
- PagerDuty /
- Engineering Blog /
- Collaborating to Build Secure, Maintainable Systems
Engineering Blog
Collaborating to Build Secure, Maintainable Systems
by Sarai Rosenberg
October 14, 2020
| 11 min read
I’ve built and taught others about building systems of many kinds—as a mathematician and teacher, and more recently as a security engineer in the last 6 years. Over time, I’ve found a few consistent patterns stand out as being effective lessons across domains and products and cultures. The approaches I will share often hold value for security and reliability—but they are fundamentally about people and about the processes that people use to collaborate with each other.
I first read some of these ideas from my mother’s 1971 copy of The Psychology of Computer Programming. These patterns aren’t without exception; they aren’t comprehensive, and these ideas have been written about by hundreds of people for decades. In this blog, I’ll share a few examples that helped me develop an empathetic intuition for concepts, processes, and models that help people collaborate effectively in system design, including:
- Preventing single points of failure
- Building rituals
- Building templates: Repeating known good patterns
- Experimenting with controlled variables: Varying from those patterns
- Drawing boundaries and crossing them with compassion
- Treating your colleagues fairly
Prevent Single Points of Failure
How many coworkers can leave before your team can’t maintain your service?
It’s vital to share knowledge, document your systems, and have multiple people of various backgrounds and levels test your documentation. On the PagerDuty Security team, we balance which tasks should be “quick wins” that can be quickly completed by someone with experience in that knowledge area, and which tasks should be spread across the team to share knowledge. Shared tasks also enable us to identify where we can improve our documentation, our code readability, and tools we use, such as dashboards and audit logs.
Every concept in building maintainable systems is eventually about managing risks. Single points of failure are considerable risks to your system that should be assessed regularly in your risk management program.
Imagine if a failure in any single service results in a complete outage for all customers at PagerDuty. That’s bad, right? We want our services to be robustly resilient to failures—to degrade gracefully, maintaining our customer commitment to providing the best of our product. The same reliability commitment that PagerDuty executives market to our customers also applies to our teams: We increase our points of failure and our resilience by sharing knowledge, by continuously improving our documentation through practical application, and by making our services interchangeable among teams.
Security leverages the concept of single points of failure in our threat models, too! Defense-in-Depth is a layered defense security strategy so that no single compromise is exploitable. By using Defense-in-Depth, we avoid the risk of a single point of failure where the failure of a single layer could expose a vulnerability in our infrastructure.
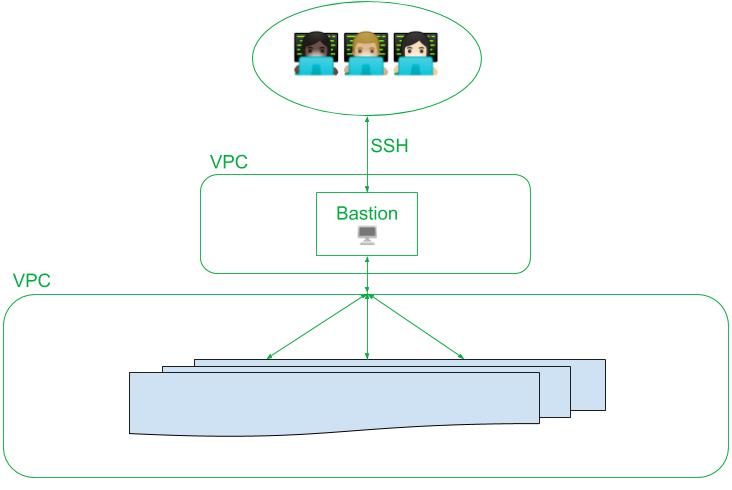
For example, the infrastructure security pattern of using hardened “bastion hosts” is a form of Defense-in-Depth that prevents a single point of failure. “Bastion hosts” are hardened, monitored servers and the only hosts in our infrastructure with an open SSH port 22. These hosts serve as an SSH proxy for our destination host; all SSH connections must pass through the hardened bastion hosts. SSH typically includes additional security layers, such as Access Control Lists (which require an auditable 2-person code review to change) and Multi-Factor Authentication such as hardware security keys, SSH keys, and SSH passphrases.
Furthermore, all infrastructure activity is logged, audited, and monitored by an Intrusion Detection System. Every system is protected by multiple layers of security—and these layers aren’t redundant but complementary components of building secure systems that are resilient to misconfiguration, to outage, and to exploitation.
Data flow diagram of a bastion host:
Build Rituals
Every mathematics course I’ve taught or taken starts from a set of principles that construct a foundation of what students are expected to know. While more abstract courses expect greater mathematical maturity from students, starting each mathematics course from axioms is a pedagogical ritual to build common ground.
Programming has long established a “Hello World” ritual: the classic introduction to a new tool or programming language is an exercise that produces the text “Hello World!” This ritual reduces the cognitive load of the first learning exercise using a familiar pattern, allowing the learner to focus on the syntax and semantics of the new language.
At PagerDuty, we introduced a “Hello Pagey” modular onboarding exercise that walks our new software engineers through the steps of deploying a miniature, personal “Hello Pagey” microservice using PagerDuty’s infrastructure tools. Each module offers a gentle, step-by-step introduction to our coding practices, style guide, CI/CD tools, container orchestration, Terraform, and handling secrets such as API keys. The final module produces a satisfying web API endpoint that prints the return text “beep” after sending “boop” to another “Hello Pagey” microservice.
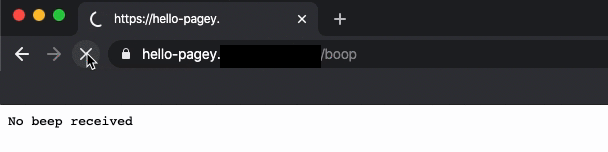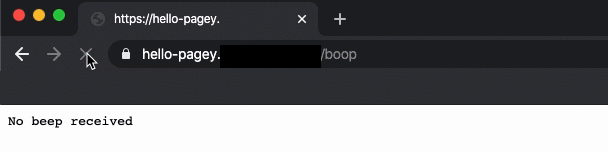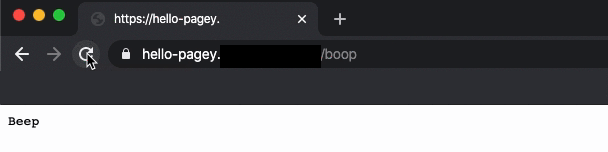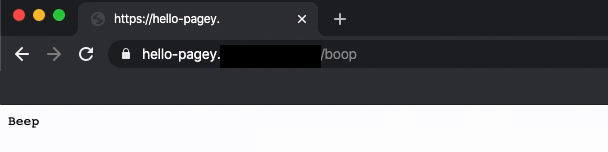
Some rituals span teams, and some are unique to your team. Find them, and leverage those rituals that are working for you.
Build Templates: Repeat Known Good Patterns
Rituals are one form of procedural templates. Templating applies to everything from procedures to our tech stack and our service “skeletons” for generating new microservices. Following Known Good Patterns means that when someone else needs to learn your service, they know how to navigate the code and documentation, they know where to manage monitors, and they have the gist of maintaining the service without ever having seen it.
Sometimes using Known Good Patterns means departing from what may appear to be “the best solution” for the sake of a familiar pattern with known weaknesses. The engineering tradeoffs are debatable for any given issue—but let’s have a chat about how Known Good Patterns impact security and risk management.
Using the same old Known Good tools and patterns generally means that our Security team has examined the pattern and helped to secure it—such as the hardened base Docker images produced by our SOC 2 System Hardening Project. When an engineering team builds a service from service skeletons and hardened base Docker images, their service inherits vulnerability scanning, monitoring, audit logs, and many more of the secure development practices required by PagerDuty Security for a production service.
Some aspects of using Known Good Patterns are more critical to security than others. For instance, it doesn’t matter which local software that our developers use to write code—but our security would be compromised by authorizing a non-approved cloud service to access our source code.

Experiment With Controlled Variables: Vary From Those Patterns
Good scientific experiment design relies on holding some controlled variables (“control group”) constant while testing the impact of changing selected experimental variables (“experiment group”). Experiments start with a hypothesis about what we expect to see, and how we measure differences from the control group.
PagerDuty’s Failure Friday template for chaos engineering experiments has some similar elements, as do our experiments when we deploy changes to staging, either by dogfooding, by feature flags, or by diverting percentage points of load balancer traffic to experiments. The Failure Friday template is an established ritual pattern based on the Incident Response structure familiar to every PagerDuty engineer. The team that owns that week’s Failure Friday event customizes the template with a plan of the experiment they will run. One crucial element of our Failure Friday template is a rollback plan: How do we handle ending, aborting, or rolling back our experiment? Of course, not all experiments go according to plan. 😏
The PagerDuty Security team encountered an experiment opportunity recently while we were discussing how we handle security requirements for a service scheduled to sunset in a few months. The short upcoming lifespan meant that we would have a few months to see the results of our experiment, but we wouldn’t bear the cost of rolling it back. However, legacy services can be dangerous for experimentation because they are often too dissimilar from our newer monostack services—in other words, the experiment would have few control variables, which increases risk and reduces the value of results. Our risks outweighed the value of the experiment, so we chose not to move ahead with it.
In contrast, PagerDuty’s Site Reliability Engineering (SRE) team completed experiments with Terraform that proved to be a good risk. They produced a valuable new pattern for service owners to use Terraform for Amazon Web Services (AWS) resources. In parallel, the PagerDuty Security team developed a threat model for automated access to AWS Identity and Access Management (IAM) using the STRIDE threat model and the DREAD risk assessment model. Our team used that threat model to plan and complete an AWS IAM Permission Automation project which mitigated risks from SRE’s Terraform project for automated access.
Image showing a DREAD template:
Draw Boundaries, and Cross Them With Compassion
Our engineering teams use the PagerDuty product’s “Service Directory” feature, which defines service ownership for our teams and services: the Service Directory delineates boundaries of ownership and responsibility for PagerDuty tools and services.
Boundaries allow us to operate freely with a sense of shared trust within and between our teams. Boundaries allow a team to iterate on experiments within their boundaries, while defining their accountability to follow shared expectations, rituals, and patterns that span across teams.
Crossing a boundary is a violation of shared expectations, but can be done with compassion in support of another person or team. In both personal and organizational collaboration, crossing boundaries can be a powerful tool of compassionate collaboration.
In digital operations, crossing boundaries is necessary for almost every operational incident because the contributing factors span multiple teams. Almost every security incident is a shared responsibility, where our Security team collaborates with one or multiple teams to resolve the incident, following the ritual of our Security Incident Response process.
We talk about crossing boundaries when we refer to reassigning an incident as “tossing it over the wall”—and that phrase communicates that we feel a boundary was violated. Even a “warm handoff” is an opportunity for compassionate boundary crossing! Approach those moments with empathy for your colleagues by entering the conversation with a question such as, “Can I help you with this?” If your expertise is relevant to someone, your time is best spent collaborating with them to share that knowledge and discover how to more efficiently prevent future incidents and spread your expertise.
When you cross a boundary, take care to recognize the expertise and ownership of others. Be explicit about what you are offering, and check in with your colleagues about their needs—essentially, you’re offering to renegotiate the boundaries to provide your support. Bring compassion to that negotiation by explicitly acknowledging your respect for their expertise, and validate any concerns that they raise with empathy.
Treat Your Colleagues Fairly
Software engineering is a team sport. We all have to collaborate—and we collaborate more effectively within an atmosphere of mutual trust and respect. Part of cultivating a compassionate culture is consistently communicating your trust and respect.
Think of expressing the respect you have for the skills and expertise of your colleagues as the syntactic sugar of effective collaboration: It’s not strictly necessary, but it sure does make working with you a lot easier! While a plain text log contains the same raw data as a structured log, the structured log separates and identifies each piece of information, associated with attributes. We can usually identify the meaning of a timestamp or log severity from the log. Structured logging provides explicit context that helps your audience parse data efficiently, especially during tense moments like incident response.
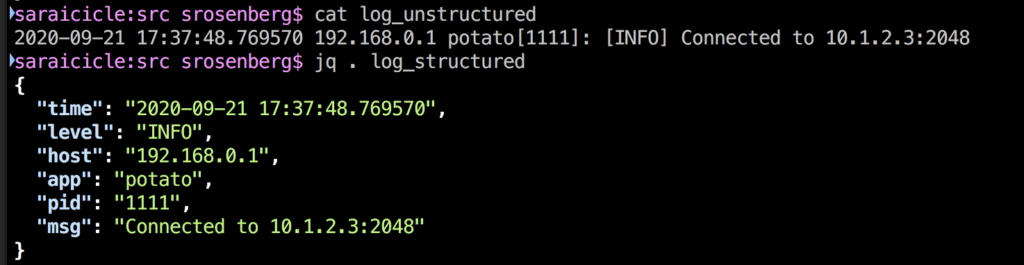
We cannot do our best work to build secure, maintainable, reliable systems if we do not trust each other or if we do not feel safe. Just like a structured log, stating that explicitly can make all the difference for building and maintaining strong collaborative relationships. Working together doesn’t mean we always agree with each other, that we don’t have conflicts, or that we want to drink tea together every afternoon. Our success is mutual: By going beyond the minimum to build compassionate collaboration, we learn and grow more together, and we accomplish more.
These ideas are only a starting point. What patterns are you noticing in your teams? What resources have helped your teams develop a culture of collaboration in system design? What resources have helped you learn about patterns in building secure and maintainable systems? Tell us about it by tweeting @pagerduty or commenting on this blog and in our community forums!
