
- PagerDuty /
- Blog /
- Partnerships /
- Prevent Outages in 2014 – Historical Data, Trends and Alert Processes
Blog
Prevent Outages in 2014 – Historical Data, Trends and Alert Processes
by Tony Albanese
February 4, 2014
| 5 min read
This is a guest blog post from CopperEgg, one of our monitoring partners, about how to analyze historical data to create an in-depth alerting process. CopperEgg provides an easy and lightweight solution for monitoring the performance of cloud applications and services. To learn more about CopperEgg visit their website (www.copperegg.com).
Last year, did your organization experience any major outages or performance issues that affected end users? Do you have a process in place to ensure those same issues don’t return this year? This blog details the best practices and tips to create an optimization process by mining historical performance data, analyzing the root cause of issues, and setting up an alert and response system.
Step 1: Look back at trends
The first step to foreseeing and preventing major issues with your servers, websites and applications is to review historical information. Historical data is important to review both immediately after an issue and over longer periods of time to evaluate trends. CopperEgg is great at this, and provides high-resolution data (5-second and 15-second performance updates) for the past 30 days, and low-resolution data (one-minute updates) for 1 year. With this data, users can go back in time to view performance trends, and also drill down into specific issues.
It is important to view historical data by the performance metrics that are valuable to your business. If delivering information to your customers is a primary goal, measuring performance by availability and response time, i.e. the percentage of uptime and the amount of time your customers have to wait, are a couple key performance metrics. For this example, you should look back at response times and availability during heavy traffic periods and view data over a longer period of time to look for irregular spikes and trends.
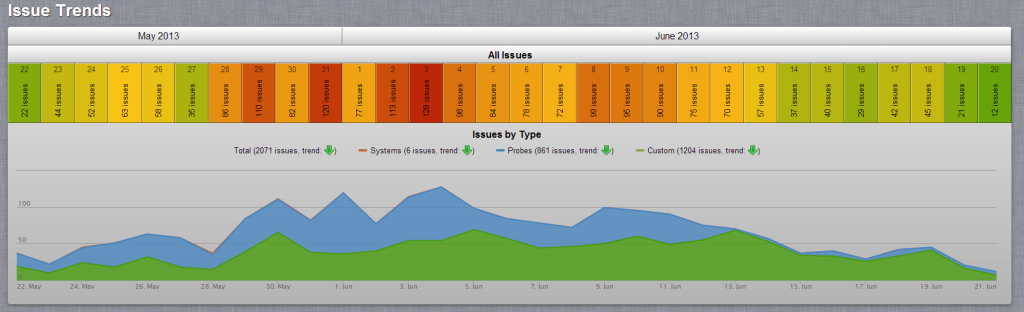
CopperEgg allows users to see both ends of this spectrum with at-a-glance performance overviews and second-level details. As seen in the photo above, the ability to see and quickly understand historical trends creates a solid platform to create a game plan for preventing issues.
Step 2: Address and find the root cause of major performance issues
Now that you have analyzed the historical data from your monitoring solution, it is time find the root cause of major performance issues. Hopefully this can be done easily and with one unified monitoring tool. If you are using CopperEgg, finding the root cause is easy. In two clicks or less, users can find detailed information such as related servers, websites, and process level details. Addressing these performance trends by looking to the root source is the most important step in preventing future performance issues.
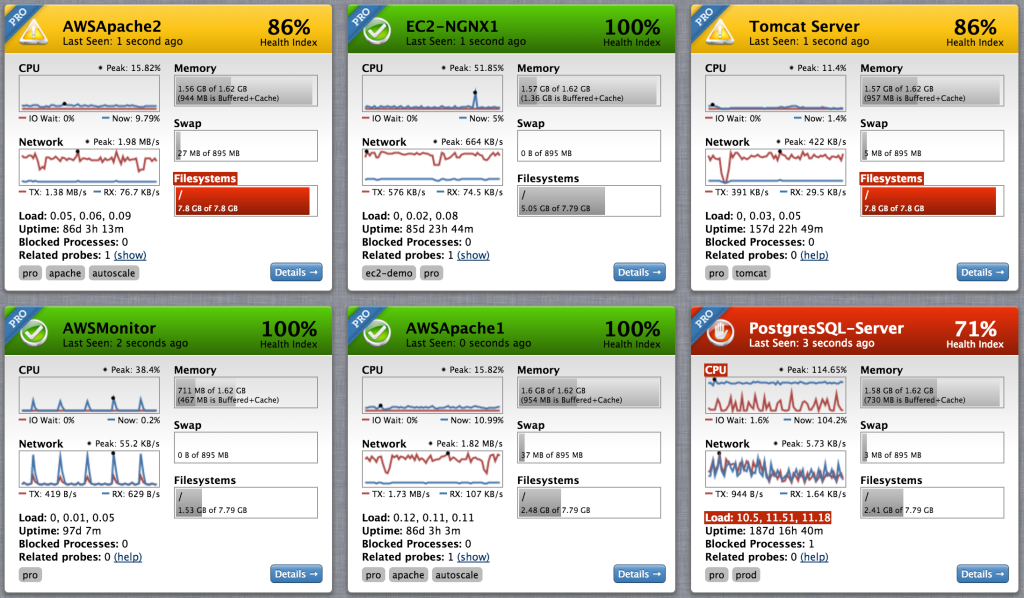
CopperEgg’s monitoring solution, as seen in the photo above, keeps track of all your performance metrics. Each widget provides a quick overview of your environment, and allows you drill down into the performance of individual servers, websites and applications.
Step 3: Set goals
At this point you should have a good grasp on the performance trends of your servers, websites and applications. The next step should be to set goals for improving or maintaining the performance level each of these. Goals should be based on the needs of your business, the past performance and how that performance translated into the overall accessibility of your specific business operations.
Is the performance of end user transactions, such as adding an item to a shopping cart, important to your business? If so, try setting a goal to have a quick response time and high completion rate for this type of transaction.
Step 4: Create specific alerts based on business goals
Next, you’ll want to transform your goals into alerts. Instead of being notified when your servers, websites and applications breach your defined set of goals, prepare a set of alerts that notify you as soon as issues begin. With CopperEgg, you can set the thresholds for which you are notified and how you are notified. With monitoring applications, it is necessary to increase the severity of your notification as the performance level moves closer to breaking your set goals. This way, you can better handle and manage high priority alerts.
Step 5: Aggregate and escalate your alerts with PagerDuty
Using PagerDuty, you can route alerts from your monitoring solutions to the right person for the job. PagerDuty’s escalation policies and on-call schedules you can ensure that your systems’ alerts are never missed, providing the most effective way to receive alerts and tackle your incidents.
With PagerDuty you can control downtime with effective incident alerting while offering individual customization for each of your team members’ notification preferences.
Step 6: Keep calm and monitor on
After you have addressed the major root causes of any potential outages, keep calm and relax! Using CopperEgg and PagerDuty together will ensure that you given ample warning time the next time something bad is about to happen. We believe a proper alert and monitoring system is the key to keeping calm and monitoring on!
Want to give CopperEgg a test drive? We are offering a free 14-day trial. To find out more about CopperEgg, visit CopperEgg.com or explore the self-guided live demo.

