
- PagerDuty /
- Blog /
- Reliability /
- Chef Testing at PagerDuty
Blog
Chef Testing at PagerDuty
by Ranjib Dey
November 14, 2013
| 5 min read
 At PagerDuty, all of our computing infrastructure is automated using Chef. We push out features and changes to our Chef codebase very frequently – often multiple times a day – and this makes it crucial that we test our Chef code before we deploy it to our production environment. As we have learned, failures can surface from unfrozen dependencies, improper values in config file, logic errors, bugs in underlying libraries, etc.
At PagerDuty, all of our computing infrastructure is automated using Chef. We push out features and changes to our Chef codebase very frequently – often multiple times a day – and this makes it crucial that we test our Chef code before we deploy it to our production environment. As we have learned, failures can surface from unfrozen dependencies, improper values in config file, logic errors, bugs in underlying libraries, etc.
In this post, we will walk through the 5 sequential testing tools/strategies that we use to create a predictable and stable infrastructure.
- Semantic Testing – In our Continuous Integration (CI) pipeline, the first step is to run a lint tool called Foodcritic which checks for semantic mistakes in our Chef code. It is fast and facilitates a uniform quality check. We stop immediately if it fails. We currently run Foodcritic only against our cookbooks (our berkshelf vendor directory is excluded).
- Unit Testing – The second step is to run unit testing via ChefSpec. We have bare bones coverage (i.e. check at least if the node is converging) of all recipes, and extensive coverage on PagerDuty-specific ones. We recently migrated to ChefSpec 3 (shout out to Seth Vargo for the rewrite), which offers chain-able assertions, custom matchers, and many other improvements. For some of the core cookbooks (i.e. iptables) we have custom matchers for the same cookbook’s LWRP’s. Generally we keep our PagerDuty specific recipes thin, LWRP’s thin, and a library that embodies most of the logic. Libraries are tested using raw RSpec. In general, we assert assumed dependencies (i.e. pd-apache’s spec will assert against “service[‘apache’]”) from community cookbooks. Because of Chef’s “elaborate” offerings on attribute precedence, it can be very difficult to predict what attribute will end up being used and ChefSpec provides a safety net for this. Unit testing also allows us to safely implement the why run modes in our custom LWRP’s. This has been incredibly helpful when refactoring critical components. We also now have a better understanding of the network dependencies we introduce with individual search calls.
- Functional Testing – We have a very small, but nascent functional test suite which currently covers ~80% of our infrastructure. For each of these tests, we have the top level run list items (i.e. roles that are directly assigned against nodes) applied against a linux container of the same platform and version (we use Ubuntu). The functional test suite creates an in memory Chef server (shout out to John Keiser), uploads all of the data via our restore script, spawns the container, and then performs a knife based bootstrap using our template. With this, all of our cookbooks, roles, environments are executed. We use a custom handler that stores the resource numbers and other stats as node attributes. We invoke Chef twice and use these metric attributes to check how many non-idempotent resources we have. We do have a handful of non-idempotent resources, and our goal is to get this to zero. Some of the functional tests also involve restoring staging environment data and converging the containers against it. This helps us simulate a real production or staging-like convergence and assert against configurations that involve searches extensively. All our third party integration (i.e. DataDog and Sumologic) are tested as part of this step. This also gives us a more frequent feedback on external API performance, as our production servers are consuming these API’s as well. After the assertions, the container goes through a tear-down, where we get to test all our knife based external tear-down, and chef-recipe based internal tear-down steps (i.e. deregistering external services or DNS removal). We use vanilla ruby-lxc bindings along with RSpec to test all this. While the functional tests are still ran locally, our end goal is to get this into Jenkins.
- Integration Testing – We have two main environments where all our Chef code is tested alongside all application code. We have a generic staging environment where features are deployed to and tested constantly. The second environment is where these features are load tested. Both of these environments are logically independent, but share some common services (i.e. AWS account or Chef Server).
- Failure Friday – In addition to all of this software testing, we also proactively inject failures into our Chef stack during our Failure Fridays. As part of this we have recently tested: Chef server timeouts, losing a Chef server and restoring from backup, and what happens to clients when the Chef server has high latencies and packet loss (spoiler alert: everything slows down). For more information on Failure Fridays, stay tuned for Doug’s post/presentation from DevOpsDays London.
We have extracted some key bits and pieces from our specs and made it available here:
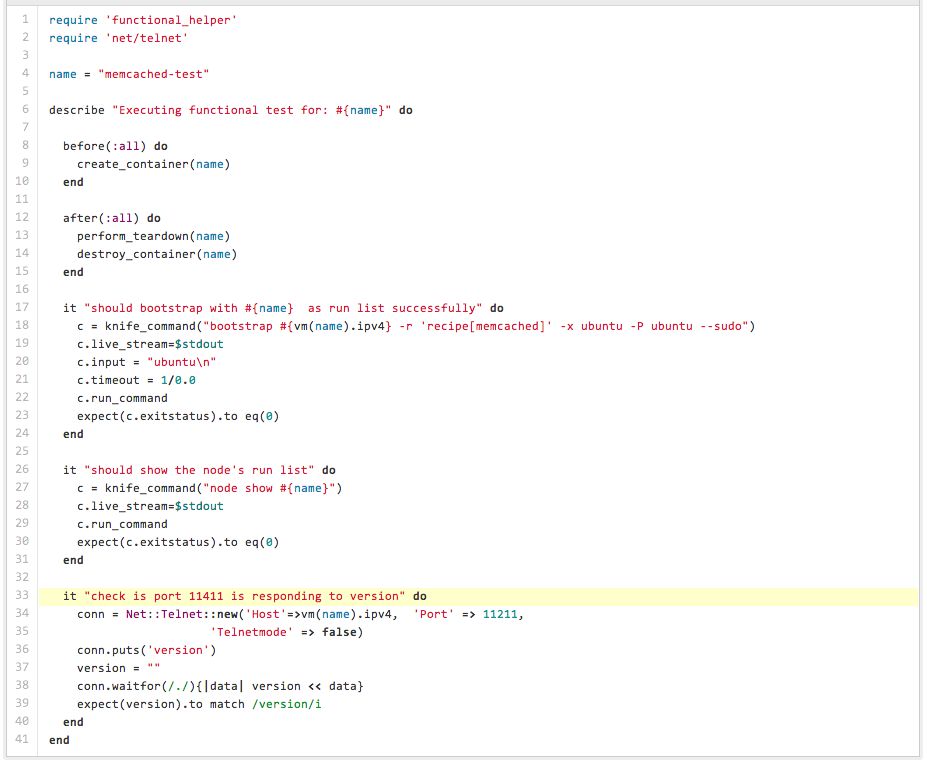
These solutions are based upon our current limitations by available tools and technologies we can adopt and integrate. Lot of these tooling deserve to go in their own respective code bases or have their own dedicated libraries, or merged against their corresponding mainline alternatives once the underlying stack is stabilized. But these should provide some concrete examples on top of which we can discuss, ideate and improve. Any feedback on this is welcomed.
Chef has been instrumental to our computing infrastructure. With automated testing, we can continuously deliver code. By decreasing our time to market and increasing the quality of our releases, PagerDuty customers can rely on our resilient, high availability infrastructure.

