
- PagerDuty /
- Engineering Blog /
- Distributed Task Scheduling, Part 3: Handling Data Center Outages
Engineering Blog
Distributed Task Scheduling, Part 3: Handling Data Center Outages
by David Van Geest
December 5, 2017
| 7 min read
In an earlier post, we discussed how PagerDuty has built a distributed task scheduler using Akka, Kafka, and Cassandra. This open-source Scala library schedules and executes some of our critical tasks, despite rapidly changing infrastructure, and it’s name (rather appropriately) is Scheduler.
In part 2 of the series, we tackled the problem of dynamic load by showing how various components can be scaled up or down. This time around, we’ll talk about handling failure on a large scale. What happens when one of your data centers goes dark? Will your scheduled tasks still run on time, and in order? Will they run at all?
In this post I’ll use the term “data center” or “DC” in a very loose and generic way. It could mean an availability zone of a cloud provider (like AWS’ US-East-1a), or it could mean an entire region (like Azure’s Fresno). It could equally apply to a certain rack of co-located physical machines. The physical distances between data centers, and their network capabilities, do clearly affect the ability of a distributed system to perform its work in a timely and consistent manner; in fact, spanning a Kafka cluster across geographically distributed data centers is considered an anti-pattern by the folks at Confluent. However, many of the concepts discussed below can be applied to systems of different scale; for the purposes of this article a “data center” is a group of closely-networked machines sharing infrastructure that may cause failure in the entire group.
As in the previous post, we’ll address this large scale failure scenario for each component of Scheduler. Ultimately, Scheduler’s resiliency to failure is a sum of its parts.
Handling Failure in Kafka
The first question we must ask is how our tasks can be scheduled in the face of DC failure. Task scheduling is done via Kafka in Scheduler, and we want to be very sure that scheduling a task is a durable operation. Our customers’ data is very important to us!
At PagerDuty, a common setup is to have six brokers evenly split across three data centers, so two brokers in each DC. A given topic-partition has three replicas, and we use Kafka’s rack-aware partition assignment to ensure that each DC has a replica of each partition. Scheduling a task means producing it to Kafka, therefore we want to ensure that the produce is written to at least two data centers before it can be considered successful. To accomplish this, we use the following Kafka producer settings:
acks = all
min.insync.replicas = 2The first setting means that a produce must be written to all in-sync replicas before it is considered successful. In the normal case, when all three partition replicas are in sync, the write must go to all three DCs before scheduling is complete. But in the situation where a single data center fails, its two brokers and their replicas will fall out of sync, leaving only two in-sync replicas in two DCs. The second setting means that a produce can still succeed even if only two replicas are in sync. So with these settings our durability requirements are satisfied.
You may also remember that all Kafka reads and writes go to the partition leader. In the case of a single DC failure, we temporarily lose the leaders for a third of our partitions, meaning that we can’t schedule our tasks. This is, however, rectified automatically by Kafka, which rebalances partition leadership to the remaining brokers. All reads and writes resume and go to that new leader.
Below is an illustration of this partition leadership rebalancing. Our example is very similar to the one just described – the only change is a decrease in the number of partitions for clarity. There are three DCs, and two brokers in each one. The single example topic has six partitions. Given Kafka’s rack-aware partitioning, each broker is a leader for a single partition, and a follower for two others.
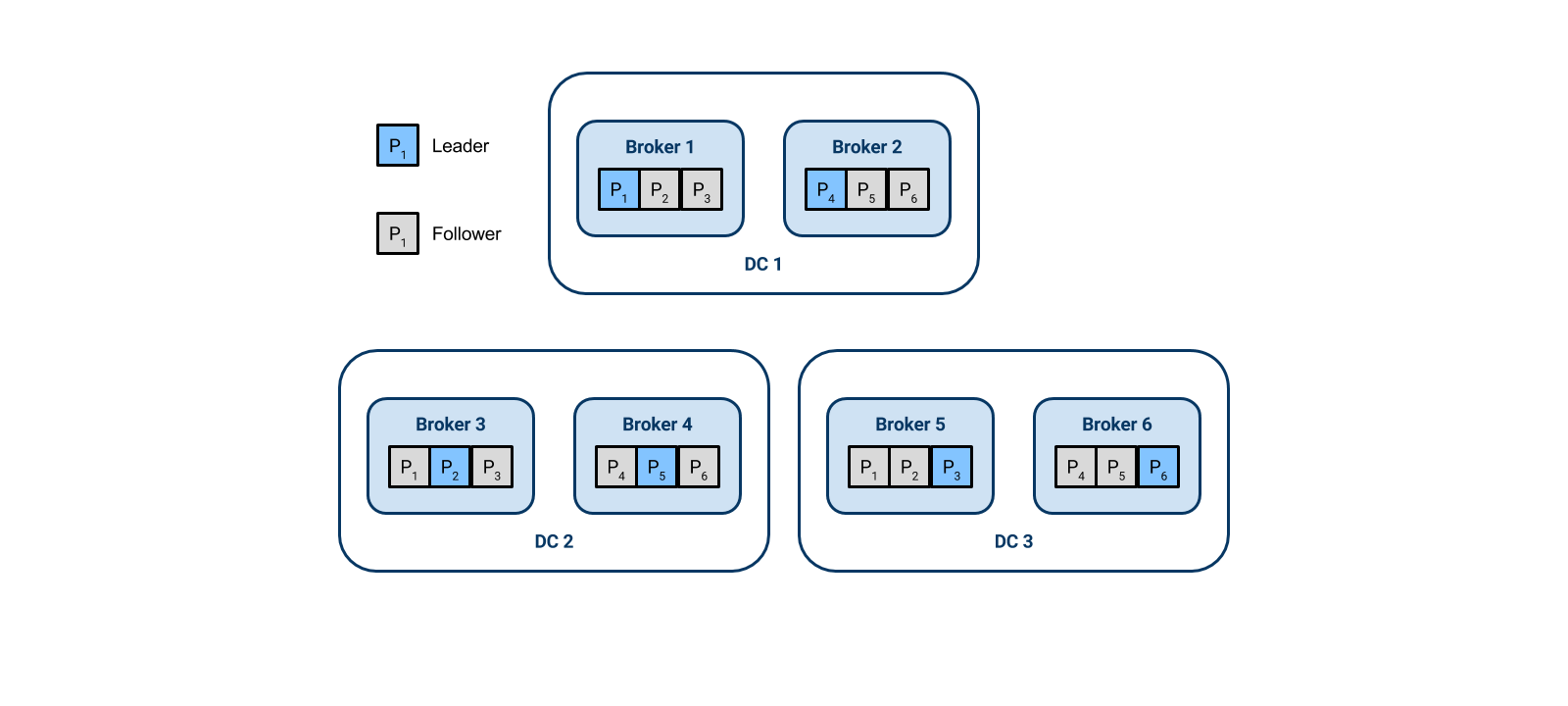
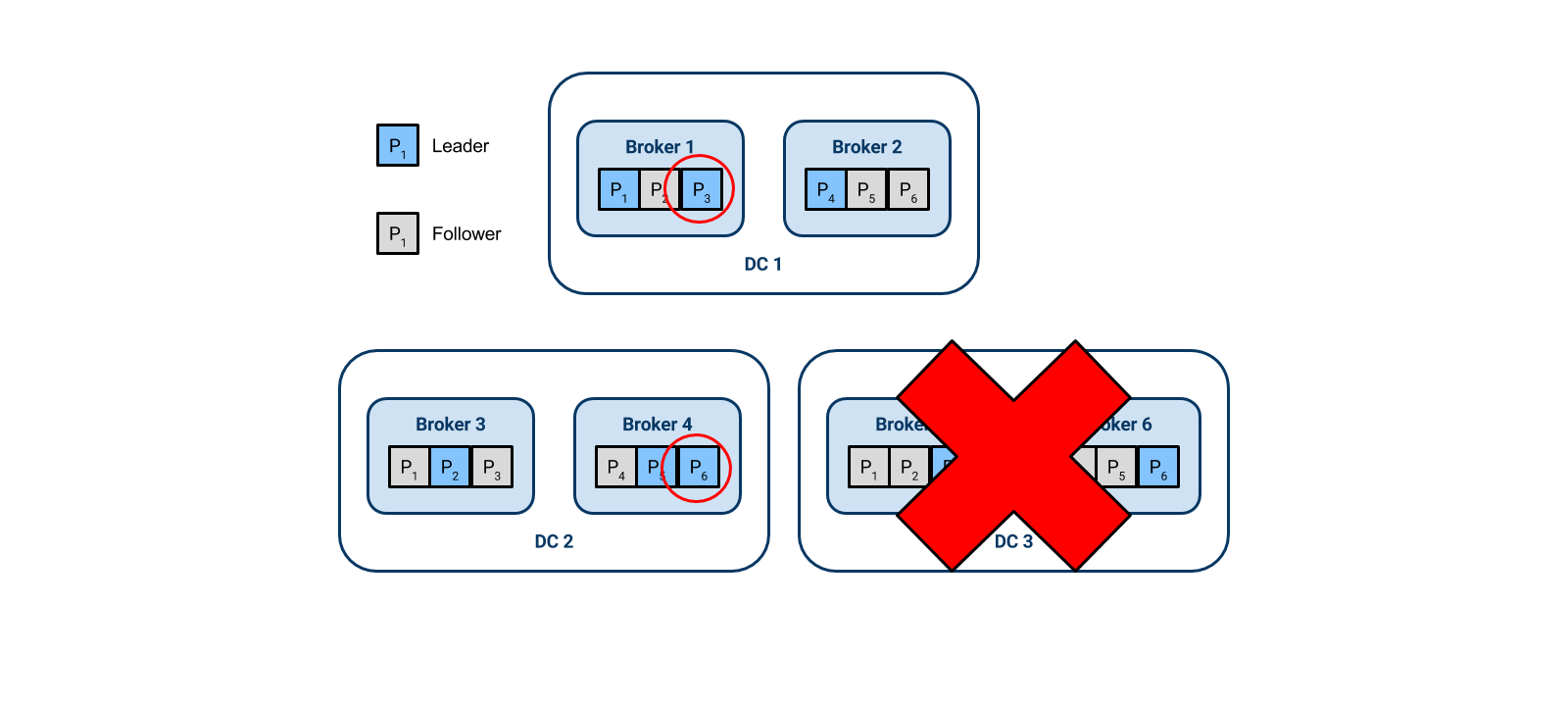
In our failure scenario, DC 3 is lost, so Kafka immediately shifts the partition leadership. Partitions 3 and 6 had a leader in DC 3 which is now gone, so Kafka makes Broker 1 and Broker 4 take on leadership of partitions 3 and 6. The partitions circled in red have changed from being followers to being leaders.
The other thing to note is that we now only have two in-sync replicas for each partition. Since two is the minimum specified in our configuration, writes will still succeed.
Handling Failure in Cassandra
Once tasks are scheduled, they must be persisted durably in a format which can be easily queried. In Scheduler, this functionality is provided by Cassandra.
At PagerDuty, we have configured our Cassandra clusters to deal with the DC-loss failure scenario. Typically, we have five nodes spread evenly across three data centers. With a replication factor of 5, each Cassandra node will eventually get a replica of each row. Again, we want to be very sure that we will not lose data.
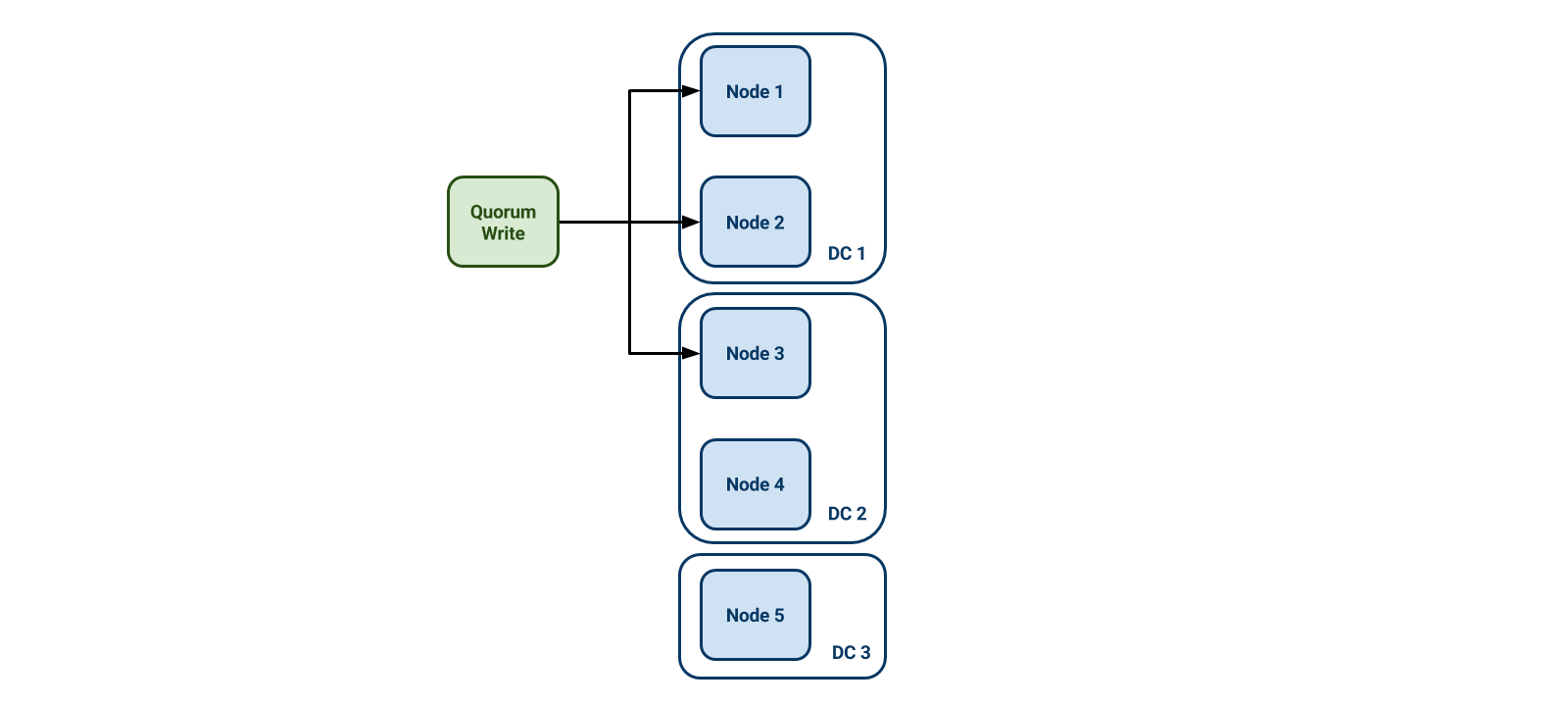
When persisting a task to Cassandra, we do a quorum write, meaning that at least three nodes must acknowledge the write before the driver will return success to the application. With at least three nodes persisting the data, this also means that the data is stored in at least two DCs. Quorum reads ensure that an application will get that latest written value.
The below diagram illustrates a quorum write. In the worst case scenario, where two writes go to nodes in the same DC, there is still a guaranteed write to a node in a second DC.
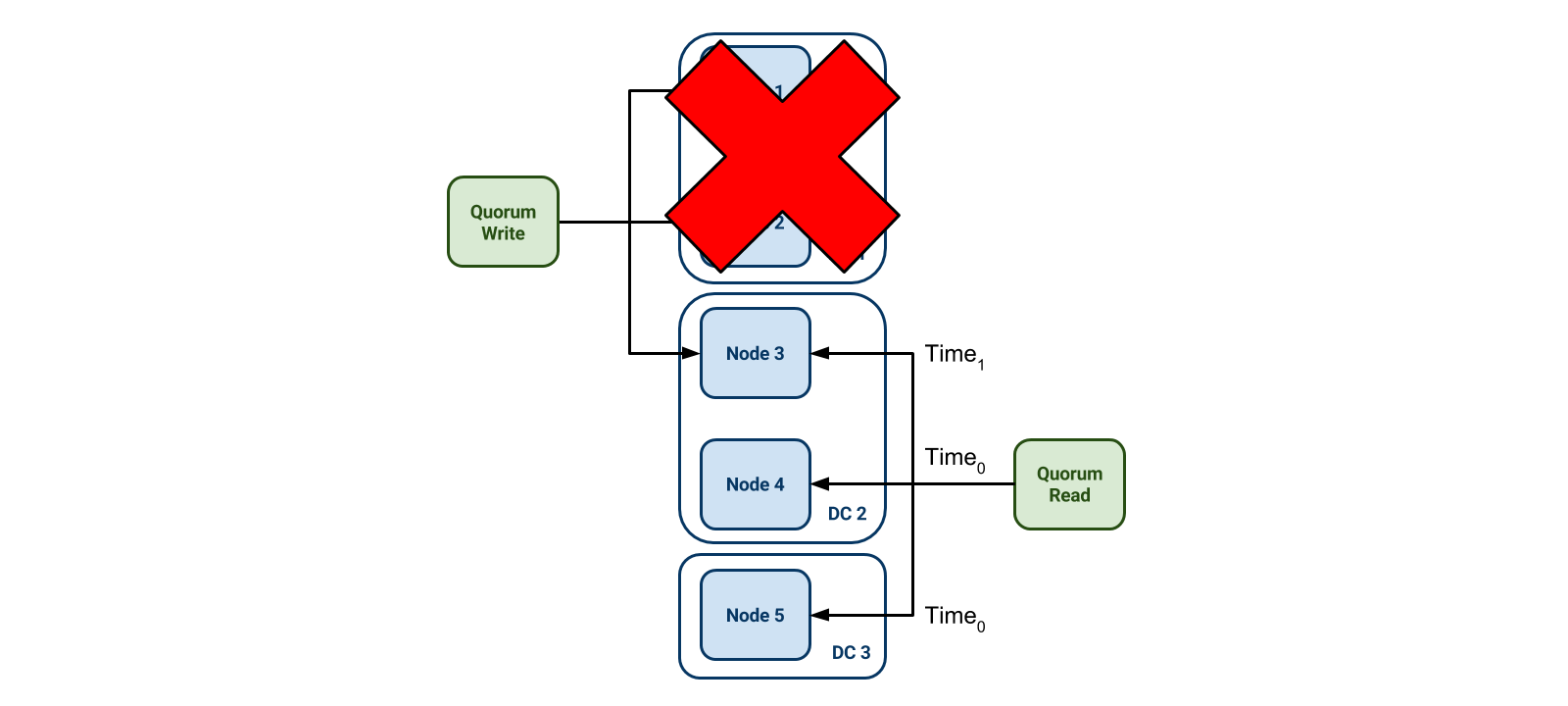
In this example, a worst-case failure scenario is if we lose DC 1, along with two of the nodes that have the updated value. A quorum read requires that three nodes must respond to a query, and of course we still have three remaining nodes. However, nodes 4 and 5 have old values – only node 3 has the new value. Cassandra is a last-write-wins system, which means that the write with the highest timestamp will be returned in the case of conflict. Since clock synchronization can be a difficult problem, Scheduler only writes immutable data to Cassandra, and effectively avoids this conflict situation.
Handling Failure in the Service
By this point, our tasks are durably scheduled and persisted. But what happens to the service itself when a third of its nodes disappear? Kafka again proves to be very helpful to the service in this scenario.
As we have seen in the previous post, Kafka will detect that consumers in the failed DC are no longer healthy. It will re-assign the topic partitions that were being consumed by those service instances to the remaining healthy service instances.
This consumer rebalancing works for three reasons. Firstly, any service instance can work any task – all instances are identical. Secondly, the tasks themselves are idempotent, meaning that if a task is half-way complete when a DC disappears, it can be re-done by another service instance without any harmful side-effects. Lastly, and most obviously, we don’t run our servers at full capacity. We are over-provisioned such that we can lose at least a third of our machines and still handle the load.
The diagram below illustrates a typical setup with three DCs and a service instance in each one. The topic partitions are evenly distributed across the service instances. Notice that in DC 3 the service instance is working Partition 3.
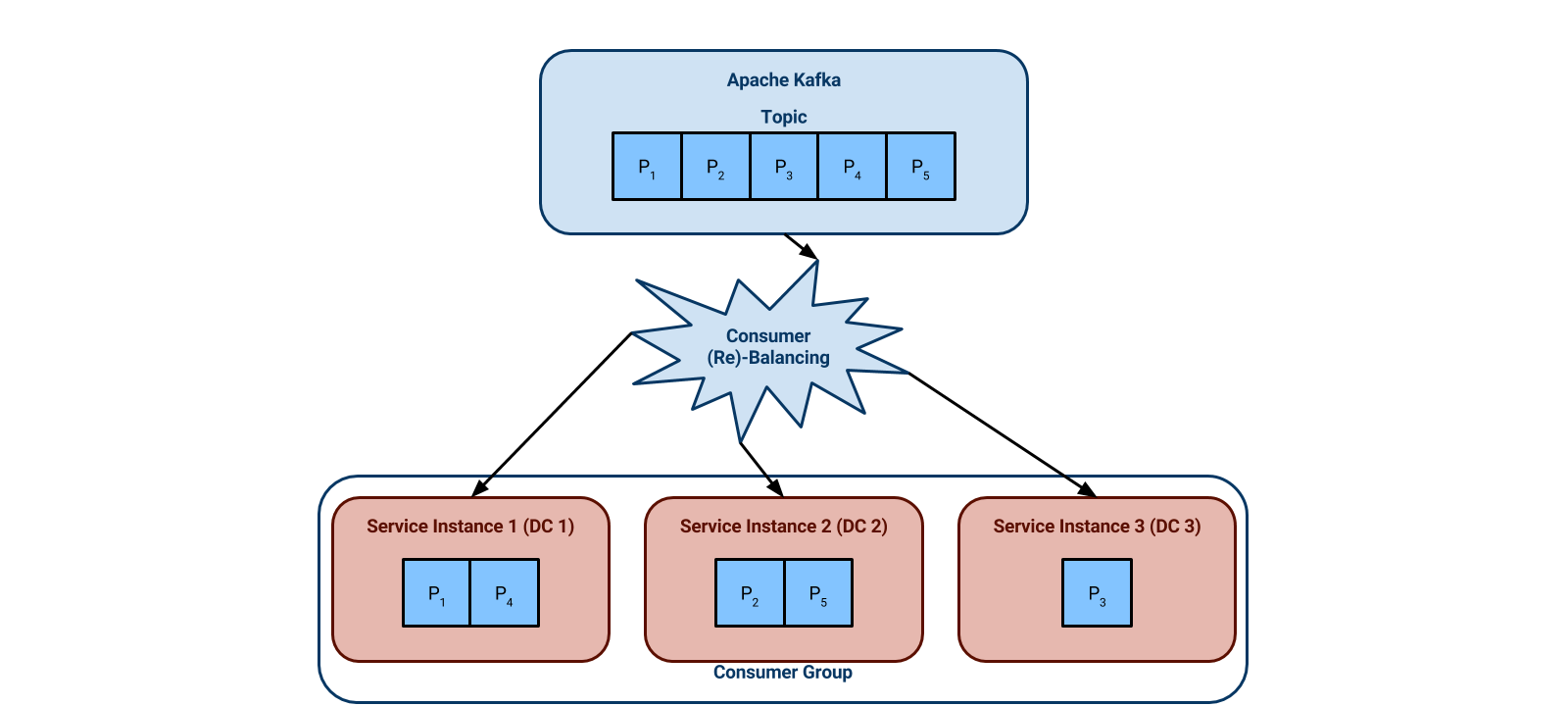
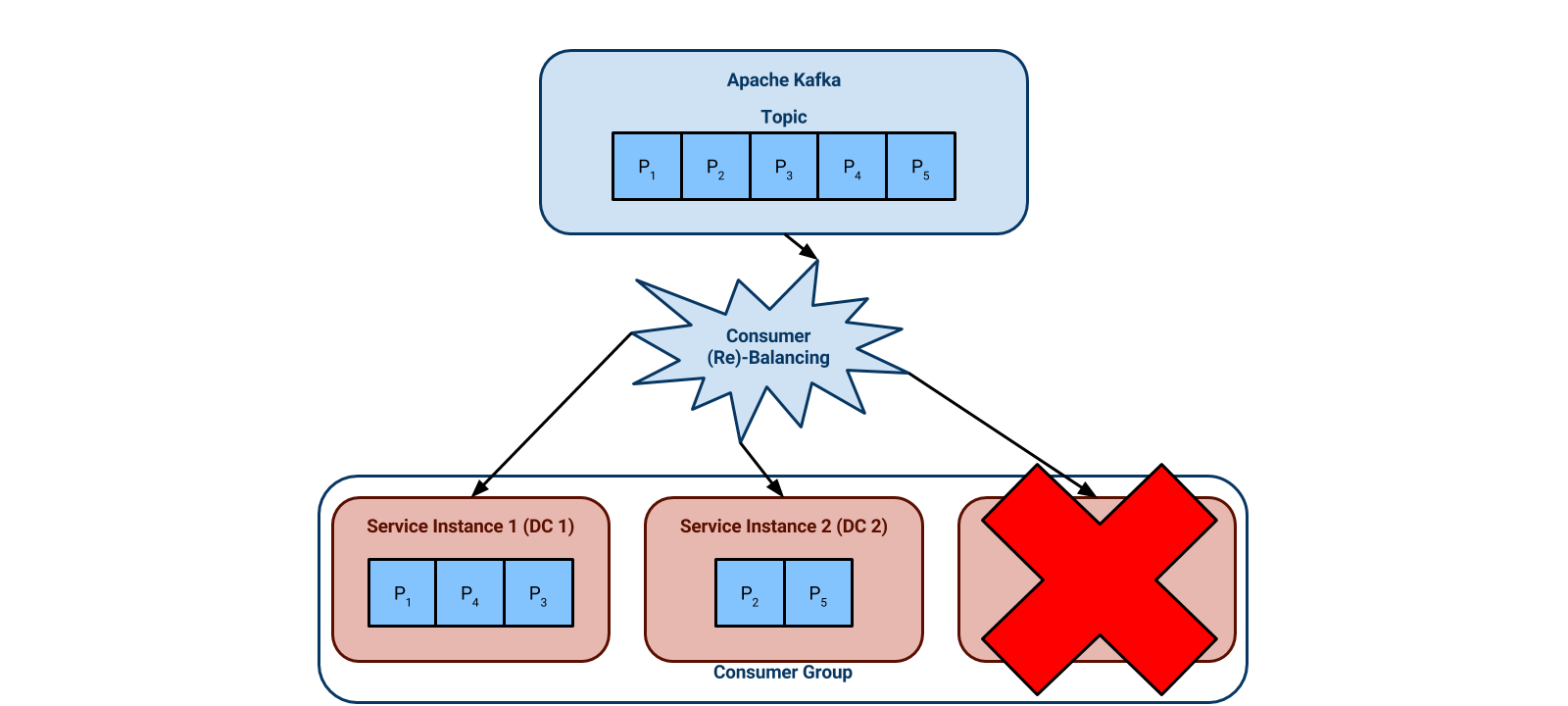
If we lose DC 3, Kafka detects the failure of service instance 3, and re-assigns partition 3 to service instance 1. The system continues to work as expected.
Scheduler Handles Failure by Using Resilient Components
When disaster strikes a DC, we’ve seen how Scheduler handles the failure. Each component that Scheduler relies upon was selected and configured to continue working in this scenario. The remaining Kafka brokers allow new tasks to be scheduled, the remaining Cassandra nodes allow scheduled tasks to be persisted, and the remaining service instances continue to execute all tasks.
Up Next…
We’ve seen how Scheduler can handle dynamic load and data center failures. Tune in next time for a discussion of how we ensure task ordering with Kafka and Akka.
