really the culprit either but rather systemd itself, which was using most of the CPU at the time.
Using strace and perf to Find a Source
Since our problem was related to the network and all systemctl --system daemon-reload is supposed to do is reload all the unit files known to systemd, we figured systemd’s interaction with the kernel was probably the source of our problem. As a result, we ran a strace on the systemd process in order to get an idea of the system calls it was making and how long they were taking:
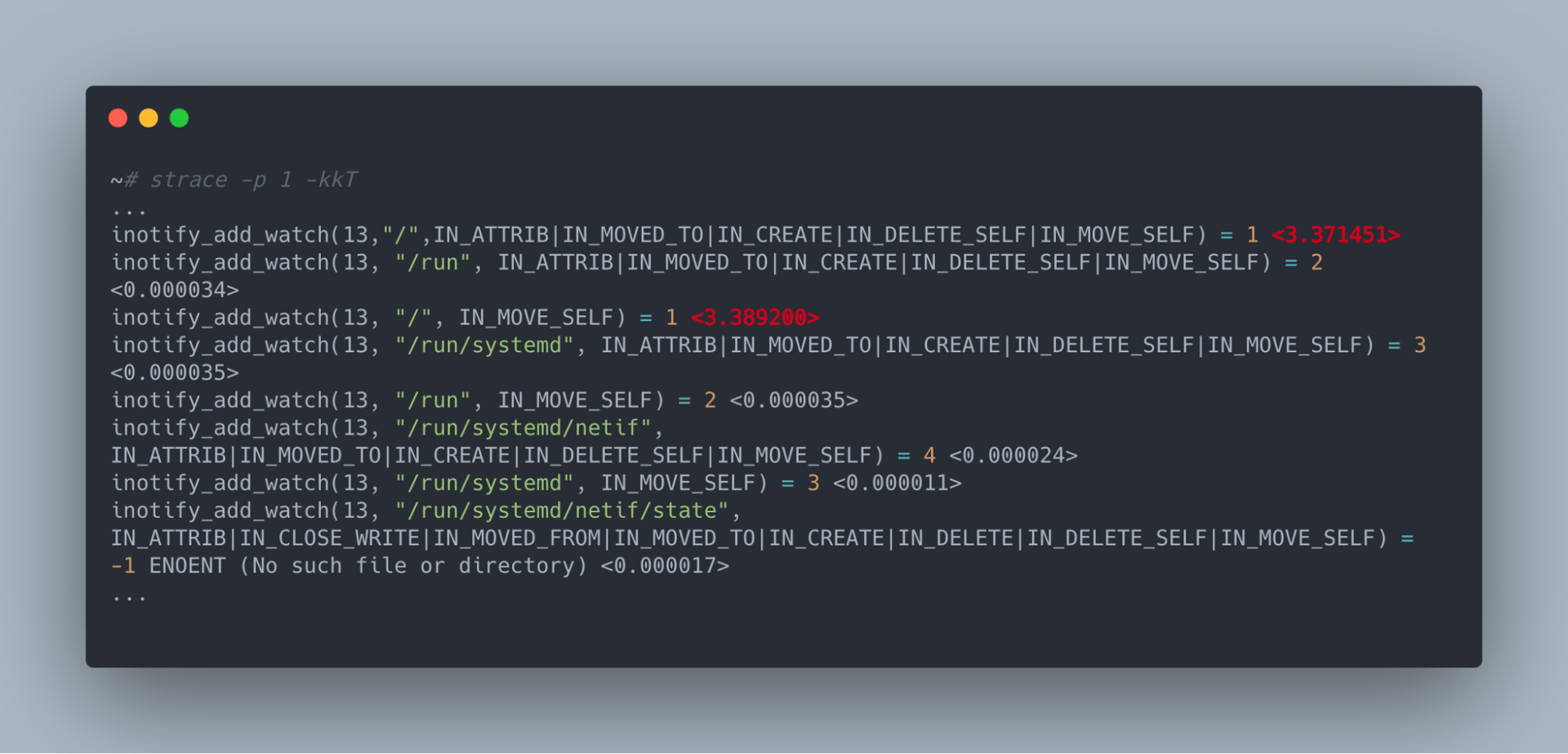
In this output, we can see all the syscalls being made systemd, the arguments to those syscalls, the return code of the syscall and most importantly how long the syscall took to execute. What immediately jumped out to us was that inotify_add_watch—specifically those on the / directory—seemed to take orders of magnitude longer than other inotify_add_watch calls. When we compared this to a machine unaffected by this issue, inotify_add_watch calls on the / directory were not special and took just as long as other directories.
While at this point we could try looking at the kernel source, there was a lot of code that can be called by inotify_add_watch. As a result, in order to narrow down our search further, we ran perf top to figure out where inotify_add_watch was spending most of its time:
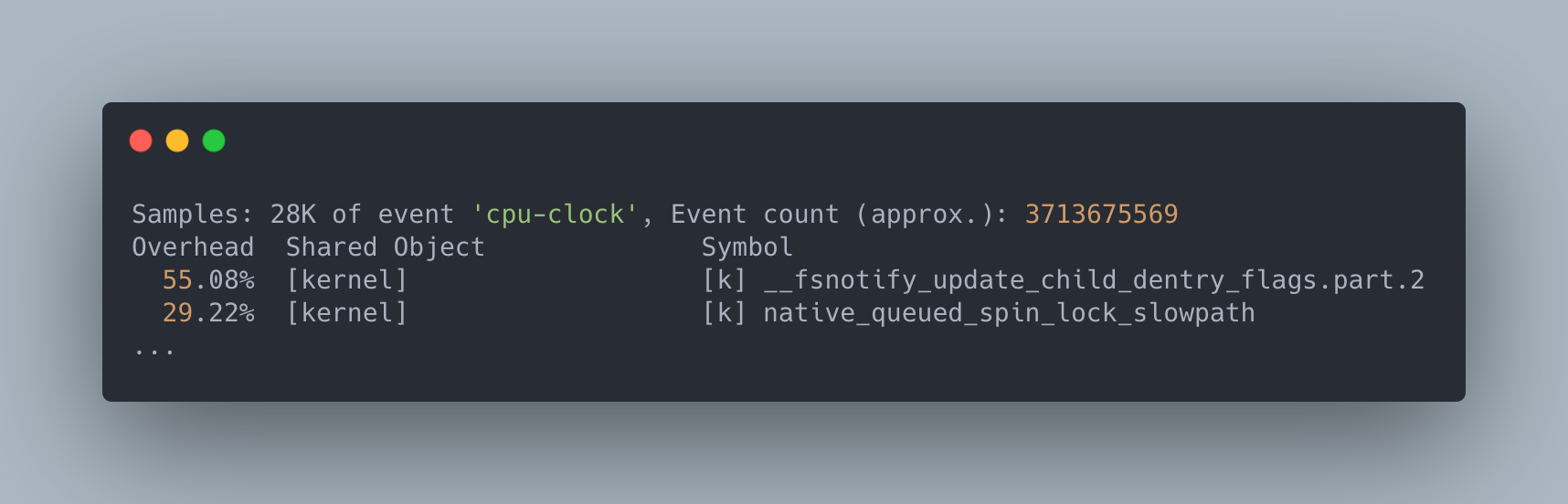
In this output, it looks like the kernel was spending a lot of time in __fsnotify_update_child_dentry_flags (55.08%), a function that updates flags on various dentry
dentry Objects and the dentry Cache
A directory entry or dentry is an object that makes it easier for the kernel to do path lookups. Effectively a dentry is created for every single component in a path. For example, the path /usr/bin/top would have a dentry for /, usr, bin and top. dentry objects are dynamically created by the kernel as files are accessed and don’t correspond to actual objects being stored on the filesystem. However, they do have a pointer to the structure that represents these file system objects (ie: an inode).
There are 3 possible states for a dentry: used, unused, and negative. A used dentry is one that points to a valid inode that is actively being used by something. A dentry object in the used state cannot be deleted regardless of memory pressure. An unused dentry also points to a valid inode but it is not actively being used by anything. These unused objects will be freed by the kernel if there is enough memory pressure but it will generally try to keep them around in case it ends up being used again. Finally, a negative dentry is one that doesn’t point to a valid inode. Negative dentry objects are created when lookups are made for non-existent paths or a file is deleted. They are kept around mainly to allow the lookups of non-existent paths to be faster but just like unused dentry objects these will be freed if there is enough memory pressure.
Since computing a dentry takes a non-trivial amount of work, the kernel caches dentry objects in a dentry cache. Among other things, the cache contains a hash table and hash functions that allow for the quick lookup of a dentry when given a full path. How this cache works is that when you access a file for the first time the kernel traverses the full path using the file system and puts the computed dentry objects for each component in the path in the dentry cache. When you access that file again there is no need to do that file system traversal again and you can just lookup the path using the dentry cache. This significantly speeds up the file lookup process.
Large dentry Cache
Now that we know what a dentry and dentry cache are let’s take a look at the kernel source of the __fsnotify_update_child_dentry_flags function to try to understand why the manipulation of dentry objects are leading to lockup issues:
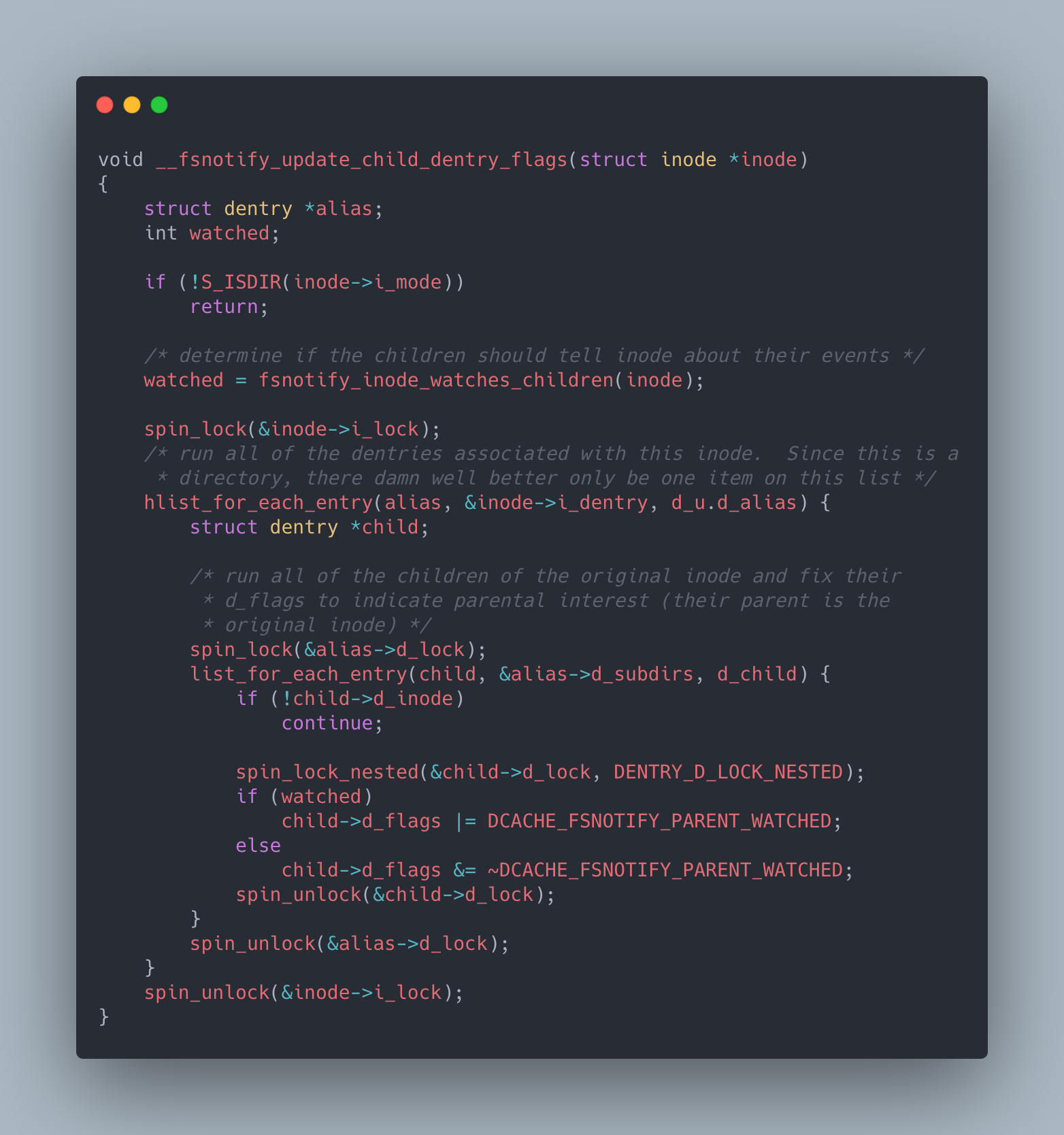
In this function, we are given an inode (ie: the / directory) and we go through the dentry objects for the given inode and all its subdirectories and change flags on them to indicate that we are interested in being notified when they change.
One important thing to call out here is that while we are going over all dentry objects associated with /, this function is taking a lock on both the inode and the dentry associated with /. Various filesystem related syscalls like stat (which needs to traverse dentry objects starting at /), read/write (which needs to inotify all parents of a given path including / is being accessed or modified) and many others also often need to take one of these locks in order to run to completion. Normally, this is not a problem since this function takes on the order of microseconds to run but if it doesn’t these syscalls could hang for large periods of time.
Another important thing to note is that attempting to take a spin_lock disables preemption on the CPU core running the syscall. This means that core cannot run anything other than interrupt processing until the syscall completes (ie: the syscall cannot be “preempted”). This is done mainly for performance reasons since otherwise a lock acquiring syscall could be preempted by something that also requires the same lock and that syscall would just waste CPU waiting for a lock that cannot be released. Normally, this is not a problem since kernel locks are supposed to be held for very short periods of time. But if kernel locks are held for a long time this could lead to a situation where several syscalls, all of which have prevented other things from running on their CPU core (ie: disabled preemption), prevent anything else from running on a machine for long periods of time as they wait for a lock to be released.
So now we have some reasons why this function taking a long time to run is problematic, but why is it taking a long time to run in the first place? Since the number of files on the filesystem between an unaffected and affected machine were effectively identical, it didn’t really make much sense for this function to take so much longer unless there were significantly more entries being tracked by the problematic machines or there was some sort of contention issue. In order to rule out the first case, we decided to take a look at the slabtop command to determine how many dentry objects were actually being stored by the kernel.
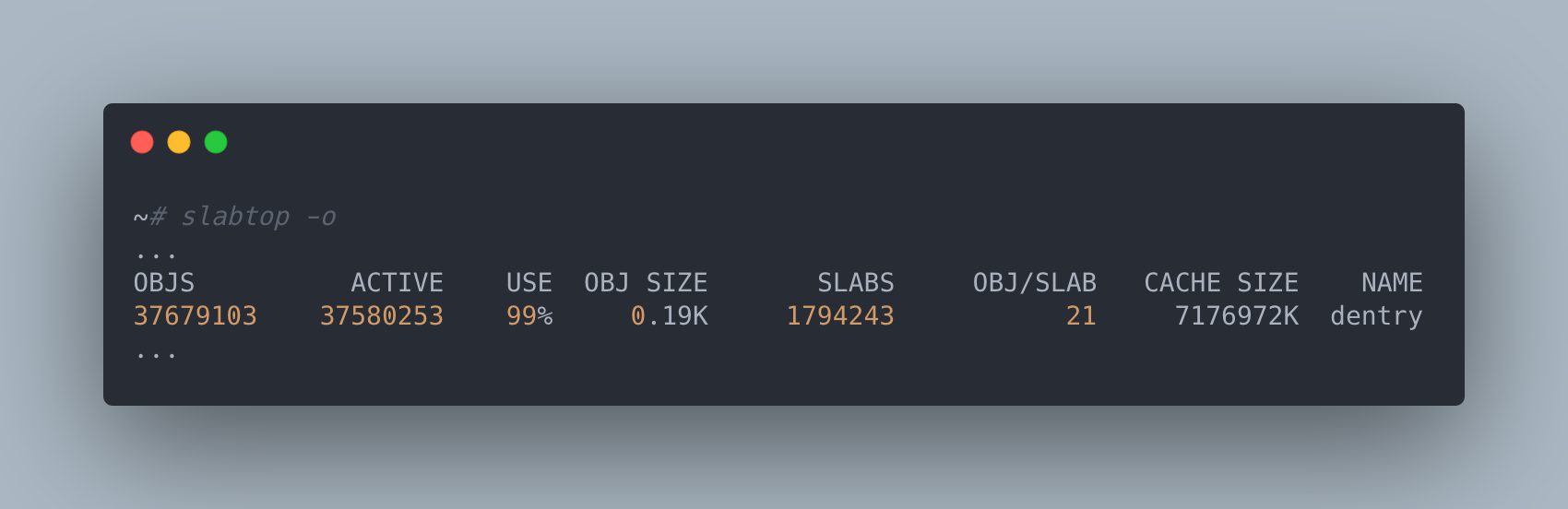
Now we are getting somewhere! The number of dentry objects on an affected machine was orders of magnitude larger than that of an unaffected machine. What’s more is that when we dropped the freeable dentry cache entries using echo 2 > /proc/sys/vm/drop_caches our systemctl command returned instantly and the random machine lock ups that were occurring on this machine disappeared. When we checked back in on this machine the next day we also noticed that the number of dentry objects being tracked had grown substantially. So something was actively creating dentry objects and this is why even newly provisioned machines would start to experience issues after some period of time.
Pinpointing the Source Application
With the information that the size of the dentry cache is the source of our problems and that some application on this machine is creating these dentry objects on a continuous basis, we can now start to instrument the kernel to try to find the source application. To achieve this we used bpftrace a program that uses eBFP features present in more recent kernels (4.x) to trace and instrument kernel functions. We mostly chose it since it had the features we needed and was quick to get working; however, there are other alternative programs that can achieve similar results (ie: systemtap). We came up with the following script to try to find the source:
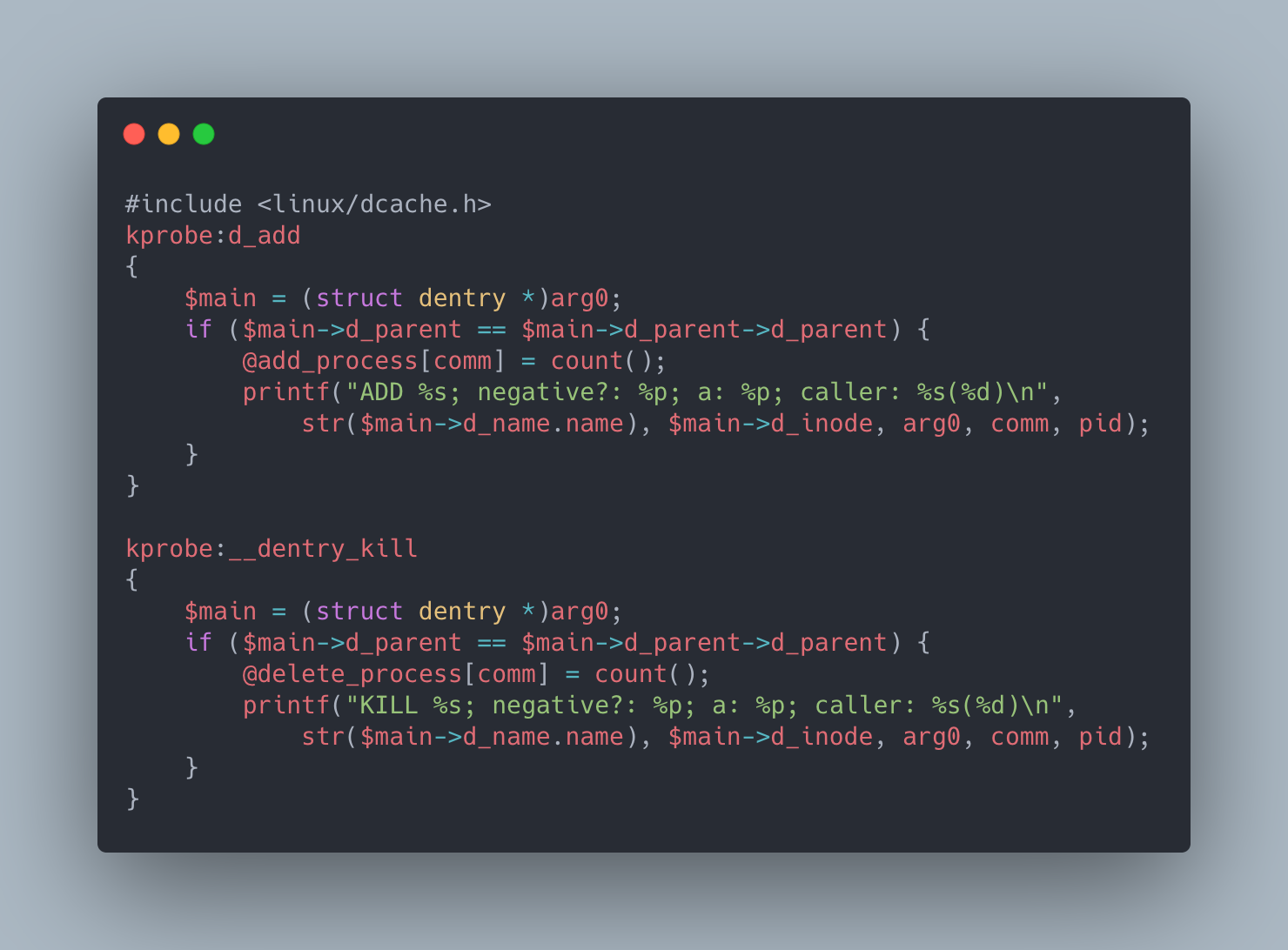
There are quite a few things going on here so let’s break it down. Here we are instrumenting the d_add function to track additions to the dentry cache and __dentry_kill function track removals to the cache. In order to reduce the amount of “noise” we get from other applications, we added an if statement to only find dentry objects that would end up on the / path. Next, we count() up all the calls made by comm (ie: the process that executed the sycall that got us here) and store them in an associative array (@..._process[...]) so that it is printed at the end of the run. Finally, in order to get an idea of what sort of dentry objects are actually getting created we print some information about each dentry as we encounter them including the name (ie: the path in the file system this dentry represents), if it’s in a negative state, and the inode it is associated with.
After running bpftrace with the script above for a couple minutes, a couple of things quickly jumped out to us:
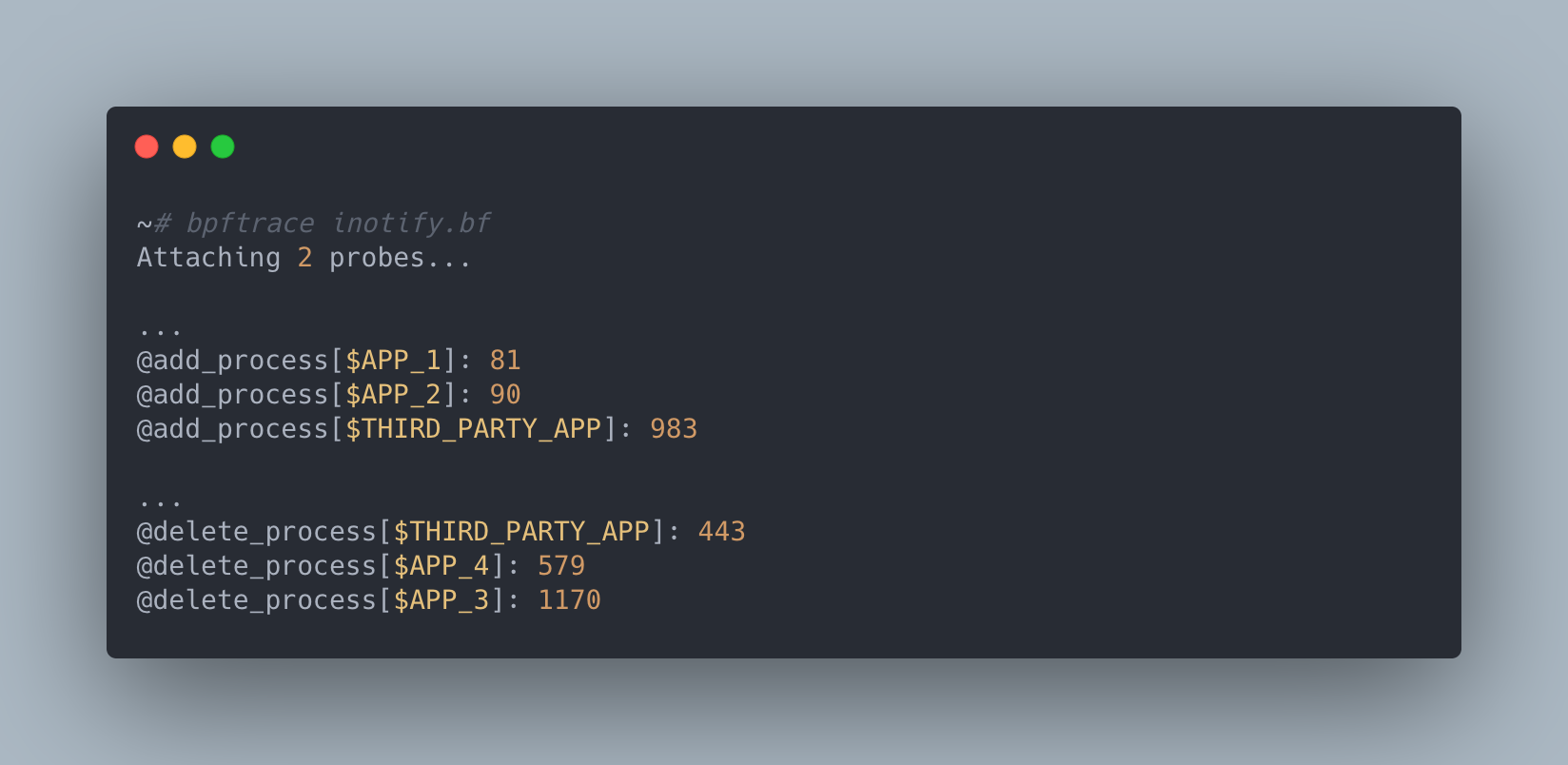
The vendor application we were trailing was making an order of magnitude more dentry objects than the next application on the host and also seemed to only be cleaning up about half of them during the timeframe we were running our trace. In addition, it was creating dentry objects that looked like the following:
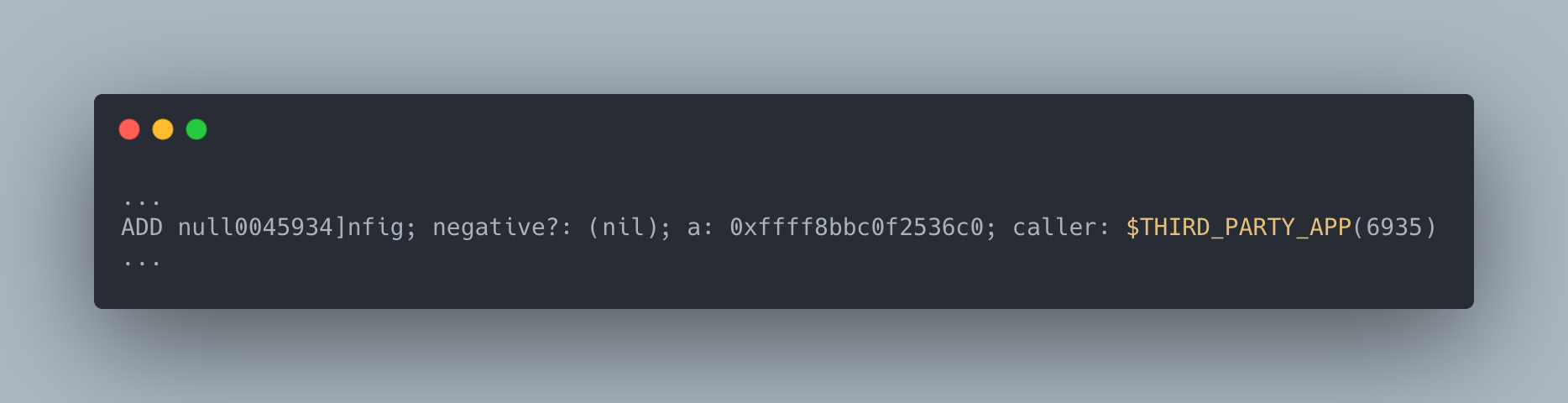
This is a negative dentry, which means the file does not exist on the filesystem, and it is also suspicious that the filename starts with null followed by a series of random letters and numbers. At this point we suspected that the app had a bug that was causing it to look up effectively random paths on /. This was causing the number of negative dentry objects being cached by the kernel to balloon over time eventually causing inotify_add_watch calls to take orders of magnitude longer while holding a lock that a wide variety of filesystem related calls require in order to function. Since we were running several threads that were making these sorts of filesystem related calls, they all attempted to wait for this lock while also disabling preemption on the CPU core on which they were being run, locking up the machine until inotify_add_watch had finished running.
Fixing the problem
At this point, we had enough data to go back to the vendor of the software and ask them to investigate. Sure enough, our suspicions were correct and they discovered a bug in their application where it was periodically doing lookups for invalid files on the / path. Once they fixed the bug and we deployed the new version of their software, our dentry cache growth issue disappeared and we stopped having random machine unresponsiveness events.
Getting here was no easy feat. However, we learned a lot about how to go from a generic problem (random machine unresponsiveness) to the root cause of an application doing a semily unrelated interaction with the kernel (creating negative dentry objects). Hopefully, you can use some of the tips here to trace your own problem down to an application’s interaction with the kernel. Happy hunting!
